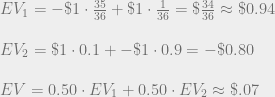There are many principles of rational choice that seem highly intuitively plausible at first glance. Sometimes upon further reflection we realize that a principle we initially endorsed is not quite as appealing as we first thought, or that it clashes with other equally plausible principles, or that it requires certain exceptions and caveats that were not initially apparent. We can think of many debates in philosophy as clashes of these general principles, where the thought experiments generated by philosophers serve as the datum that put on display their relative merits and deficits. In this essay, I’ll explore a variety of different principles for rational decision making and consider the ways in which they satisfy and frustrate our intuitions. I will focus in especially on the notion of reflective consistency, and see what sort of decision theory results from treating this as our primary desideratum.
I want to start out by illustrating the back-and-forth between our intuitions and the general principles we formulate. Consider the following claim, known as the dominance principle: If a rational agent believes that doing A is better than not doing A in every possible world, then that agent should do A even if uncertain about which world they are in. Upon first encountering this principle, it seems perfectly uncontroversial and clearly valid. But now consider the following application of the dominance principle:
“A student is considering whether to study for an exam. He reasons that if he will pass the exam, then studying is wasted effort. Also, if he will not pass the exam, then studying is wasted effort. He concludes that because whatever will happen, studying is wasted effort, it is better not to study.” (Titelbaum 237)
The fact that this is clearly a bad argument casts doubt on the dominance principle. It is worth taking a moment to ask what went wrong here. How did this example turn our intuitions on their heads so completely? Well, the flaw in the student’s line of reasoning was that he was ignoring the effect of his studying on whether or not he ends up passing the exam. This dependency between his action and the possible world he ends up in should be relevant to his decision, and it apparently invalidates his dominance reasoning.
A restricted version of the dominance principle fixes this flaw: If a rational agent prefers doing A to not doing A in all possible worlds and which world they are in is independent of whether they do A or not, then that agent should do A even if they are uncertain about which world they are in. I’ll call this the simple dominance principle. This principle is much harder to disagree with than our starting principle, but the caveat about independence greatly limits its scope. It applies only when our uncertainty about the state of the world is independent of our decision, which is not the case in most interesting decision problems. We’ll see by the end of this essay that even this seemingly obvious principle can be made to conflict with another intuitively plausible principle of rational choice.
The process of honing our intuitions and fine-tuning our principles like this is sometimes called seeking reflective consistency, where reflective consistency is the hypothetical state you end up in after a sufficiently long period of consideration. Reflective consistency is achieved when you have reached a balance between your starting intuitions and other meta-level desiderata like consistency and simplicity, such that your final framework is stable against further intuition-pumping. This process has parallels in other areas of philosophy such as ethics and epistemology, but I want to suggest that it is particularly potent when applied to decision theory. The reason for this is that a decision theory makes recommendations for what action to take in any given setup, and we can craft setups where the choice to be made is about what decision theory to adopt. I’ll call these setups self-reflection problems. By observing what choices a decision theory makes in self-reflection problems, we get direct evidence about whether the decision theory is reflectively consistent or not. In other words, we don’t need to do all the hard work of allowing thought experiments to bump our intuitions around; we can just take a specific decision algorithm and observe how it behaves upon self-reflection!
What we end up with is the following principle: Whatever decision theory we end up endorsing should be self-recommending. We should not end up in a position where we endorse decision theory X as the final best theory of rational choice, but then decision theory X recommends that we abandon it for some other decision theory that we consider less rational.
The connection between self-recommendation and reflective consistency is worth fleshing out in a little more detail. I am not saying that self-recommendation is sufficient for reflective consistency. A self-recommending decision theory might be obviously in contradiction with our notion of rational choice, such that any philosopher considering this decision theory would immediately discard it as a candidate. Consider, for instance, alphabetical decision theory, which always chooses the option which comes alphabetically first in its list of choices. When faced with a choice between alphabetical decision theory and, say, evidential decision theory, alphabetical decision theory will presumably choose itself, reasoning that ‘a’ comes before ‘e’. But we don’t want to call this a virtue of alphabetical decision theory. Even if it is uniformly self-recommending, alphabetical decision theory is sufficiently distant from any reasonable notion of rational choice that we can immediately discard it as a candidate.
On the other hand, even though not all self-recommending theories are reflectively consistent, any reflectively consistent decision theory must be self-recommending. Self-recommendation is a necessary but not sufficient condition for an adequate account of rational choice.
Now, it turns out that this principle is too strong as I’ve phrased it and requires a few caveats. One issue with it is what I’ll call the problem of unfair decision problems. For example, suppose that we are comparing evidential decision theory (henceforth EDT) to causal decision theory (henceforth CDT). (For the sake of time and space, I will assume as background knowledge the details of how each of these theories work.) We put each of them up against the following self reflection problem:
An omniscient agent peeks into your brain. If they see that you are an evidential decision theorist, they take all your money. Otherwise they leave you alone. Before they peek into your brain, you have the ability to modify your psychology such that you become either an evidential or causal decision theorist. What should you do?
EDT reasons as follows: If I stay an EDT, I lose all my money. If I self-modify to CDT, I don’t. I don’t want to lose all my money, so I’ll self-modify to CDT. So EDT is not self-recommending in this setup. But clearly this is just because the setup is unfairly biased against EDT, not because of any intrinsic flaw in EDT. In fact, it’s a virtue of a decision theory to not be self-recommending in such circumstances, as doing so indicates a basic awareness of the payoff structure of the world it faces.
While this certainly seems like the right thing to say about this particular decision problem, we need to consider how exactly to formalize this intuitive notion of “being unfairly biased against a decision theory.” There are a few things we might say here. For one, the distinguishing feature of this setup seems to be that the payout is determined not based off the decision made by an agent, but by their decision theory itself. This seems to be at the root of the intuitive unfairness of the problem; EDT is being penalized not for making a bad decision, but simply for being EDT. A decision theory should be accountable for the decisions it makes, not for simply being the particular decision theory that it happens to be.
In addition, by swapping “evidential decision theory” and “causal decision theory” everywhere in the setup, we end up arriving at the exact opposite conclusion (evidential decision theory looks stable, while causal decision theory does not). As long as we don’t have any a priori reason to consider one of these setups more important to take into account than the other, then there is no net advantage of one decision theory over the other. If a decision problem belongs to a set of equally a priori important problems obtained by simply swapping out the terms for different decision theories, and no decision theory comes out ahead on the set as a whole, then perhaps we can disregard the entire set for the purposes of evaluating decision theories.
The upshot of all of this is that what we should care about is decision problems that don’t make any direct reference to a particular decision theory, only to decisions. We’ll call such problems decision-determined. Our principle then becomes the following: Whatever decision theory we end up endorsing should be self-recommending in all decision-determined problems.
There’s certainly more to be said about this principle and if any other caveats need be applied to it, but for now let’s move on to seeing what we end up with when we apply this principle in its current state. We’ll start out with an analysis of the infamous Newcomb problem.
You enter a room containing two boxes, one opaque and one transparent. The transparent box contains $1,000. The opaque box contains either $0 or $1,000,000. Your choice is to either take just the opaque box (one-box) or to take both boxes (two-box). Before you entered the room, a predictor scanned your brain and created a simulation of you to see what you would do. If the simulation one-boxed, then the predictor filled the opaque box with $1,000,000. If the simulation two-boxed, then the opaque box was left empty. What do you choose?
EDT reasons as follows: If I one-box, then this gives me strong evidence that I have the type of brain that decides to one-box, which gives me strong evidence that the predictor’s simulation of me one-boxed, which in turn gives me strong evidence that the opaque box is full. So if I one-box, I expect to get $1,000,000. On the other hand, if I two-box, then this gives me strong evidence that my simulation two-boxed, in which case the opaque box is empty. So if I two-box, I expect to get only $1,000. Therefore one-boxing is better than two-boxing.
CDT reasons as follows: Whether the opaque box is full or empty is already determined by the time I entered the room, so my decision has no causal effect upon the box’s contents. And regardless of the contents of the box, I always expect to leave $1,000 richer by two-boxing than by one-boxing. So I should two-box.
At this point it’s important to ask whether Newcomb’s problem is a decision determined problem. After all, the predictor decides whether to fill the transparent box by scanning your brain and stimulating you. Isn’t that suspiciously similar to our earlier example of penalizing agents based off their decision theory? No. The simulator decides what to do not by evaluating your decision theory, but by its prediction about your decision. You aren’t penalized for being a CDT, just for being the type of agent that one-boxes. To see this you only need to observe that any decision theory that one-boxes would be treated identically to CDT in this problem. The determining factor is the decision, not the decision theory.
Now, let’s make the Newcomb problem into a test of reflective consistency. Instead of your choice being about whether to one-box or to two-box while in the room, your choice will now take place before you enter the room, and will be about whether to be an evidential decision theorist or a causal decision theorist when in the room. What does each theory do?
EDT’s reasoning: If I choose to be an evidential decision theorist, then I will one-box when in the room. The predictor will simulate me as one-boxing, so I’ll end up walking out with $1,000,000. If I choose to be a causal decision theorist, then I will two-box when in the room, the predictor will predict this, and I’ll walk out with only $1,000. So I will stay an EDT.
Interestingly, CDT agrees with this line of reasoning. The decision to be an evidential or causal decision theorist has a causal effect on how the predictor’s simulation behaves, so a causal decision theorist sees that the decision to stay a causal decision theorist will end up leaving them worse off than if they had switched over. So CDT switches to EDT. Notice that in CDT’s estimation, the decision to switch ends up making them $999,000 better off. This means that CDT would pay up to $999,000 just for the privilege of becoming an evidential decision theorist!
I think that looking at an actual example like this makes it more salient why reflective consistency and self-recommendation is something that we actually care about. There’s something very obviously off about a decision theory that knows beforehand that it will reliably perform worse than its opponent, so much so that it would be willing to pay up to $999,000 just for the privilege of becoming its opponent. This is certainly not the type of behavior that we associate with a rational agent that trusts itself to make good decisions.
Classically, this argument has been phrased in the literature as the “why ain’tcha rich?” objection to CDT, but I think that the objection goes much deeper than this framing would suggest. There are several plausible principles that all apply here, such as that a rational decision maker shouldn’t regret having the decision theory they have, a rational decision maker shouldn’t pay to limit their future options, and a rational decision maker shouldn’t pay to decrease the values in their payoff matrix. The first of these is fairly self-explanatory. One influential response to it has been from James Joyce, who said that the causal decision theorist does not regret their decision theory, just the situation they find themselves in. I’d suggest that this response makes little sense when the situation the find themselves in is a direct result of their decision theory. As for the second and third of these, we could imagine giving a causal decision theorist the choice to pay money to remove the future possibility of two-boxing, or to hire a gunman that would shoot them if they try to take the transparent box. In each of these cases, CDT would endorse the decision to pay. I mention these other principles just to suggest that we have sound philosophical reason to care about self-recommendation independent of the reflective consistency considerations that we started out by discussing.
The takeaway from this modified Newcomb problem is that CDT is not reflectively consistent, and that it will self-modify to EDT in the right circumstances. Does this mean that EDT is more reflectively consistent than CDT? It turns out that no, this is not the case. We can construct another thought experiment in which EDT self-modifies to become CDT, called the Newcomb’s Soda problem:
You were just given either Soda 1 or Soda 2, which are indistinguishable. There was a 50% chance of each being the type you were given. You are now given a choice as to whether to choose chocolate ice cream or vanilla ice cream. Those that had Soda 1 have a strong unconscious inclination to choose chocolate ice cream and will be given $1,000,000 after they choose the ice cream. Those that had Soda 2 have a strong unconscious inclination to choose vanilla ice cream and are given nothing. If you choose vanilla ice cream, you get $1,000. What do you choose?
EDT reasons that choosing chocolate ice cream gives them strong evidence that they were given Soda 1, in which case they will be given $1,000,000. So they would be willing to give up the $1000 reward for choosing vanilla ice cream, in order to increase their chances of getting the million. CDT reasons that what soda they were given is a fixed fact that isn’t causally influenced by the decision they make. So they have a 50% chance of getting the million regardless of their choice, but choosing to take the vanilla guarantees them an additional $1000. Therefore they take vanilla.
This is clearly a decision-determined problem, so let’s see how EDT and CDT do upon self-reflection. Given the chance to modify themselves to EDT before being given the soda, a causal decision theorist would see no advantage to doing so. After all, being an evidential decision theorist doesn’t make you more or less likely to get the $1,000,000, it just ensures that you won’t get the $1000. And the evidential decision theorist agrees! By changing to causal decision theory, they guarantee themselves an extra $1000 while not making it any more or less likely that they’ll be given the chocolate soda (and accordingly, the million dollars).
The upshot of this is that both CDT and EDT are reflective inconsistent in the class of decision determined problems. What we seek, then, is a new decision theory that behaves like EDT in the Newcomb problem and like CDT in Newcomb’s Soda. One such theory was pioneered by machine learning researcher Eliezer Yudkowsky, who named it timeless decision theory (henceforth TDT). To deliver different verdicts in the two problems, we must find some feature that allows us to distinguish between their structure. TDT does this by distinguishing between the type of correlation arising from ordinary common causes (like the soda in Newcomb’s Soda) and the type of correlation arising from faithful simulations of your behavior (as in Newcomb’s problem).
This second type of correlation is called logical dependence, and is the core idea motivating TDT. The simplest example of this is the following: two twins, physically identical down to the atomic level, raised in identical environments in a deterministic universe, will have perfectly correlated behavior throughout the lengths of their lives, even if they are entirely causally separated from each other. This correlation is apparently not due to a common cause or to any direct causal influence. It simply arises from the logical fact that two faithful instantiations of the same function will return the same output when fed the same input. Considering the behavior of a human being as an instantiation of an extremely complicated function, it becomes clear why you and your parallel-universe twin behave identically: you are instantiations of the same function! We can take this a step further by noting that two functions can have a similar input-output structure, in which case the physical instantiations of each function will have correlated input-output behavior. This correlation is what’s meant by logical dependence.
To spell this out a bit further, imagine that in a far away country, there are factories that sell very simple calculators. Each calculator is designed to only run only one specific computation. Some factories are multiplication-factories; they only sell calculators that compute 713*291. Others are addition-factories; they only sell calculators that compute 713+291. You buy two calculators from one of these factories, but you’re not sure which type of factory you purchased from. Your credences are 50/50 split between the factory you purchased from being a multiplication-factory and it being an addition-factory. You also have some logical uncertainty regarding what the value of 713*291 is. You are evenly split between the value being 207,481 and the value being 207,483. On the other hand, you have no uncertainty about what the value of 713+291 is; you know that it is 1004.
Now, you press “ENTER” on one of the two calculators you purchased, and find that the result is 207,483. For a rational reasoner, two things should now happen: First, you should treat this result as strong evidence that the factory from which both calculators were bought was a multiplication-factory, and therefore that the other calculator is also a multiplier. And second, you should update strongly on the other calculator outputting 207,483 rather than 207,481, since two calculators running the same computation will output the same result.
The point of this example is that it clearly separates out ordinary common cause correlation from a different type of dependence. The common cause dependence is what warrants you updating on the other calculator being a multiplier rather than an adder. But it doesn’t warrant you updating on the result on the other calculator being specifically 207,483; to do this, we need the notion of logical dependence, which is the type of dependence that arises whenever you encounter systems that are instantiating the same or similar computations.
Connecting this back to decision theory, TDT treats our decision as the output of a formal algorithm, which is our decision-making process. The behavior of this algorithm is entirely determined by its logical structure, which is why there are no upstream causal influences such as the soda in Newcomb’s Soda. But the behavior of this algorithm is going to be correlated with the parts of the universe that instantiate a similar function (as well as the parts of the universe it has a causal influence on). In Newcomb’s problem, for example, the predictor generates a detailed simulation of your decision process based off of a brain scan. This simulation of you is highly logically correlated with you, in that it will faithfully reproduce your behavior in a variety of situations. So if you decide to one-box, you are also learning that your simulation is very likely to one-box (and therefore that the opaque box is full).
Notice that the exact mechanism by which the predictor operates becomes very important for TDT. If the predictor operates by means of some ordinary common cause where no logical dependence exists, TDT will treat its prediction as independent of your choice. This translates over to why TDT behaves like CDT on Newcomb’s Soda, as well as other so-called “medical Newcomb problems” such as the smoking lesion problem. When the reason for the correlation between your behavior and the outcome is merely that both depend on a common input, TDT treats your decision as an intervention and therefore independent of the outcome.
One final way to conceptualize TDT and the difference between the different types of correlation is using structural equation modeling:
Direct causal dependence exists between A and B when A is a function of B or when B is a function of A.
> A = f(B) or B = g(A)
Common cause dependence exists between A and B when A and B are both functions of some other variable C.
> A = f(C) and B = g(C)
Logical dependence exists between A and B when A and B depend on their inputs in similar ways.
> A = f(C) and B = f(D)
TDT takes direct causal dependence and logical dependence seriously, and ignores common cause dependence. We can formally express this by saying that TDT calculates the expected utility of a decision by treating it like a causal intervention and fixing the output of all other instantiations of TDT to be identical interventions. Using Judea Pearl’s do-calculus notation for causal intervention, this looks like:

Here K is the TDT agent’s background knowledge, D is chosen from a set of possible decisions, and the sum is over all possible worlds. This equation isn’t quite right, since it doesn’t indicate what to do when the computation a given system instantiates is merely similar to TDT but not logically identical, but it serves as a first approximation to the algorithm.
You might notice that the notion of logical dependence depends on the idea of logical uncertainty, as without it the result of the computations would be known with certainty as soon as you learn that the calculators came out of a multiplication-factory, without ever having to observe their results. Thus any theory that incorporates logical dependence into its framework will be faced with a problem of logical omniscience, which is to say, it will have to give some account of how to place and update reasonable probability distributions over tautologies.
The upshot of all of this is that TDT is reflectively consistent on a larger class of problems than both EDT and CDT. Both EDT and CDT would self-modify into TDT in Newcomb-like problems if given the choice. Correspondingly, if you throw a bunch of TDTs and EDTs and CDTs into a world full of Newcomb and Newcomb-like problems, the TDTs will come out ahead. However, it turns out that TDT is not itself reflectively consistent on the whole class of decision-determined problems. Examples like the transparent Newcomb problem, Parfit’s hitchhiker, and counterfactual mugging all expose reflective inconsistency in TDT.
Let’s look at the transparent Newcomb problem. The structure is identical to a Newcomb problem (you walk into a room with two boxes, $1000 in one and either $1000000 or $0 in the other, determined based on the behavior of your simulation), except that both boxes are transparent. This means that you already know with certainty the contents of both boxes. CDT two-boxes here like always. EDT also two-boxes, since any dependence between your decision and the box’s contents is made irrelevant as soon as you see the contents. TDT agrees with this line of reasoning; even though it sees a logical dependence between your behavior and your simulation’s behavior, knowing whether the box is full or empty fully screens off this dependence.
Two-boxing feels to many like the obvious rational choice here. The choice you face is simply whether to take $1,000,000 or $1,001,000 if the box is full. If it’s empty, your choice is between taking $1,000 or walking out empty-handed. But two-boxing also has a few strange consequences. For one, imagine that you are placed, blindfolded, in a transparent Newcomb problem. You can at any moment decide to remove your blindfold. If you are an EDT, you will reason that if you don’t remove your blindfold, you are essentially in an ordinary Newcomb problem, so you will one-box and correspondingly walk away with $1,000,000. But if you do remove your blindfold, you’ll end up two-boxing and most likely walking away with only $1000. So an EDT would pay up to $999,000, just for the privilege of staying blindfolded. This seems to conflict with an intuitive principle of rational choice, which goes something like: A rational agent should never expect to be worse off by simply gaining information. Paying money to keep yourself from learning relevant information seems like a sure sign of a pathological decision theory.
Of course, there are two ways out of this. One way is to follow the causal decision theorist and two-box in both the ordinary Newcomb problem and the transparent problem. This has all the issues that we’ve already discussed, most prominently that you end up systematically and predictably worse off by doing so. If you pit a causal decision theorist against an agent that always one-boxes, even in transparent Newcomb problems, CDT ends up the poorer. And since CDT can reason this through beforehand, they would willingly self-modify to become the other type of agent.
What type of agent is this? None of the three decision theories we’ve discussed give the reflectively consistent response here, so we need to invent a new decision theory. The difficulty with any such theory is that it has to be able to justify sticking to its guns and one-boxing even after conditioning on the contents of the box.
In general, similar issues will arise whenever the recommendations made by a decision theory are not time-consistent. For instance, the decision that TDT prescribes for an agent with background knowledge K depends heavily on the information that TDT has at the time of prescription. This means that at different times, TDT will make different recommendations for what to do in the same situation (before entering the room TDT recommends one-boxing once in the room, while after entering the room TDT recommends two-boxing). This leads to suboptimal performance. Agents that can decide on one course of action and credibly precommit to it get certain benefits that aren’t available to agents that don’t have this ability. I think the clearest example of this is Parfit’s hitchhiker:
You are stranded in the desert, running out of water, and soon to die. A Predictor approaches and tells you that they will drive you to town only if they predict you will pay them $100 once you get there.
All of EDT, CDT, and TDT wish that they could credibly precommit to paying the money once in town, but can’t. Once they are in town they no longer have any reason to pay the $100, since they condition on the fact that they . The fact that EDT, CDT, and TDT all have time-sensitive recommendations makes them worse off, leaving them all stranded in the desert to die. Each of these agents would willingly switch to a decision theory that doesn’t change their recommendations over time. How would such a decision theory work? It looks like we need a decision theory that acts as if it doesn’t know whether they’re in town even once in town, and acts as if it doesn’t know the contents of the box even after seeing them. One strategy for achieving this behavior is simple; you just decide on your strategy without ever conditioning on the fact that you are in town!
The decision theory that arises from this choice is appropriately named updateless decision theory (henceforth UDT). UDT is peculiar in that it never actually updates on any information when determining how to behave. That’s not to say that for UDT, the decision you make does not depend on the information you get through your lifetime. Instead, UDT tells you to choose a policy – a mapping from the possible pieces of information you might receive to possible decisions you could make – that maximizes the expected utility, calculated using your prior on possible worlds. This policy is set from time zero and never changes, and it determines how the UDT agent responds to any information they might receive at later points. So, for instance, a UDT agent reasons that adopting a policy of one-boxing in the transparent Newcomb case regardless of what you see maximizes expected utility as calculated using your prior. So once the UDT agent is in the room with the transparent box, it one-boxes. We can formalize this this by analogy with TDT:

One concern with this approach is that a UDT agent might end up making silly decisions as a result of not taking into account information that is relevant to their decisions. But once again, the UDT agent does take into account the information they learn in their lifetime. It’s merely that they decide what to do with that information before receiving it and never update this prescription. For example, suppose that a UDT agent anticipates facing exactly one decision problem in their life, regarding whether to push a button or not. They have a 50% prior credence that pushing the button will result in the loss of $10, and 50% that it will result in gaining $10. Now, at some point before they decide to push the button, they are given the information about whether pushing the button causes you to gain $10 or to lose $10. UDT deals with this by choosing a policy for how to respond to that information in either case. The expected utility maximizing policy here would be to push the button if you learn that pushing the button leads to gaining $10, and to not push the button if you learn the opposite.
Since UDT chooses its preferred policy based on its prior, this recommendation never changes throughout a UDT agent’s lifetime. This seems to indicate that UDT will be self-recommending in the class of all decision-determined problems, although I’m not aware of a full proof of this. If this is correct, then we have reached our goal of finding a self-recommending decision theory. It is interesting to consider what other principles of rational choice ended up being violated along the way. The simple dominance principle that we started off by discussing appears to be an example of this. In the transparent Newcomb problem, there is only one possible world that the agent considers when in the room (the one in which the box is full, say), and in this one world, two-boxing dominates one-boxing. Given that the box is full, your decision to one-box or to two-box is completely independent of the box’s contents. So the simple dominance principle recommends two-boxing. But UDT disagrees.
Another example of a deeply intuitive principle that UDT violates is the irrelevance of impossible outcomes. This principles says that impossible outcomes should not factor into your decision-making process. But UDT seems to often recommend acting as if some impossible world might come to be. For instance, suppose a predictor walks up to you and gives you a choice to either give them $10 or to give them $100. You will not face any future consequences on the basis of your decision (besides whether you’re out $100 or only $10). However, you learn that the predictor only approached you because it predicted that you would give the $10. Do you give the $10 or the $100? UDT recommends giving the $100, because agents that do so are less likely to have been approached by the predictor. But if you’ve already been approached, then you are letting considerations about an impossible world influence your decision process!
Our quest for reflective consistency took us from EDT and CDT to timeless decision theory. TDT used the notion of logical dependence to get self-recommending behavior in the Newcomb problem and medical Newcomb cases. But we found that TDT was itself reflectively inconsistent in problems like the Transparent Newcomb problem. This led us to create a new theory that made its recommendations without updating on information, which we called updateless decision theory. UDT turned out to be a totally static theory, setting forth a policy determining how to respond to all possible bits of information and never altering this policy. The unchanging nature of UDT indicates the possibility that we have found a truly self-recommending decision theory, while also leading to some quite unintuitive consequences.
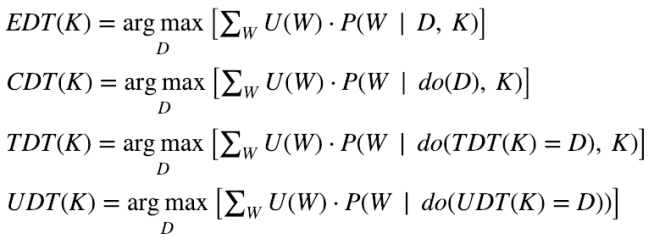
 . The total amount of product on the market will be given the label
. The total amount of product on the market will be given the label 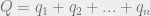 . Since the firms are all selling identical products, it makes sense to assume that the consumer demand function
. Since the firms are all selling identical products, it makes sense to assume that the consumer demand function  will just be a function of the total quantity of the product that is on the market:
will just be a function of the total quantity of the product that is on the market: 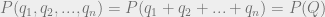 . (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)
. (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)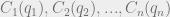 . Now we can figure out the profit of each firm for a given set of output values
. Now we can figure out the profit of each firm for a given set of output values  . This profit is just the amount of money they get by selling the product minus the cost of producing the product:
. This profit is just the amount of money they get by selling the product minus the cost of producing the product:  .
. . This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms!
. This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms! and
and 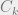 , we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.
, we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.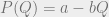 (for some a and b) and
(for some a and b) and  . As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
. As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
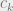 represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.)
represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.) . Rewriting, we get
. Rewriting, we get  . We can’t immediately solve this for
. We can’t immediately solve this for  , because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!
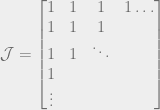
, because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!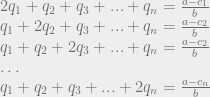






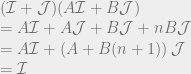


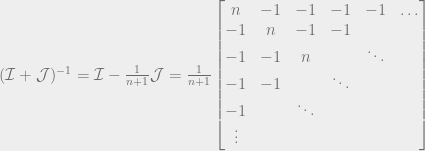
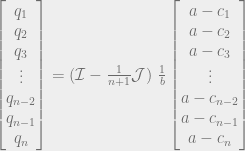
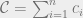
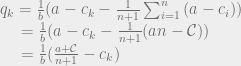
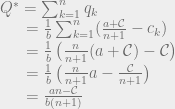
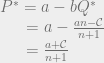



 intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity
intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity  , the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
, the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
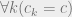

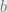 ) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!
) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!