Today I want to talk about ordinal numbers in ZFC set theory. VSauce does a great job introducing his viewers to the concepts of ordinal vs cardinal numbers, and giving a glimpse into the weird and wild world of mathematical infinity. I want to go a bit deeper, and show exactly how the ordinals are constructed in ZFC. Let’s begin!
Okay, so first of all, we’re talking about first-order ZFC, which is an axiomatic formalization of set theory in first-order logic. As a quick reminder, first order logic gives us access to the following alphabet of symbols: ( ) , ∧ ∨ ¬ → ↔ ∀ ∃ =, as well as an infinite store of variables (x, y, z, w, v, u, and so on). A first order language also includes a store of constant symbols, relation symbols, and function symbols.
For first-order set theory, we are going to add only a single extra-logical symbol to our alphabet: the “is-an-element-of” relation ∈. This is pretty remarkable when you consider that almost all of mathematics can be done with just ZFC! In some sense, you can give a pretty good description of mathematics as the study of the elementhood relation! Using just ∈ we can define everything we need, from ⊆ and ⋃ and ⋂ to the empty set ∅ and the power set function P(x). In fact, as we’ll see, we’re even going to define numbers using ∈!
The elementhood relation ∈ is given its intended meaning by the axiom of extensionality: ∀x∀y (x=y ↔ ∀z (z∈x ↔ z∈y)). In plain English this says that two sets are the same exactly when they have all the same elements.
The semantics of first order logic has two parts: a “universe” of individuals that are quantified over by ∀ and ∃, and an interpretation of each of the constant symbols (as individual objects in the universe), the relation symbols (as maps from the universe to truth values), and the function symbols (as maps from the universe to itself).
Our universe is going to be entirely composed of sets. This means that sets won’t be composed of non-set elements; the elements of non-empty sets are always themselves sets. And those sets themselves, if non-empty, are made out of sets. It’s sets all the way down!
Now, the topic of this essay is ordinal numbers in ZFC. So if everything in ZFC is a set, guess what ordinal numbers will be? You got it, sets! What sets? We can translate from ordinals to sets in a few words: the ordinal 0 is translated as the empty set, and every other ordinal is translated as the set of all smaller ordinals.
This tells us that 1 = {0}, 2 = {0, 1}, 3 = {0, 1, 2}, and so on. If we were to write these ordinals entirely in set notation, it would look like: ∅, {∅}, {∅,{∅}}, {∅,{∅},{∅,{∅}}}, and so on. The choice to associate these particular sets with the natural numbers is a convention introduced by John Von Neumann (it is, however, an exceedingly wise convention, and has many virtues that competing conventions do not have, as will become clearer once we ascend to the transfinite).
So, now we know that we are going to associate the finite ordinals with the empty set and supersets of the empty set. But of course, we haven’t yet even shown that the empty set exists in ZFC! To actually construct the empty set in ZFC, we have to add some more axioms. Let’s start with the obvious one: a sentence that asserts the existence of the empty set:
Axiom of Empty Set: ∃x∀y ¬(y∈x)
In other words, there’s some set x that contains no sets. Notice that we didn’t refer to the empty set by name. We can’t refer to it by name in our axioms, because we haven’t included any constant symbols in our language! To actually talk about the particular set ∅ (equivalently, 0), we can use the rule of existential instantiation, which allows us to remove any existential quantifier, as long as we change the name of the quantified variable to something that has not been previously used. So, for example, in any particular proof, we can do the following:
1. ∃x∀y ¬(y∈x) (Axiom of Empty Set)
2. ∀y ¬(y∈0) (from 1 by existential instantiation)
This is allowed so long as the symbol 0 has not appeared anywhere previously in the proof.
Now that we have the empty set, we need to be able to construct 1={0} and 2={0,1}. To do this, we introduce the axiom of pairing:
Axiom of Pairing: ∀x∀y∃z∀w (w∈z ↔ (w=x ∨ w=y))
This says that we can take any two sets x and y and form a new set z = {x, y}. We can right away use this axiom to construct the number 1.
3. ∀x∀y∃z∀w (w∈z ↔ (w=x ∨ w=y)) (Axiom of Pairing)
4. ∃z∀w (w∈z ↔ (w=0 ∨ w=0)) (from 3 by universal instantiation)
5. ∀w (w∈1 ↔ (w=0 ∨ w=0)) (from 4 by existential instantiation)
6. ∀w (w∈1 ↔ w=0)
We went from 3 to 4 by using universal instantiation (instantiating both variables x and y as 0), and from 4 to 5 by using existential instantiation (instantiating z as 1, which is allowed because we haven’t used the symbol 1 yet). The step from 5 to 6 is technically skipping a bunch of steps. Even though it’s obvious that we can replace (w=0 ∨ w=0) with w=0 inside the formula, there isn’t any particular rule of inference in first order logic that does it in one step. But since it is obvious that 5 semantically entails 6, and since first order logic has a sound and complete proof system, we know that 5 also syntactically entails 6.
To construct 2, we can simply use pairing again with 0 and 1:
7. ∃z∀w (w∈z ↔ (w=0 ∨ w=1)) (from 3 by universal instantiation)
8. ∀w (w∈2 ↔ (w=0 ∨ w=1)) (from 4 by existential instantiation)
We might think that we could simply use pairing once more to get 3 = {0,1,2}. But this won’t quite work. If we use pairing on 1 and 2 we get {1,2}, and if we use pairing again on this and 0 we get {0,{1,2}}, not {0,1,2}. In fact, we can easily see that any usage of pairing always produces a set with exactly two elements. And the set 3 has three elements! So pairing is not enough to get us where we want to go. To get to 3, we need a stronger axiom, which will allow us to take the union of sets.
Axiom of Union: ∀x∃y∀z (z∈y ↔ ∃w(z∈w ∧ w∈x))
This says that for any set x, we can construct a new set y which consists of the union of all sets in x. In other words, if z is an element of y, then z must be contained in some set w that’s an element of x.
Now, here’s how we’re going to construct 3. First we construct the set {2} by pairing 2 with itself. Then we construct the set {2,{2}} with pairing again. Then we union all the elements of this set to get 2⋃{2}. Now remember that 2 = {0,1}, so 2⋃{2} = {0,1}⋃{2} = {0,1,2}. And that’s 3!
Constructing {2}:
9. ∃z∀w (w∈z ↔ (w=2 ∨ w=2)) (from 3 by universal instantiation)
10. ∀w (w∈{2} ↔ (w=2 ∨ w=2)) (from 9 by existential instantiation)
11. ∀w (w∈{2} ↔ w=2)
Constructing {2,{2}}:
12. ∃z∀w (w∈z ↔ (w=2 ∨ w={2})) (from 3 by universal instantiation)
13. ∀w (w∈{2,{2}} ↔ (w=2 ∨ w={2})) (from 12 by existential instantiation)
Constructing 3:
14. ∀x∃y∀z (z∈y ↔ ∃w(z∈w ∧ w∈x)) (Axiom of Union)
15. ∃y∀z (z∈y ↔ ∃w(z∈w ∧ w∈{2,{2}})) (from 9 by universal instantiation)
16. ∀z (z∈3 ↔ ∃w(z∈w ∧ w∈{2,{2}})) (from 10 by existential instantiation)
Technically, we’ve now constructed 3. But let’s neaten this up and show that this set is really what we wanted (using more of the intuitive semantic arguments from before to skip many tedious steps).
17. ∀z (z∈3 ↔ ∃w(z∈w ∧ (w=2 ∨ w={2}))) (from 13,16)
18. ∀z (z∈3 ↔ ∃w((z∈w ∧ w=2) ∨ (z∈w ∧ w = {2})))
19. ∀z (z∈3 ↔ (z∈2 ∨ z∈{2}))
20. ∀z (z∈3 ↔ (z∈2 ∨ z=2)) (from 11,19)
21. ∀z (z∈3 ↔ (z=0 ∨ z=1 ∨ z=2)) (from 8,20)
We can construct 4 in pretty much the exact same way: first use pairing to construct {3} and then {3,{3}}, and then use union to construct 3⋃{3} = {0,1,2}⋃{3} = {0,1,2,3} = 4. I’ll go through this all formally one more time, more quickly than before:
22. ∀w (w∈{3} ↔ w=3) (pair 3 with 3)
23. ∀w (w∈{3,{3}} ↔ (w=3 ∨ w={3})) (pair 3 with {3})
24. ∀z (z∈4 ↔ ∃w(z∈w ∧ w∈{3,{3}})) (union {3,{3}})
25. ∀z (z∈4 ↔ (z=0 ∨ z=1 ∨ z=2 ∨ z=3)) (neatening up)
It should be clear that this process can continue indefinitely. From the ordinal 4 we can construct 5 by taking the union of 4 and {4}, and from 5 we can construct 6 = 5⋃{5}. And so on. In fact, we can define the successor of any set x as exactly the set x⋃{x}: S(x) = x⋃{x}. And using the above construction, we know that this successor set will always exist!
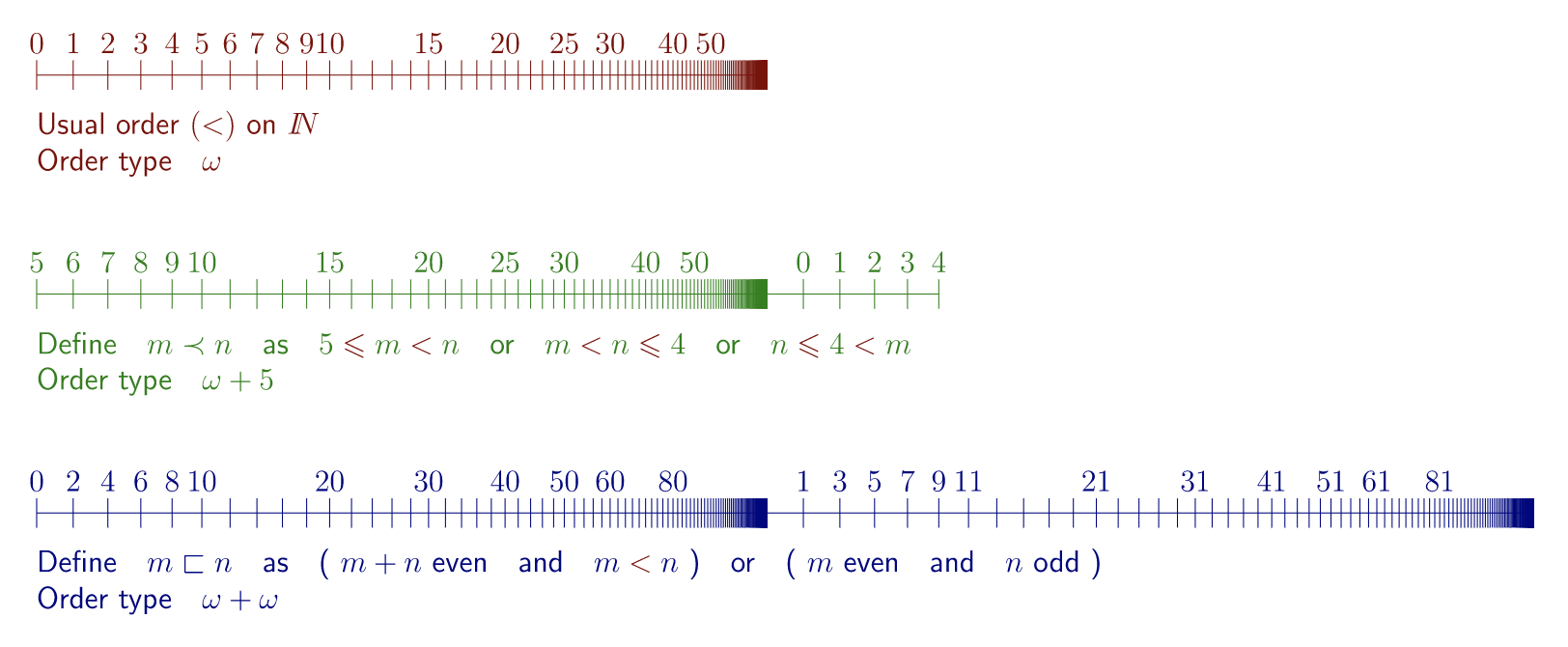
Wonderful! So now we have an outline for the construction of every natural number. What’s next? What comes after 0, 1, 2, 3, 4, and so on? The first infinite ordinal, ω! Just as 4 is the set {0,1,2,3}, and 10 is the set of all the ordinals before it, ω is defined as exactly the set of all previous ordinals. In other words, ω is the set of all natural numbers! ω = {0,1,2,3,…}.
Now, how can we construct ω in ZFC? Can we do it using the axioms we have so far? You might be tempted to say something like “Sure! You’ve just demonstrated a process that constructs n+1 from any n, and we know how to construct 0 already. So don’t we already have the ability to construct all the natural numbers?”
Well, hypothetical you, it’s true that we now know how to construct each natural number. But constructing the infinite set containing all natural numbers is an entirely different matter. Remember that proofs are only allowed to be finitely long! So in any proof using only the methods we’ve used so far, we can only construct finitely many natural numbers (proportional to the length of the proof). To get ω, we need something more than the axioms we have so far. Introducing: the axiom of infinity!
But before we get there, I want to construct a handy bit of shorthand which will make what comes next a lot easier to swallow. What we’ll do is write out as a first-order sentence the assertion “x is the successor of y”, as well as the sentence “x is the empty set”, and then introduce a shorthand notation for them. Trust me, it will make life a lot easier.
First, “x is the successor of y”, which we can also write as “x = y⋃{y}”. Try this for yourself before reading on! Ok, now that you’re back, here it is: ∀z (z∈x ↔ (z∈y ∨ z=y)). We’ll call this sentence Succ(x,y). So if you ever see “Succ(x,y)” in the future, read it as “x is the successor of y” and know that if we wanted to be fully formal about it we could replace it with “∀z (z∈x ↔ (z∈y ∨ z=y))”.
Good! Now, let’s do the same with the sentence “x is the empty set”, which is the same thing as “x is 0”. Try it for yourself! And now, here it is: ∀y ¬(y∈x). We’ll call this sentence isZero(x).
Now we’re ready for the axiom of infinity!
Axiom of Infinity: ∃x∀y ((isZero(y) → y∈x) ∧ (y∈x → ∃z (Succ(z,y) ∧ z∈x)))
If this axiom looks like a lot to comprehend, imagine it without our shorthand! Conceptually, what’s going on with this axiom is actually pretty simple. We’re just asserting that there exists an infinite set x that contains 0, and that is closed under the successor operation. So this set is guaranteed to contain 0, as well as the successor of 0 (1), and the successor of the successor of 0 (2), and the successor of this (3), and so on forever. (Bonus question: what does the set theoretic universe look like if we remove the axiom of infinity and add its negation as an axiom instead? What mathematical structure is it isomorphic to?)
Quiz question for you: have we now constructed ω? That is, the axiom of of infinity does guarantee us the existence of a set, but are we sure that that set is exactly the set of natural numbers and nothing more?
The answer is no. The axiom of infinity does guarantee us the existence of an infinite set, and we know for sure that this set contains all the natural numbers, but there’s nothing guaranteeing that it doesn’t also contain other sets! To actually obtain ω, we need one more axiom. This axiom will be the most powerful one we’ve seen yet: the axiom of comprehension.
Axiom of Comprehension: ∀x∃y∀z (z∈y ↔ (z∈x ∧ φ(z)))
This tells us that for any set x, we can construct a new set y, which consists of exactly the elements of x that have a certain property φ. In set-builder notation, we can write: y = {z∈x: φ(z)}. (Bonus question: why do we have to define y as the subset of x that satisfies φ? Why not just say that there exists a set of all sets that satisfy φ? This unrestricted comprehension axiom appeared in the early formalizations of set theory, but there was a big problem with it. What was it?)
You may notice that there’s something different about this axiom than the previous ones. What’s up with that symbol φ(z)? Well, φ(z) is a stand-in for any well-formed formula in the language of ZFC, so long as φ contains only z as a free variable. What that means is that there’s actually not one single axiom of comprehension, but a countably infinite axiom schema, one for each well-formed formula φ.
For instance, we have as one instance of the axiom of comprehension that ∀x∃y∀z (z∈y ↔ (z∈x ∧ z=z)). As another instance of the axiom, we have ∀x∃y∀z (z∈y ↔ (z∈x ∧ z≠z)). Both of these are pretty trivial examples: in the first case the set y is exactly the same as x (as all sets are self-identical), and in the second case y is the empty set (as no set z satisfies the property z ≠ z). But we can do the same thing for any property whatsoever, so long as it can be encoded in a sentence of first-order ZFC. (Another bonus question: One of the axioms I’ve mentioned before has now been obviated by the introduction of these new axioms. Can you figure out which it is, and produce its derivation?)
We use the axiom of comprehension to “carve ω out” from the set whose existence is guaranteed by the axiom of infinity (remember, we already know for sure that this set contains all the natural numbers, it’s just that it might contain more elements as well). So what we need is to construct a sentence φ(z) such that the only set z that satisfies the sentence is the set of all natural numbers ω.
There are several such sentences. I’ll briefly present one simple one here. Again we’ll introduce a convenient shorthand for the sake of sanity. Take a look at this sentence that we saw earlier: “∀y ((isZero(y) → y∈x) ∧ (y∈x → ∃z (Succ(z,y) ∧ z∈x)))”. What this sentence says is that x is a superset of ω (it contains 0 and is closed under successorhood). So we’ll call this sentence “hasAllNaturals(x)”.
Now, we can write the following sentence: ∀x (hasAllNaturals(x) → z∈x).
Consider what this sentence says. It tells us that z is an element of every set that contains all the naturals. But one such set is the smallest set containing all the naturals, i.e. ω! So z must be an element of ω. In other words, z is a natural number. So this sentence will do for our definition of φ(z).
φ(z): ∀x (hasAllNaturals(x) → z∈x)
Just like with hasAllNaturals(z) and Succ(x,y) and isZero(x), you should read φ(z) as simply a shorthand for the above sentence. If we really wanted to torture ourselves with formality, we could write out the entire sentence using only the allowed symbols of first-order ZFC.
Now we can finally get ω. Let’s continue with our proof progression from earlier. We left off at 25, so:
26. ∃x∀y ((isZero(y) → y∈x) ∧ (y∈x → ∃z (Succ(z,y) ∧ z∈x))) (Axiom of Infinity)
27. ∀y ((isZero(y) → y∈inf) ∧ (y∈inf → ∃z (Succ(z,y) ∧ z∈inf)))
28. ∀x∃y∀z (z∈y ↔ (z∈x ∧ φ(z))) (Axiom of Comprehension)
29. ∃y∀z (z∈y ↔ (z∈inf ∧ φ(z)))
30. ∀z (z∈ω ↔ (z∈inf ∧ φ(z)))
In going from line 26 to 27, we gave the infinite set guaranteed us by the axiom of infinity a placeholder name, “inf”. Line 30 is what we’ve been aiming for for the last few hundred words, and it honestly looks a little underwhelming. It’s not so immediately clear from this line that ω has all the properties that we want of the natural numbers. But at the same time, we couldn’t write something like “∀z (z∈ω ↔ (z=0 ∨ z=1 ∨ z=2 ∨ …)), because first-order logic is finitary (we aren’t allowed infinitely long sentences). So we have to make do with a definition of ω that may look a little more abstract that we may like. Suffice it to say that line 30 really does serve as an adequate definition of ω. It tells us that ω is the smallest set that contains all natural numbers. From this, we can pretty easily show that any particular natural number is an element of ω, and (less easily) that any other set (say, the set {2} or {5,1}) is not an element of ω.
If you’ve followed so far, give yourself a serious pat on the back. Together we’ve ascended past the realm of the finite to our first transfinite ordinal. This is no small accomplishment. But our journey does not end here. In fact, it has only barely begun. We’re going to start picking up speed from here on out, because as you’ll see, the ground we have yet to cover is much much greater than the ground we’ve covered so far.
The first step is easy. We already saw earlier how you can construct for any set x its successor set x⋃{x}. This construction didn’t rely on our sets being finite, it works just as well for the set ω. So ω has a successor! We’ll call it ω+1! Don’t believe me? I’ll prove it to you:
31. ∀x (x∈{ω} ↔ x=ω) (pair ω with ω)
32. ∀x (x∈{ω,{ω}} ↔ (x=ω ∨ x={ω})) (pair ω with {ω})
33. ∀x (x∈ω+1 ↔ ∃y(x∈y ∧ y∈{ω,{ω}})) (union {ω,{ω}})
34. ∀x (x∈ω+1 ↔ (x∈ω ∨ x=ω)) (neatening up)
There we have it! ω+1 = {0,1,2,3,…,ω}
And it doesn’t stop there: we can construct ω+2 = {0,1,2,3,…,ω,ω+1}. And ω+3 = {0,1,2,3,…,ω,ω+1,ω+2}. And so on, forever! By allowing the existence of one infinity, we’ve actually entailed the existence of an infinity of infinities!
But what’s next? We now have all the finite ordinals, and all the infinite ordinals of the form ω+n for finite n. What comes after this? Clearly, the next ordinal is just the set of all finite ordinals as well as all ordinals of the form ω+n! This ordinal is the smallest ordinal that’s larger than ω+n any finite n. So a natural name for it is ω+ω, or ω⋅2!
So conceptually ω⋅2 makes sense, but can we actually construct it? At first glance, this may seem unlikely. The axiom of infinity contains no guarantee that the infinite set it grants us contains ω, to say nothing of ω+1, ω+2, and the rest. And no finite amount of constructing successors will allow us to make the jump to ω⋅2 (for much the same reason as we needed the axiom of infinity to make the jump to ω). So perhaps we need to have a new axiom asserting the existence of ω⋅2? And then maybe we need a new axiom for ω⋅3, and ω⋅4, and so on forever! That would be a sad situation.
Well, things aren’t quite that bad. It turns out that we do need a new axiom. But we can do better than just guaranteeing the existence of ω⋅2. We’ll introduce an axiom schema that is by far the most powerful of all the axioms of ZFC. This axiom schema will take us far beyond ω⋅2, beyond ω⋅ω even, and far far beyond ω^ω and ω^ω^ω^… with infinitely many exponents. Introducing: the Axiom of Replacement! (dramatic music plays)
But first, we’re going to need to talk a little bit about the set theoretic notion of functions. I promise, it’ll be as quick as I can manage. Remember how we chose our language for ZFC to have no function symbols, only the single relation symbol ∈? This means that we have to build in functions through different means. We’ve already seen a hint of it when we talked about the sentence Succ(x,y) which said that x was the successor of y. This sentence is true for exactly the sets x and y such that x is the successor of y. We can think of the sentence as “selecting” ordered pairs (x,y) such that x = {y}. In other words, this sentence is filling the role of defining the function y ↦ {y}.
The same applies more generally. For any function f(x), we can construct the sentence F(x,y) which asserts “y = f(x)”. For instance, the identity function id(x) = x will be defined by the sentence Id(x,y): “y=x”. Notice that not all functions from sets to sets can be defined in this way, as we only have countably many sentences in our language to work with.
Suppose we’re handed a sentence φ(x,y). How are we to tell if φ(x,y) represents a function or just an ordinary sentence? Well, functions have the property that any input is mapped to exactly one output. We can write this formally: “∀x∀y∀z ((φ(x,y) ∧ φ(x,z)) → y=z)”. For shorthand, we’ll call this sentence isAFunction(φ).
And now we’re ready for the axiom schema of replacement.
Axiom of Replacement: isAFunction(φ) → ∀x∃y∀z (z∈y ↔ ∃w (w∈x ∧ φ(w,z)))
In English, this says that for any definable function f (defined by φ), and for any set of inputs x, the image of x under f exists. Like with the axiom schema of comprehension, this is a countably infinite collection of axioms, one for each well formed formula φ(w,z).
Let’s use this axiom to construct ω⋅2. First we define a function f that takes any finite number n to the ordinal ω+n. (Challenge: Try to explicitly define this function! Notice that the most obvious method for defining the function requires second-order logic. Try to come up with a trick that allows it to be defined in first-order ZFC!) Then we prove that this really is a function. Then we apply the axiom of replacement with our domain as ω (the set of all natural numbers). The image of ω under f is the set {ω,ω+1,ω+2,ω+3,…}. Not quite what we want. But we’re almost there!
Next we use the axiom of pairing to pair this newly constructed set with ω itself, giving us {{0,1,2,…}, {ω,ω+1,ω+2,…}}. And finally, we apply the axiom of union to this set, giving us {0,1,2,…,ω,ω+1,ω+2,…} = ω⋅2!
Phew, that was a lot of work just to make the jump to from ω to ω⋅2. But it was worth it! Now we can also jump to ω⋅3 in the exact same way!
Define a function f that maps n to ω⋅2+n. Now use replacement with ω as the domain to construct the set {ω⋅2, ω⋅2+1, ω⋅2+2, …}. Pair this set with ω⋅2, and union the result. This gives ω⋅3!
In exactly the same way, we can use the axiom of replacement to get ω⋅4, ω⋅5, ω⋅6, and so on to ω⋅n for any finite n! But it doesn’t stop there. We’ve just described a procedure to get ω⋅n for any finite n. So we write it as a function!
Define f as the function that maps n to ω⋅n. Now use replacement of f with ω as the domain to get the set {0, ω, ω⋅2, ω⋅3, ω⋅4, ω⋅5, …}. Apply the axiom of union to this set, and what do you get? Well it has to contain ω⋅n for every finite n, since each ω⋅n is contained in ω⋅m for every larger m. So it’s larger than all ordinals of the form ω⋅n for finite n. This new ordinal we’ve constructed is called ω⋅ω, or ω2.
But of course, our journey doesn’t stop there. We can use replacement to generate ω2 + ω, and ω2 + ω⋅2, ω2 + ω⋅3, and so on. But we can go further and use replacement to generate ω2 + ω2, or ω2⋅2! And from there we get ω2⋅3, ω2⋅4, and so on. And applying replacement to the function from n to ω2⋅n, we get a new ordinal larger than everything before, called ω3.
As you might be suspecting, this goes on forever. We can continually apply the axiom of replacement to get mind-bogglingly large infinities, each greater than the last. But here’s the kicker: all of these infinite ordinals that we’ve created so far? They all have the same cardinality.
Yes, that’s right. You may have thought that we had transcended ω in cardinality long ago, but no. For each infinite ordinal we’ve created so far, there’s a one-to-one mapping between it and ω. Think about it: every time we used replacement, we constructed a function that mapped an existing ordinal to a new one of the same cardinality. And in applying replacement to this function, we guaranteed that the new ordinal we created cannot be a larger cardinality than the existing ordinal! So each time we use replacement with a countable domain, we get a new countable set, each of whose elements is countable. And then if we use pairing or union, we’re always going to stay in the domain of the countable (unioning two countable sets just gets you another countable set, as does unioning a countable infinity of countable sets).
So now turn your mind to the following set: the set of all countable ordinals. Is this set itself an ordinal? It is if it’s the smallest uncountable ordinal, as then it contains every ordinal smaller than itself by definition! And what’s the cardinality of this set? It can’t be countable, because then it would have to be an element of itself! (Bonus question: Why is it that no ordinal can be an element of itself? Use the axiom of extensionality! Bonus question 2: In general, no set can be an element of itself. But this is not guaranteed by the axioms I’ve presented so far. The axiom that does the job is called the axiom of regularity/foundation, and it says that every set must have an element that it is disjoint with. Why does this prevent us from having sets that contain themselves?)
So this ordinal is the first uncountable ordinal. Its name is ω1. The cardinality of ω1 is the smallest cardinality that follows the cardinality of ω, and it’s called “aleph one” and written א1.
Now, I’ve already said that the same old paradigm we’ve used so far can’t get us to ω1. So can we get there with ZFC? It turns out that the answer is yes, and at the moment I’m not quite sure exactly how. It turns out that not only can ZFC construct ω1, it can also construct ω2 (the first ordinal with a larger cardinality than ω1), ω3, ω4, and so on forever.
So does ZFC have any limits? Or can we in principle construct every ordinal, using ever more ingenious means to transcend the limitations of our previous paradigms? The answer is no: ZFC is limited. There are ordinals so large that even ZFC cannot prove their existence (these ordinals have what’s called inaccessible cardinalities). To construct these new infinities, we must add them in as axioms, just as we had to for infinity (and indeed, for 0).
One might think that when we get to ordinals that are this mind-bogglingly large, nothing of any consequence could follow from asserting their existence. But this is not the case! Remarkably, if you add these new infinities to your theory, you can prove the consistency of ZFC. (That is, the consistency of the theory I’ve presented so far, which does not have these large cardinal axioms.) And to prove the consistency of this new theory, you must add even larger infinities. And now to prove the consistency of this one, you must expand the universe of sets again! And so on forever.
One might ask: “So how big is the universe of sets really?” At what point do we content ourselves to stop axiomatically asserting new and larger infinities, and say that we’ve obtained an adequate formalization of what the universe of sets looks like? I’m really not sure how to think about this question. Anyway, next up will be ordinal notation, and the notion of computable ordinals!