I used to think that the fine-tuning argument was the strongest argument out there for the existence of a creator deity. I was especially impressed by the apparent magnitude of the fine-tuning – Steven Weinberg has stated that the value of the cosmological constant was fine-tuned to one part in 10120.
If one takes a naïve (and as we’ll see, incorrect) Bayesian approach to assessing this as evidence, then it looks like this should serve as an incredible amount of evidence for the existence of a God, enough to totally overwhelm all other possible considerations. Why? Because if there is a God, then we expect fine-tuning, while if not, then the fine-tuning looks incredibly unlikely. Given this, the God explanation should receive a credence bump proportional to 10120 upon updating on the observation of fine-tuning.
As a quick aside before diving into the numbers, there is a lot of dispute about whether or not there even is fine-tuning in our universe. For the purposes of this post, I’m going to ignore all of these disputes, and pretend that there is a strong consensus on this matter. I’ll use Weinberg’s estimate of 10-120 for the fine-tuning of the cosmological constant. I know that this is controversial, but the point I’m making will stand for even this insanely tiny value.
Okay, so let’s first present a formal version of the fine-tuning argument for God.
F = “The universe is fine-tuned for life.”
G = “A creator deity fine-tuned the universe for life.”
O(G | F) = L(F | G) · O(G)
L(F | G) = P(F | G) / P(F | ~G) ≈ 1 / 10-120 = 1200 dB
So O(G | F) = 10120 · O(G)
This uses the odds formulation of Bayes’ rule – look it up if you’re unfamiliar.
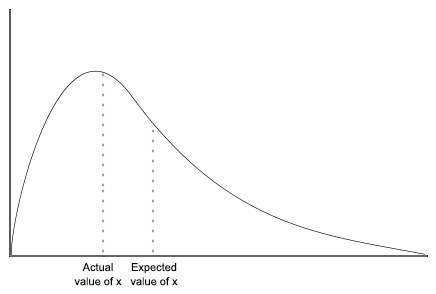
This argument says that your credences should be adjusted by a factor of 10120 upon observing the fine-tuning of the universe. In other words, to not be virtually certain that there exists a creator deity that rules the universe after updating on fine-tuning, you’d have to have initially had a credence on the order of 10-120.
Let me point out that 10-120 is a really really small number. It’s virtually impossible to imagine any good reason why you would be justified in having a prior credence on this order of magnitude. Nobody should be that sure about anything. Evidence of a strength of 1200 dB is analogous in strength to a noise that is a quadrillion times more intense than the threshold of human hearing.
So what’s wrong with this argument? In fact, it fails at the first step. In calculating the strength of the evidence, we only considered two possible hypotheses: either God or, if not, then random coincidence. But there are many other options that we have to factor in as well, most famously the multiverse hypothesis.
But even if there are other hypotheses out there, shouldn’t they just all share the benefit of the credence boost? The existence of another hypothesis that made the same prediction shouldn’t count as a penalty, right?
Wrong! Probabilities have to add up to 1, and you can’t have multiple mutually exclusive competing hypotheses that you have virtual certainty about. Whatever happens when you add other hypotheses must be more subtle than that. So let’s calculate using Bayes’ rule!
O(T | E) = L(E | T) · O(T)
L(E | T) = P(E | T) / P(E | ~T)
For each theory T we consider, we have to take into account all other theories in the denominator of our likelihood function L. We’ll want to keep in mind the following identity:
P(B & C) = 0
implies
P(A | B or C) = [P(A | B) P(B) + P(A | C) P(C)] / [P(B) + P(C)]
So, for instance, let’s divide up our explanations of the fine-tuning F into three disjoint categories: (1) random coincidence C, (2) a deistic God G, and (3) all other explanations that are mutually incompatible.
L(F | X) = P(F | X) / P(F | ~X)
= P(F | X) (1 – P(X)) / ∑Y≠PP(F | Y) P(Y)
P(F | C) ≈ 10-120
P(F | G) ≈ 1
P(F | O) ≈ 1
L(F | C) ≈ 10-120
L(F | G) ≈ P(~G) / P(O)
L(F | O) ≈ P(~O) / P(G)
O(C | F) = 10-120 · O(C)
O(G | F) = P(G) / P(O)
O(O | F) = P(O) / P(G)
In the end, what we find is that the “Coincidence” hypothesis has been down-voted completely out of existence, leaving only the “God” hypothesis and the “Other” hypothesis.
And importantly, our final credence in either of these hypotheses is not on the order of magnitude of 1 – 10-120. The final balance depends entirely just on the ratio of prior credences in the two explanations.
Trial Run
Let’s look at two individuals updating on the observation of fine-tuning.
Atheist
P(G) = .01%
P(O) = 50%
Deist
P(G) = 99%
P(O) = 1%
(The exact details of these numbers aren’t that important, just that they’re somewhat qualitatively accurate.) Their final credences will be:
Atheist
P(G | F) = 0.02%
P(O | F) = 99.98%
Deist
P(G | F) = 99%
P(O | F) = 1%
And we see that nobody ends up significantly updating their religious beliefs on the evidence of fine-tuning. The deist held a worldview in which the random coincidence hypothesis was already ruled out, so the observation of fine-tuning doesn’t change anything for them. And the atheists were initially fairly agnostic about whether or not the universe was fine-tuned, but were very confident in the existence of other explanations besides God. As such, the observation of fine-tuning served as a minor increase in their belief in God (+.01%), while they become extremely confident that there must be some other explanation.
Fine-tuning would only serve as strong evidence for you if you were initially very sure that there was a God, but agnostic about if God would have designed the universe to accommodate human life, or if its design was purely random coincidence. Even in this case, the bump in credence you’d receive would be nothing like the massive update that seems apparent from a naïve (and wrong) application of Bayesian reasoning.