Recently I told a friend that I thought ZFC was one of humankind’s greatest inventions. He pointed out that it was pretty bold to claim this about something that most of mankind has never heard of, which I thought was a fair objection. After thinking for a bit, I reflected that the sense of greatness I meant wasn’t really consequentialist, and thus it was independent of how many people know what ZFC is, or even how many people’s lives are affected in any way by it. Instead I intended greatness in a sort of aesthetic and intellectual sense.
The closest analogy to ZFC outside of math is the idea of a “theory of everything” for physics. If we found a theory of everything for physics, it’d likely have a bunch of important practical consequences, and that’d be part of what makes it a great invention. But it would also be a great invention in an intellectual sense, as a discovery of something fundamental and unifying of many seemingly disparate phenomena we observe. This is what ZFC is like: a mathematical theory of everything. One reason this analogy is imperfect is that due to the incompleteness theorems, we know that there can be no “theory of everything” for mathematics. (Any theory of everything will have at least one thing it can’t prove, namely its own consistency.) So ZFC’s greatness can’t come from being a perfect theory of everything, because we know that it is not. Nonetheless, ZFC serves as a foundation for virtually all known mathematics, and this is what I think is so incredible about it.
What does it mean for something to “serve as a foundation” for math? ZFC is a foundation in (at least) three ways: (1) in terms of its ability to define virtually all mathematical concepts, (2) in terms of its structures being rich enough to contain objects that come from virtually all fields of math, and (3) in terms of being an axiom system that suffices to prove virtually every result in known mathematics.
Syntax
Virtually every mathematical concept you can think of has a definition in the language of ZFC. For example, we have definitions for numbers like “π” and “√2”, sets like ℕ and ℝ, algebraic objects like the group S5 and the ring ℚ[x], geometric objects like Platonic solids and differential manifolds, computational objects like Turing machines and cellular automata, and even logical entities like models of first order theories and proofs within formal systems. What makes this especially impressive is the simplicity of the language: it uses nothing besides the basic symbols of first order logic and one binary relation symbol: ∈. So one thing that ZFC teaches us is that virtually every concept in mathematics can be defined just in terms of the set membership relation, and all mathematics can be understood as exploring the properties of this relation.
Semantics
Models of ZFC are insanely richly structured. You can navigate within them to find sets corresponding to every object that mathematicians study. π has a representative set within any model of ZFC, as does the Monster group or the torus. These representative sets are not always perfect: there are models of ZFC where ℝ is countable, for instance. But within the model, they nonetheless share enough similarities with the original objects that virtually everything you can prove about the original object, remains true of the ZFC-representative.
Proof
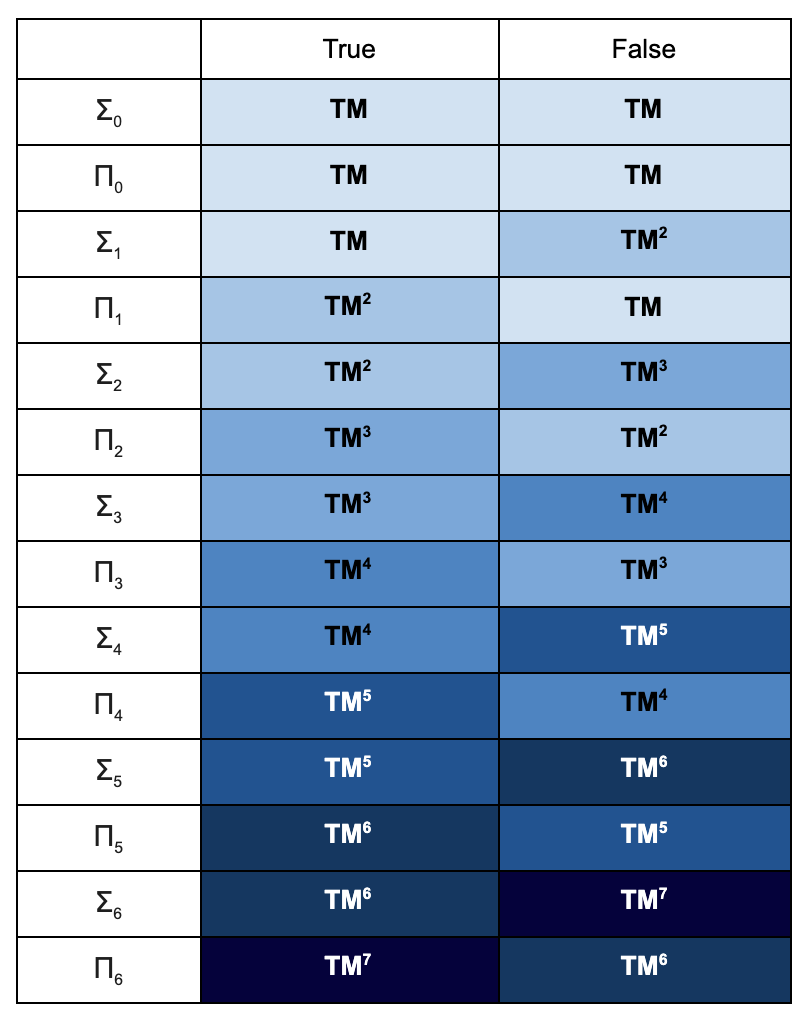
Finally, ZFC is a computable set of sentences, and we may inquire about what can be proven from it. Keeping up the ambition of the previous two sections, we might want to claim that all mathematical truths can be proven from ZFC. But due to the limitations of first order logic discovered over the last century, we now know that this goal is not achievable. The set of all first order truths of arithmetic is not computable, and so there must be some such truths that aren’t logical consequences of ZFC. Nonetheless, it is commonly claimed that virtually all mathematical truths can be derived from ZFC using the usual proof system for first order logic.
This is especially remarkable given the simplicity of ZFC. I believe that the intuitive content of each axiom could be explained to a smart middle schooler. Additionally, these axioms are extremely intuitively appealing. the most controversial of them has been choice, which is equivalent to the statement that the Cartesian product of non-empty sets is also non-empty. Second most controversial is probably the axiom of infinity, which just says that there’s an infinite set. The rest are even less hard to accept than these.
Now, the fact that you can prove virtually everything from ZFC doesn’t mean that you should. So don’t interpret me as saying that ZFC is of practical use to the daily work of mathematicians trying to prove things outside of set theory and logic. Again, an analogy to physics: we might discover a theory of everything that we know reproduces all the known phenomena of GR and QM, but find that it’s so hard to prove things that we are practically never better off using this theory to calculate things. Nonetheless, ZFC as a theory of everything teaches us that most of math can be understood as conceptually quite simple: the logical consequences of a fairly simple and computable set of sentences about sets. People make a big deal out of Euclid’s axiomatization of geometry, but this is a small feat relative to the axiomatization of all of mathematics.
Metamath
And not only can ZFC prove virtually everything in ordinary mathematics, but ZFC can prove much of what we know in metamathematics and logic itself. When logicians are studying model theory, or even when set theorists are studying ZFC, they are almost always working with ZFC as their meta-theory, meaning that they are making sure that all of their proofs could ultimately be expanded out as ZFC proofs. So the big results of logic, like the completeness theorem, the compactness theorem, the incompleteness theorems, the Löwenheim-Skolem theorems, are all theorems of ZFC.
The fact that ZFC can even talk about these model theoretic notions means that models of ZFC are able to talk about models of ZFC, which is where things get very meta. One can prove that every model of ZFC – every one of these crazily richly-structured universes containing virtually all of mathematics – contains another such model of ZFC. This follows from the reflection theorem, which again can be proven in ZFC!
Hopefully I have now roused enough interest in you to get you to take a look at some of the actual mathematics. You might be curious to know what exactly this theory is. And you’re in luck, it’s simple enough that I can write the whole theory in just nine lines!
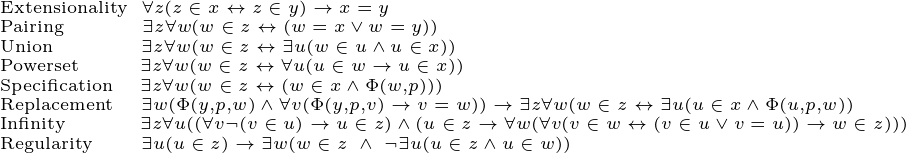
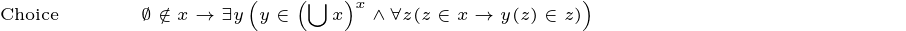
Note that with the exception of the final axiom, Choice, the only symbols I’ve used are logical symbols and ∈. I used shorthand for Choice for the sake of readability, but this could be expanded out just like the others. I’m also using a convention where any free variables are considered to be universally quantified over, which shortens things further.
I’ll close with a one-sentence description for each axiom.
Extensionality: No two distinct sets have all the same elements.
Pairing: For any two sets, there’s a set containing just those two.
Union: The union of any set of sets exists.
Powerset: There is a set of all subsets of any set.
Specification: For any property Φ and any set x, you can form a set out of just those elements of x with that property.
Replacement: For any definable function and any set, the image of that set under the function exists.
Infinity: There’s an infinite set.
Regularity: Every non-empty set has a member that it shares nothing with.
Choice: For any set of nonempty sets, there is a function that picks out one element from each.
The fact that you can prove everything from the infinitude of primes to Fermat’s Last Theorem from just these basic principles, is really quite mind-blowing.