What comes next?
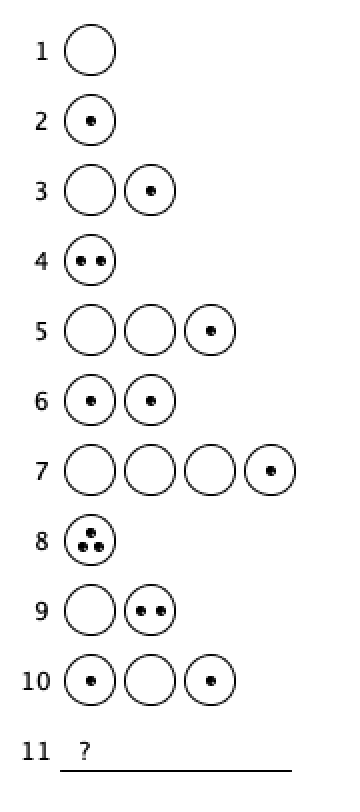
What comes next?
Many people have heard of Mandelbrot’s famous set. But far fewer have heard of its older sibling: the Buddhabrot. I find this object even more beautiful than the Mandelbrot set, and want to give it its proper appreciation here.
To start out with: What is the Mandelbrot set? It is defined as the set of complex values c that stay finite under arbitrary many repeated applications of the function fc(z) = z2 + c (where the first iteration is applied to z = 0).
So, for example, to check if the number 2 is in the Mandelbrot set, we just look at what happens when we plug in 0 to the function f2 and repeat:
0 becomes 02 + 2 = 2
2 becomes 22 + 2 = 6
6 becomes 62 + 2 = 38
38 becomes 382 + 2 = something large, and on and on.
You can probably predict that as we keep iterating, we’re going to eventually run off to infinity. So 2 is not in the set.
On the other hand, see what happens when we plug in -1:
0 becomes 02 + (-1) = -1
-1 becomes (-1)2 + (-1) = 0
0 becomes -1
-1 becomes 0
… and so on to infinity
With -1, we just bounce around back and forth between 0 and -1, so we clearly never diverge to infinity.
Now we can draw the elements of this set pretty easily, by simply shading in the numbers on the complex plane that are in the set. If you do so, you get the following visualization:

Cool! But what about all those colorful visualizations you’ve probably seen? (maybe even on this blog!)
Well, whether you’re in the Mandelbrot set or not is just a binary property. So by itself the Mandelbrot set doesn’t have a rich enough structure to account for all those pretty colors. What’s being visualized in those pictures is not just whether an element is in the Mandelbrot set, but also, if it’s not in the set (i.e. if the 0 diverges to infinity upon repeated applications of fc), how quickly it leaves the set!
In other words, the colors are a representation of how not in the set numbers are. There are some complex numbers that exist near the edge of the Mandelbrot that hang around the set for many many iterations before finally blowing up and running off to infinity. And these numbers will be colored differently from, say, the number “2”, which right away starts blowing up.
And that’s how you end up with pictures like the following:

Now, what if instead of visualizing how in the set various complex numbers are, we instead look at what complex numbers are most visited on average when running through Mandelbrot iterations? Well, that’s how we get the Buddhabrot!
Specifically, here’s a procedure we could run:
As you run this algorithm, you can visualize the results by giving complex numbers with more credits brighter colors. And as you do this, a curious figure begins to appear on the (rotated) complex plane:
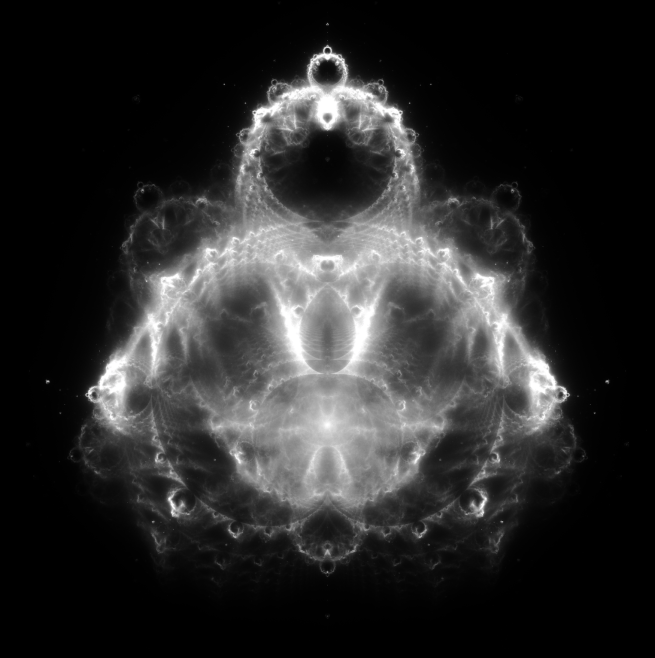
That’s right, Buddha is hanging out on the complex plane, hiding in the structure of the Mandelbrot set!
Put down three points on a piece of paper. Choose one of them as your “starting point”. Now, randomly choose one of the three points and hop from your starting point, halfway over to the chosen point. Mark down where you’ve landed. Then repeat: randomly choose one of the three starting points, and move halfway from your newly marked point to this new chosen point. Mark where you land. And on, and on, to infinity.
What pattern will arise? Watch and see!
Controls:
E to increase points/second.
Q to decrease points/second.
Click and drag the red points to move them around.
Pressing a number key will make a polygon with that number of sides.
[pjs4wp]
float N = 3;
float[] X = new float(N);
float[] Y = new float(N);
float radius = 600/2 – 20;
float i = 0;
while (N > i)
{
X[i] = radius * cos(2*PI*i/N – PI/2 + 2*PI/N);
Y[i] = radius * sin(2*PI*i/N – PI/2 + 2*PI/N);
i += 1;
}
float xNow = X[0];
float yNow = Y[0];
float speed = 1;
int selected = -1;
void setup()
{
size(600,600);
frameRate(10);
background(0);
}
void draw()
{
fill(255);
stroke(255);
text((str)(speed*10) + ” points / second\nE to speed up\nQ to slow down\nClick and drag red points!”,15,25);
translate(width/2, height/2);
float i = 0;
while(i j)
{
ellipse(X[j],Y[j],10,10);
j += 1;
}
}
void keyReleased()
{
bool reset = 0;
if (key == ‘e’) speed *= 10;
else if (key == ‘q’ && speed > 1) speed /= 10;
else if (key == ‘2’) N = 2;
else if (key == ‘3’) N = 3;
else if (key == ‘4’) N = 4;
else if (key == ‘5’) N = 5;
else if (key == ‘6’) N = 6;
else if (key == ‘7’) N = 7;
else if (key == ‘8’) N = 8;
else if (key == ‘9’) N = 9;
else reset = 1;
if (reset == 0)
{
background(0);
float i = 0;
while (N > i)
{
X[i] = radius * cos(2*PI*i/N – PI/2);
Y[i] = radius * sin(2*PI*i/N – PI/2);
i += 1;
}
xNow = X[0];
yNow = Y[0];
}
}
void mousePressed()
{
if (selected == -1)
{
float i = 0;
while (N > i)
{
if ((X[i] + 5 >= mouseX – width/2) && (mouseX – width/2 >= X[i] – 5))
if ((Y[i] + 5 >= mouseY – height/2) && (mouseY – height/2 >= Y[i] – 5))
selected = i;
i += 1;
}
}
}
void mouseReleased()
{
if (selected != -1)
{
X[selected] = mouseX – width/2;
Y[selected] = mouseY – height/2;
selected = -1;
xNow = X[0];
yNow = Y[0];
background(0);
}
}
[/pjs4wp]
Here’s a natural follow-up to my last post on the Mandelbrot set – an interactive Julia set explorer!
The Julia set corresponding to a particular point c = x + iy in the complex plane is defined as the set of complex numbers z that stay finite upon arbitrary iterations of the following function: fc(z) = z2 + c. The Mandelbrot set, by comparison, is defined as the set of complex numbers c such that the value obtained by starting with 0 and iterating the function fc arbitrarily many times converges.
What’s remarkable is now beautiful and complex the patterns that arise from this simple equation are. Take a look for yourself: just hover over a point to see its corresponding Julia set!
[pjs4wp]
float xmin = -1.8;
float xmax = 1.8;
float ymin = -1.2;
float ymax = 1.2;
float resolution = 30;
void setup()
{
size(600,400);
background(0);
stroke(255);
}
void draw()
{
background(0);
float cx = xmin + (xmax-xmin)*(float)(mouseX)/(float)(width);
float cy = ymin + (ymax-ymin)*(float)(mouseY)/(float)(height);
drawJuliaSet(cx, cy);
stroke(255);
fill(255);
line(-xmin*width/(xmax-xmin),0,-xmin*width/(xmax-xmin),height);
line(0,-ymin*height/(ymax-ymin),width,-ymin*height/(ymax-ymin));
}
void keyPressed()
{
if (key == ‘e’) resolution += 10;
if (key == ‘q’) resolution -= 10;
if (key == ‘ ‘) resolution = 30;
}
void drawJuliaSet(float cx, float cy)
{
text(“(” + (str)((int)(cx*100)/100.) + “,” + (str)(-(int)(cy*100)/100.) + “)”, 20, 20);
float i = 0;
float j = 0;
while (height > j)
{
x = xmin + (xmax-xmin)*(float)i/width;
y = ymin + (ymax-ymin)*(float)j/height;
float step = 0;
while (step 4) break;
step += 1;
}
stroke(color(0,255,0));
fill(color(0,255,0));
if (4 > x*x + y*y) point(i,j);
i += 1;
if (i == width)
{
i = 0;
j += 1;
}
}
stroke(0);
fill(color(255,0,0));
ellipse((cx-xmin)*width/(xmax-xmin),(cy-ymin)*height/(ymax-ymin),10,10);
}
[/pjs4wp]
Resolution is preset at a value good for seeing lots of details and loading at a reasonable speed, but should you want to change it, controls are ‘E’ to increase it and ‘Q’ to decrease it. To reset to default, press ‘SPACE’.
I finally figured out how to embed programs that I write onto these blog posts! I’m really excited about the way this will expand my ability to describe and explain all sorts of topics in the future. I’ll inaugurate this new ability with an old classic: a program that allows you to explore the Mandelbrot set. I’ve preset it with a pretty good resolution limit that allows for nice viewing as well as not too slow load times, but you can adjust it as you please! Enjoy!
Controls:
UP or W to zoom in
DOWN or S to zoom out
CLICK to center view on the clicked point
E to double resolution (mashing this will slow things down a LOT, so use sparingly)
Q to halve resolution
SPACE to reset everything
[pjs4wp]
double xmin = -2.25;
double xmax = .75;
double ymin = -1.1;
double ymax = 1.1;
double resolution = 200;
double pathLength = 1000;
void setup()
{
size(600,400);
background(0);
colorMode(HSB, 255, 255, 255);
drawSet();
}
void draw()
{
double cx = xmin + (xmax – xmin)*mouseX/width;
double cy = ymin + (ymax – ymin)*mouseY/height;
double x = 0;
double y = 0;
double path = 0;
stroke(255);
while (path < pathLength)
{
point(x,y);
double yNew = 2*x*y + cy;
x = x*x – y*y + cx;
y = yNew;
path += 1;
}
}
void drawSet()
{
background(0);
double xpos = 0;
double ypos = 0;
while(ypos < 400)
{
double cx = xmin + (xmax – xmin)*xpos/width;
double cy = ymin + (ymax – ymin)*ypos/height;
double x = 0;
double y = 0;
double step = 0;
while(step 4)
{
break;
}
}
if(4 > x*x + y*y)
{
stroke(0);
}
else
{
stroke(color(255*step/resolution,255,255));
}
point(xpos,ypos);
xpos += 1;
if (xpos == 600)
{
xpos = 0;
ypos += 1;
}
}
}
void mouseReleased()
{
double dx = xmax – xmin;
double dy = ymax – ymin;
double cx = xmin + dx*mouseX/width;
double cy = ymin + dy*mouseY/height;
xmin = cx – dx/2;
xmax = cx + dx/2;
ymin = cy – dy/2;
ymax = cy + dy/2;
drawSet();
}
void keyPressed()
{
double dx = xmax – xmin;
double dy = ymax – ymin;
if (keyCode == UP || key == ‘w’)
{
xmin += .25*dx;
xmax -= .25*dx;
ymin += .25*dy;
ymax -= .25*dy;
drawSet();
}
if (keyCode == DOWN || key == ‘s’)
{
xmin -= .5*dx;
xmax += .5*dx;
ymin -= .5*dy;
ymax += .5*dy;
drawSet();
}
if (key == ‘ ‘)
{
xmin = -2.25;
xmax = .75;
ymin = -1.1;
ymax = 1.1;
resolution = 200;
drawSet();
}
if (key == ‘e’)
{
resolution *= 2;
drawSet();
}
if (key == ‘q’)
{
resolution /= 2;
drawSet();
}
}
[/pjs4wp]
Try zooming in on a region near the edge of the set where there are black regions and increasing the resolution. “Resolution” here really means “the number of Mandelbrot iterations run to test if the point diverges or converges”, and the black points are those that were judged to be convergent. So some of these points might be found to be no longer convergent with increasing resolution! Which is why you might notice black regions suddenly filling up with color if you increase the resolution. (Of course, some regions are truly convergent, like the central chunk of the Mandelbrot set around (0,0), so such points’ colors will not depend on the resolution.)
If you’re confused about what this image is, I recommend checking out Numberphile’s video on the Mandelbrot set. (Actually, I recommend it even if you aren’t confused.)
A friend of mine recently showed me an essay series on quantum computers. These essays are fantastically well written and original, and I highly encourage anybody with the slightest interest in the topic to check them out. They are also interesting to read from a pedagogical perspective, as experiments in a new style of teaching (self-described as an “experimental mnemonic medium”).
There’s one particular part of the post which articulated the potential impact of quantum computing better than I’ve seen it articulated before. Reading it has made me update some of my opinions about the way that quantum computers will change the world, and so I want to post that section here with full credit to the original authors Michael Nielsen and Andy Matuschak. Seriously, go to the original post and read the whole thing! You won’t regret it.
No, really, what are quantum computers good for?
It’s comforting that we can always simulate a classical circuit – it means quantum computers aren’t slower than classical computers – but doesn’t answer the question of the last section: what problems are quantum computers good for? Can we find shortcuts that make them systematically faster than classical computers? It turns out there’s no general way known to do that. But there are some interesting classes of computation where quantum computers outperform classical.
Over the long term, I believe the most important use of quantum computers will be simulating other quantum systems. That may sound esoteric – why would anyone apart from a quantum physicist care about simulating quantum systems? But everybody in the future will (or, at least, will care about the consequences). The world is made up of quantum systems. Pharmaceutical companies employ thousands of chemists who synthesize molecules and characterize their properties. This is currently a very slow and painstaking process. In an ideal world they’d get the same information thousands or millions of times faster, by doing highly accurate computer simulations. And they’d get much more useful information, answering questions chemists can’t possibly hope to answer today. Unfortunately, classical computers are terrible at simulating quantum systems.
The reason classical computers are bad at simulating quantum systems isn’t difficult to understand. Suppose we have a molecule containing n atoms – for a small molecule, n may be 1–, for a complex molecule it may be hundreds or thousands or even more. And suppose we think of each atom as a qubit (not true, but go with it): to describe the system we’d need 2^n different amplitudes, one amplitude for each –bit computational basis state, e.g., |010011.
Of course, atoms aren’t qubits. They’re more complicated, and we need more amplitudes to describe them. Without getting into details, the rough scaling for an n–atom molecule is that we need k^n amplitudes, where . The value of k depends upon context – which aspects of the atom’s behavior are important. For generic quantum simulations k may be in the hundreds or more.
That’s a lot of amplitudes! Even for comparatively simple atoms and small values of n, it means the number of amplitudes will be in the trillions. And it rises very rapidly, doubling or more for each extra atom. If , then even n = atoms will require 100 million trillion amplitudes. That’s a lot of amplitudes for a pretty simple molecule.
The result is that simulating such systems is incredibly hard. Just storing the amplitudes requires mindboggling amounts of computer memory. Simulating how they change in time is even more challenging, involving immensely complicated updates to all the amplitudes.
Physicists and chemists have found some clever tricks for simplifying the situation. But even with those tricks simulating quantum systems on classical computers seems to be impractical, except for tiny molecules, or in special situations. The reason most educated people today don’t know simulating quantum systems is important is because classical computers are so bad at it that it’s never been practical to do. We’ve been living too early in history to understand how incredibly important quantum simulation really is.
That’s going to change over the coming century. Many of these problems will become vastly easier when we have scalable quantum computers, since quantum computers turn out to be fantastically well suited to simulating quantum systems. Instead of each extra simulated atom requiring a doubling (or more) in classical computer memory, a quantum computer will need just a small (and constant) number of extra qubits. One way of thinking of this is as a loose quantum corollary to Moore’s law:
The quantum corollary to Moore’s law: Assuming both quantum and classical computers double in capacity every few years, the size of the quantum system we can simulate scales linearly with time on the best available classical computers, and exponentially with time on the best available quantum computers.
In the long run, quantum computers will win, and win easily.
The punchline is that it’s reasonable to suspect that if we could simulate quantum systems easily, we could greatly speed up drug discovery, and the discovery of other new types of materials.
I will risk the ire of my (understandably) hype-averse colleagues and say bluntly what I believe the likely impact of quantum simulation will be: there’s at least a 50 percent chance quantum simulation will result in one or more multi-trillion dollar industries. And there’s at least a 30 percent chance it will completely change human civilization. The catch: I don’t mean in 5 years, or 10 years, or even 20 years. I’m talking more over 100 years. And I could be wrong.
What makes me suspect this may be so important?
For most of history we humans understood almost nothing about what matter is. That’s changed over the past century or so, as we’ve built an amazingly detailed understanding of matter. But while that understanding has grown, our ability to control matter has lagged. Essentially, we’ve relied on what nature accidentally provided for us. We’ve gotten somewhat better at doing things like synthesizing new chemical elements and new molecules, but our control is still very primitive.
We’re now in the early days of a transition where we go from having almost no control of matter to having almost complete control of matter. Matter will become programmable; it will be designable. This will be as big a transition in our understanding of matter as the move from mechanical computing devices to modern computers was for computing. What qualitatively new forms of matter will we create? I don’t know, but the ability to use quantum computers to simulate quantum systems will be an essential part of this burgeoning design science.
Quantum computing for the very curious
(Andy Matuschak and Michael Nielsen)
Let me start this off by saying that if you’re reading this blog and haven’t ever checked out the Youtube channel Numberphile, you need to go there right away and start bingeing their videos. That’s what I’ve been doing for the last few days, and it’s given me tons of cool new puzzles to consider.
Here’s one:
Naturally, after watching this video I wanted to try this out for myself. Here you see the pattern arising beautifully from the randomness:

I urge you to think hard about why the Sierpinski triangle would arise from something as simple as randomly hopping between midpoints. It’s very non-obvious, and although I have a few ideas, I’m still missing a clear intuition.
I also made some visualizations for other shapes. I’ll show some of them, but encourage you to make predictions about what pattern you’d expect to see before scrolling down to see the actual result.
First:
Instead of three points arranged as above, we will start out with four points arranged in a perfect square. Then, as before, we’ll jump from our starting point halfway to one of these four, and will continue this procedure ad infinitum.
What pattern will arise? Do you think that we’ll have “missing regions” where no points can land, like with the triangle?
Scroll down to see the answer…
(…)
(…)
(…)

Okay! So it looks like the whole square gets filled out, with no missing regions. This was pretty surprising to me; given that three points gave rise to a intricate fractal pattern, why wouldn’t four points do the same? What’s special about “3” .
Well, perhaps things will be different if we tweak the positions of the corners slightly? Will any quadrilateral have the same behavior of filling out all the points, or will the blank regions re-arise? Again, make a prediction!
Let’s see:




Okay, now we see that apparently the square was actually a very special case! Pretty much any quadrilateral we can construct will give us a nested infinity of blank regions, as long as at least one angle is not equal to 90º. Again, this is fascinating and puzzling to me. Why do 90º angles invariably cause the whole region to fill out? I’m not sure.
Let’s move on to a pentagon! Do you think that a regular pentagon will behave more like a triangle or a square?
Take a look…

And naturally, the next question is what about a hexagon?

Notice the difference between the hexagon and all the previous ones! Rather than having small areas of points that are never reached, it appears that suddenly we get lines! Again, I encourage you to try to think about why this might be (what’s so special about 6?) and leave a comment if you have any ideas.
Now, I because curious about what other types of patterns we can generate with simple rules like these. I wondered what would happen if instead of simply jumping to the average of the current point and a randomly chosen point, we built a pattern with some “memory”. For instance, what if we didn’t just look at the current point and the randomly chosen point, but also at the last chosen point? We could then take the middle of the triangle formed by these three points as our new point.
It turns out that the patterns that arise from this are even more beautiful than the previous ones! (In my opinion, of course)
Take a look:





I’ll stop here, but this is a great example of how beautiful and surprising math can be. I would have never guessed that such intricate fractal patterns would arise from such simple random rules.
A fun problem I recently came across:
Consider two players: Alice and Bob. Alice moves first. At the start of the game, Alice has two piles of coins in front of her: one pile contains 4 coins and the other pile contains 1 coin. Each player has two moves available: either “take” the larger pile of coins and give the smaller pile to the other player or “push” both piles across the table to the other player. Each time the piles of coins pass across the table, the quantity of coins in each pile doubles. For example, assume that Alice chooses to “push” the piles on her first move, handing the piles of 1 and 4 coins over to Bob, doubling them to 2 and 8. Bob could now use his first move to either “take” the pile of 8 coins and give 2 coins to Alice, or he can “push” the two piles back across the table again to Alice, again increasing the size of the piles to 4 and 16 coins. The game continues for a fixed number of rounds or until a player decides to end the game by pocketing a pile of coins.
(from the wiki)
(Assume that if the game gets to the final round and the last player decides to “push”, the pot is doubled and they get the smaller pile.)
Assuming that they are self-interested, what do you think is the rational strategy for each of Alice and Bob to adopt? What is the rational strategy if they each know that the other reasons about decision-making in the same way that they themselves do? And what happens if two updateless decision theorists are pitted against each other?
If you have some prior familiarity with game theory, you might have seen the backwards induction proof right away. It turns out that standard game theory teaches us that the Nash equilibrium is to defect as soon as you can, thus never exploiting the “doubling” feature of the setup.
Why? Supposing that you have made it to the final round of the game, you stand to get a larger payout by “defecting” and taking the larger pile rather than the doubled smaller pile. But your opponent knows that you’ll reason this way, so they reason that they are better off defecting the round before… and so on all the way to the first round.

This sucks. The game ends right away, and none of that exponential goodness gets taken advantage of. If only Alice and Bob weren’t so rational!
We can show that this conclusion follows as long as the three things are true of Alice and Bob:
It’s pretty hard to deny the reasonableness of any of these three assumptions!
Here’s a related problem:
An airline loses two suitcases belonging to two different travelers. Both suitcases happen to be identical and contain identical antiques. An airline manager tasked to settle the claims of both travelers explains that the airline is liable for a maximum of $100 per suitcase—he is unable to find out directly the price of the antiques.
To determine an honest appraised value of the antiques, the manager separates both travelers so they can’t confer, and asks them to write down the amount of their value at no less than $2 and no larger than $100. He also tells them that if both write down the same number, he will treat that number as the true dollar value of both suitcases and reimburse both travelers that amount. However, if one writes down a smaller number than the other, this smaller number will be taken as the true dollar value, and both travelers will receive that amount along with a bonus/malus: $2 extra will be paid to the traveler who wrote down the lower value and a $2 deduction will be taken from the person who wrote down the higher amount. The challenge is: what strategy should both travelers follow to decide the value they should write down?
(again, from the wiki)
Suppose you put no value on honesty, and only care about getting the most money possible. Further, suppose that both travelers reason the same way about decision problems, and that they both know this fact (and that they both know that they both know this fact, and so on).
The first intuition you might have is that both should just write down $100. But if you know that your partner is going to write down $100, then you stand to gain one whole dollar by defecting and writing $99 (thus collecting the $2 bonus for a total of $101). But if they know that you’re going to write $99, then they stand to gain one whole dollar by defecting and writing $98 (thus netting $100). And so on.
In the end both of these unfortunate “rational” individuals end up writing down $2. Once again, we see the tragedy of being a rational individual.
Of course, we could take these thought experiments to be an indication not of the inherent tragedy of rationality, but instead of the need for a better theory of rationality.
For instance, you might have noticed that the arguments we used in both cases relied on a type of reasoning where each agent assumes that they can change their decision, holding fixed the decision of the other agent. This is not a valid move in general, as it assumes independence! It might very well be that the information about what decision you make is relevant to your knowledge about what the other agent’s decision will be. In fact, when we stipulated that you reason similarly to the other agent, we are in essence stipulating an evidential relationship between your decision and theirs! So the arguments we gave above need to be looked at more closely.
If the agents do end up taking into account their similarity, then their behavior is radically different. For example, we can look at the behavior of updateless decision theory: two UDTs playing each other in the Centipede game “push” every single round (including the final one!), thus ending up with exponentially higher rewards (on the order of $2N, where N is the number of rounds). And two UDTs in the Traveller’s Dilemma would write down $100, thus both ending up roughly $98 better off than otherwise. So perhaps we aren’t doomed to a gloomy view of rationality as a burden eternally holding us back!
One final problem.
Two players, this time with just one pile of coins in front of them. Initially this pile contains just 1 coin. The players take turns, and each turn they can either take the whole pile or push it to the other side, in which case the size of the pile will double. This will continue for a fixed number of rounds or until a player ends the game by taking the pile.
On the final round, the last player has a choice of either taking all the coins or pushing them over, thus giving the entire doubled pile to their opponent. Both players are perfectly self-interested, and this fact is common knowledge. And finally, suppose that who goes first is determined by a coin flip.
Standard decision theory obviously says that the first person should just take the 1 coin and the game ends there. What would UDT do here? What do you think is the rational policy for each player?
I’m confused about how satisfactory a multiverse is as an alternative explanation for the fine-tuning of our universe (alternative to God, that is).
My initial intuition about this is that it is a perfectly satisfactory explanation. It looks like we can justify this on Bayesian grounds by noting that the probability of the universe we’re in being fine-tuned for intelligent life given that there is a multiverse is nearly 1. The probability of fine-tuning given God is also presumably nearly 1, so the observation of fine-tuning shouldn’t push us much in one direction or other.
(Obligatory photo of the theorem doing the work here)

But here’s another argument I’m aware of: A firing squad of twenty sharpshooters aims at you and fires. They all miss. You are obviously very surprised by this. But now somebody comes up to you and tells you that in fact there is a multiverse full of “you”s in identical situations. They all faced down the firing squad, and the vast majority of them died. Now, given that you exist to ask the question, of COURSE you are in the universe in which they all missed. So should you be no longer surprised?
I take it the answer to this is “No, even though I know that I could only be alive right now asking this question if the firing squad missed, this doesn’t remove any mystery from the firing squad missing. It’s exactly as mysterious that I am alive right now as that the firing squad missed, so my existence doesn’t lessen the explanatory burden we face.
The firing squad situation seems exactly parallel to the fine-tuning of the universe. We find ourselves in a universe that is remarkably fine tuned in a way that seems extremely a priori improbable. Now we’re told that there are in fact a massive number of universes out there, the vast majority of which are devoid of life. So of course we exist in one of the universes that is fine-tuned for our existence.
Let’s make this even more intuitive: The earth exists in a Goldilocks zone around the Sun. Too much closer or further away and life would not be possible. Maybe this was mysterious at some point when humans still thought that there was just one solar system in the universe. But now we know that galaxies contain hundreds of billions of solar systems, most of which probably don’t have any planets in their Goldilocks zones. And with this knowledge, the mystery entirely disappears. Of course we’re on a planet that can support life, where else would we be??
So my question is: Why does this argument feel satisfactory in the fine-tuning and Goldilocks examples but not the firing squad example?
A friend I asked about this responded:
if you modify the firing squad scenario so that you don’t exist prior to the shooting and are only brought into existence if they all miss does it still feel less satisfactory then the multiverse case?
And I responded that no, it no longer feels less satisfactory than the multiverse case! Somehow this tweak “fixes” the intuitions. This suggests that the relevant difference between the two cases is something about existence prior to the time of the thought experiment. But how do we formalize this difference? And why should it be relevant? I’m perplexed.
