I used to think of Bayesianism as composed of two distinct parts: (1) setting priors and (2) updating by conditionalizing. In my mind, this second part was the crown jewel of Bayesian epistemology, while the first part was a little more philosophically problematic. Conditionalization tells you that for any prior distribution you might have, there is a unique rational set of new credences that you should adopt upon receiving evidence, and tells you how to get it. As to what the right priors are, well, that’s a different story. But we can at least set aside worries about priors with assurances about how even a bad prior will eventually be made up for in the long run after receiving enough evidence.
But now I’m realizing that this framing is pretty far off. It turns out that there aren’t really two independent processes going on, just one (and the philosophically problematic one at that): prior-setting. Your prior fully determines what happens when you update by conditionalization on any future evidence you receive. And the set of priors consistent with the probability axioms is large enough that it allows for this updating process to be extremely irrational.
I’ll illustrate what I’m talking about with an example.
Let’s imagine a really simple universe of discourse, consisting of just two objects and one predicate. We’ll make our predicate “is green” and denote objects 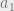

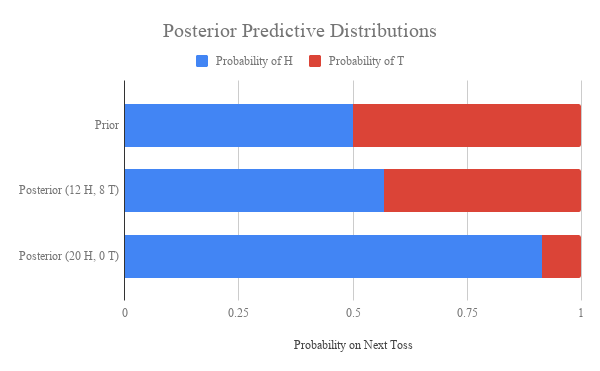
Let’s imagine that we start out knowing nothing (i.e. our starting credences are identical to the hypothetical prior) and then learn that one of the objects (
No! Some priors will allow induction to happen, but others will make you unresponsive to evidence. Still others will make you anti-inductive, becoming more and more confident that the next object is not green the more green things you observe. And all of this is perfectly consistent with the laws of probability theory!
Take a look at the following three possible prior distributions over our simple language:

According to 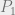
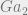


For 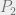
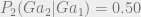
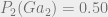
And finally, 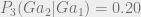
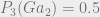
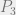
The anti-inductive prior can be made even more stark by just increasing the gap between the prior probability of 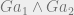
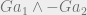
Our universe of discourse here was very simple (one predicate and two objects). But the point generalizes. Regardless of how many objects and predicates there are in your language, you can have non-inductive or anti-inductive priors. And it isn’t even the case that there are fewer anti-inductive priors than inductive priors!
The deeper point here is that the prior is doing all the epistemic work. Your prior isn’t just an initial credence distribution over possible hypotheses, it also dictates how you will respond to any possible evidence you might receive. That’s why it’s a mistake to think of prior-setting and updating-by-conditionalization as two distinct processes. The results of updating by conditionalization are determined entirely by the form of your prior!
This really emphasizes the importance of having good criterion for setting priors. If we’re trying to formalize scientific inquiry, it’s really important to make sure our formalism rules out the possibility of anti-induction. But this just amounts to requiring rational agents to have constraints on their priors that go above and beyond the probability axioms!
What are these constraints? Do they select one unique best prior? The challenge is that actually finding a uniquely rationally justifiable prior is really hard. Carnap tried a bunch of different techniques for generating such a prior and was unsatisfied with all of them, and there isn’t any real consensus on what exactly this unique prior would be. Even worse, all such suggestions seem to end up being hostage to problems of language dependence – that is, that the “uniquely best prior” changes when you make an arbitrary translation from your language into a different language.
It looks to me like our best option is to abandon the idea of a single best prior (and with it, the notion that rational agents with the same total evidence can’t disagree). This doesn’t have to lead to total epistemic anarchy, where all beliefs are just as rational as all others. Instead, we can place constraints on the set of rationally permissible priors that prohibit things like anti-induction. While identifying a set of constraints seems like a tough task, it seems much more feasible than the task of justifying objective Bayesianism.