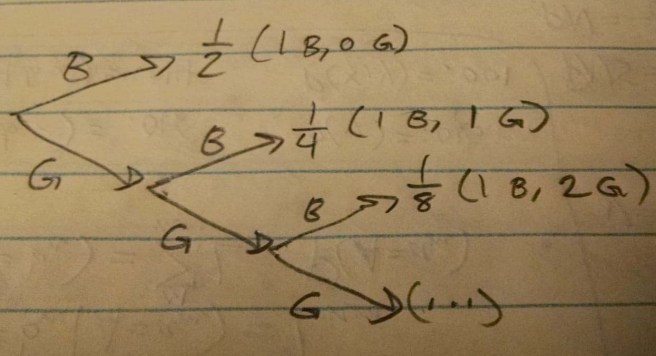An alternative history interaction between Galileo and his famous statistician friend
***
In the year 1609, when Galileo Galilei finished the construction of his majestic artificial eye, the first place he turned his gaze was the glowing crescent moon. He reveled in the crevices and mountains he saw, knowing that he was the first man alive to see such a sight, and his mind expanded as he saw the folly of the science of his day and wondered what else we might be wrong about.
For days he was glued to his telescope, gazing at the Heavens. He saw the planets become colorful expressive spheres and reveal tiny orbiting companions, and observed the distant supernova which Kepler had seen blinking into existence only five years prior. He discovered that Venus had phases like the Moon, that some apparently single stars revealed themselves to be binaries when magnified, and that there were dense star clusters scattered through the sky. All this he recorded in frantic enthusiastic writing, putting out sentences filled with novel discoveries nearly every time he turned his telescope in a new direction. The universe had opened itself up to him, revealing all its secrets to be uncovered by his ravenous intellect.
It took him two weeks to pull himself away from his study room for long enough to notify his friend Bertolfo Eamadin of his breakthrough. Eamadin was a renowned scholar, having pioneered at age 15 his mathematical theory of uncertainty and created the science of probability. Galileo often sought him out to discuss puzzles of chance and randomness, and this time was no exception. He had noticed a remarkable confluence of three stars that were in perfect alignment, and needed the counsel of his friend to sort out his thoughts.
Eamadin arrived at the home of Galileo half-dressed and disheveled, obviously having leapt from his bed and rushed over immediately upon receiving Galileo’s correspondence. He practically shoved Galileo out from his viewing seat and took his place, eyes glued with fascination on the sky.
Galileo allowed his friend to observe unmolested for a half-hour, listening with growing impatience to the ‘oohs’ and ‘aahs’ being emitted as the telescope swung wildly from one part of the sky to another. Finally, he interrupted.
Galileo: “Look, friend, at the pattern I have called you here to discuss.”
Galileo swiveled the telescope carefully to the position he had marked out earlier.
Eamadin: “Yes, I see it, just as you said. The three stars form a seemingly perfect line, each of the two outer ones equidistant from the central star.”
Galileo: “Now tell me, Eamadin, what are the chances of observing such a coincidence? One in a million? A billion?”
Eamadin frowned and shook his head. “It’s certainly a beautiful pattern, Galileo, but I don’t see what good a statistician like myself can do for you. What is there to be explained? With so many stars in the sky, of course you would chance upon some patterns that look pretty.”
Galileo: “Perhaps it seems only an attractive configuration of stars spewed randomly across the sky. I thought the same myself. But the symmetry seemed too perfect. I decided to carefully measure the central angle, as well as the angular distance distended by the paths from each outer star to the central one. Look.”
Galileo pulled out a sheet of paper that had been densely scribbled upon. “My calculations revealed the central angle to be precisely 180.000º, with an error of ± .003º. And similarly, I found the difference in the two angular distances to be .000º, with a margin of error of ± .002º.”
Eamadin: “Let me look at your notes.”
Galileo handed over the sheets to Eamadin. “I checked over my calculations a dozen times before writing you. I found the angular distances by approaching and retreating from this thin paper, which I placed between the three stars and me. I found the distance at which the thin paper just happened to cover both stars on one extreme simultaneously, and did the same for the two stars on the other extreme. The distance was precisely the same, leaving measurement error only for the thickness of the paper, my distance from it, and the resolution of my vision.”
Eamadin: “I see, I see. Yes, what you have found is a startlingly clear pattern. A similarity in distance and precision of angle this precise is quite unlikely to be the result of any natural phenomenon… ”
Galileo: “Exactly what I thought at first! But then I thought about the vast quantity of stars in the sky, and the vast number of ways of arranging them into groups of three, and wondered if perhaps in fact such coincidences might be expected. I tried to apply your method of uncertainty to the problem, and came to the conclusion that the chance of such a pattern having occurred through random chance is one in a thousand million! I must confess, however, that at several points in the calculation I found myself confronted with doubt about how to progress and wished for your counsel.”
Eamadin stared at Galileo’s notes, then pulled out a pad of his own and began scribbling intensely. Eventually, he spoke. “Yes, your calculations are correct. The chance of such a pattern having occurred to within the degree of measurement error you have specified by random forces is 10-9.”
Galileo: “Aha! Remarkable. So what does this mean? What strange forces have conspired to place the stars in such a pattern? And, most significantly, why?”
Eamadin: “Hold it there, Galileo. It is not reasonable to jump from the knowledge that the chance of an event is remarkably small to the conclusion that it demands a novel explanation.”
Galileo: “How so?”
Eamadin: “I’ll show you by means of a thought experiment. Suppose that we found that instead of the angle being 180.000º with an experimental error of .003º, it was 180.001º with the same error. The probability of this outcome would be the same as the outcome we found – one in a thousand million.”
Galileo: “That can’t be right. Surely it’s less likely to find a perfectly straight line than a merely nearly perfectly straight line.”
Eamadin: “While that is true, it is also true that the exact calculation you did for 180.000º ± .003º would apply for 180.001º ± .003º. And indeed, it is less likely to find the stars at this precise angle, than it is to find the stars merely near this angle. We must compare like with like, and when we do so we find that 180.000º is no more likely than any other angle!”
Galileo: “I see your reasoning, Eamadin, but you are missing something of importance. Surely there is something objectively more significant about finding an exactly straight line than about a nearly straight line, even if they have the same probability. Not all equiprobable events should be considered to be equally important. Think, for instance, of a sequence of twenty coin tosses. While it’s true that the outcome HHTHTTTTHTHHHTHHHTTH has the same probability as the outcome HHHHHHHHHHHHHHHHHHHH, the second is clearly more remarkable than the first.”
Eamadin: “But what is significance if disentangled from probability? I insist that the concept of significance only makes sense in the context of my theory of uncertainty. Significant results are those that either have a low probability or have a low conditional probability given a set of plausible hypotheses. It is this second class that we may utilize in analyzing your coin tossing example, Galileo. The two strings of tosses you mention are only significant to different degrees in that the second more naturally lends itself to a set of hypotheses in which the coin is heavily biased towards heads. In judging the second to be a more significant result than the first, you are really just saying that you use a natural hypothesis class in which probability judgments are only dependent on the ratios of heads and tails, not the particular sequence of heads and tails. Now, my question for you is: since 180.000º is just as likely as 180.001º, what set of hypotheses are you considering in which the first is much less likely than the second?”
Galileo: “I must confess, I have difficulty answering your question. For while there is a simple sense in which the number of heads and tails is a product of a coin’s bias, it is less clear what would be the analogous ‘bias’ in angles and distances between stars that should make straight lines and equal distances less likely than any others. I must say, Eamadin, that in calling you here, I find myself even more confused than when I began!”
Eamadin: “I apologize, my friend. But now let me attempt to disentangle this mess and provide a guiding light towards a solution to your problem.”
Galileo: “Please.”
Eamadin: “Perhaps we may find some objective sense in which a straight line or the equality of two quantities is a simpler mathematical pattern than a nearly straight line or two nearly equal quantities. But even if so, this will only be a help to us insofar as we have a presumption in favor of less simple patterns inhering in Nature.”
Galileo: “This is no help at all! For surely the principle of Ockham should push us towards favoring more simple patterns.”
Eamadin: “Precisely. So if we are not to look for an objective basis for the improbability of simple and elegant patterns, then we must look towards the subjective. Here we may find our answer. Suppose I were to scribble down on a sheet of paper a series of symbols and shapes, hidden from your view. Now imagine that I hand the images to you, and you go off to some unexplored land. You explore the region and draw up cartographic depictions of the land, having never seen my images. It would be quite a remarkable surprise were you to find upon looking at my images that they precisely matched your maps of the land.”
Galileo: “Indeed it would be. It would also quickly lend itself to a number of possible explanations. Firstly, it may be that you were previously aware of the layout of the land, and drew your pictures intentionally to capture the layout of the land – that is, that the layout directly caused the resemblance in your depictions. Secondly, it could be that there was a common cause between the resemblance and the layout; perhaps, for instance, the patterns that most naturally come to the mind are those that resemble common geographic features. And thirdly, included only for completion, it could be that your images somehow caused the land to have the geographic features that it did.”
Eamadin: “Exactly! You catch on quickly. Now, this case of the curious coincidence of depiction and reality is exactly analogous to your problem of the straight line in the sky. The straight lines and equal distances are just like patterns on the slips of paper I handed to you. For whatever reason, we come pre-loaded with a set of sensitivities to certain visual patterns. And what’s remarkable about your observation of the three stars is that a feature of the natural world happens to precisely align with these patterns, where we would expect no such coincidence to occur!”
Galileo: “Yes, yes, I see. You are saying that the improbability doesn’t come from any objective unusual-ness of straight lines or equal distances. Instead, the improbability comes from the fact that the patterns in reality just happen to be the same as the patterns in my head!”
Eamadin: “Precisely. Now we can break down the suitable explanations, just as you did with my cartographic example. The first explanation is that the patterns in your mind were caused by the patterns in the sky. That is, for some reason the fact that these stars were aligned in this particular way caused you to by psychologically sensitive to straight lines and equal quantities.”
Galileo: “We may discard this explanation immediately, for such sensitivities are too universal and primitive to be the result of a configuration of stars that has only just now made itself apparent to me.”
Eamadin: “Agreed. Next we have a common cause explanation. For instance, perhaps our mind is naturally sensitive to visual patterns like straight lines because such patterns tend to commonly arise in Nature. This natural sensitivity is what feels to us on the inside as simplicity. In this case, you would expect it to be more likely for you to observe simple patterns than might be naively thought.”
Galileo: “We must deny this explanation as well, it seems to me. For the resemblance to a straight line goes much further than my visual resolution could even make out. The increased likelihood of observing a straight line could hardly be enough to outweigh our initial naïve calculation of the probability being 10-9. But thinking more about this line of reasoning, it strikes me that you have just provided an explanation the apparent simplicity of the laws of Nature! We have developed to be especially sensitive to patterns that are common in Nature, we interpret such patterns as ‘simple’, and thus it is a tautology that we will observe Nature to be full of simple patterns.”
Eamadin: “Indeed, I have offered just such an explanation. But it is an unsatisfactory explanation, insofar as one is opposed to the notion of simplicity as a purely subjective feature. Most people, myself included, would strongly suggest that a straight line is inherently simpler than a curvy line.”
Galileo: “I feel the same temptation. Of course, justifying a measure of simplicity that does the job we want of it is easier said than done. Now, on to the third explanation: that my sensitivity to straight lines has caused the apparent resemblance to a straight line. There are two interpretations of this. The first is that the stars are not actually in a straight line, and you only think this because of your predisposition towards identifying straight lines. The second is that the stars aligned in a straight line because of these predispositions. I’m sure you agree that both can be reasonably excluded.”
Eamadin: “Indeed. Although it may look like we’ve excluded all possible explanations, notice that we only considered one possible form of the common cause explanation. The other two categories of explanations seem more thoroughly ruled out; your dispositions couldn’t be caused by the star alignment given that you have only just found out about it and the star alignment couldn’t be caused by your dispositions given the physical distance.”
Galileo: “Agreed. Here is another common cause explanation: God, who crafted the patterns we see in Nature, also created humans to have similar mental features to Himself. These mental features include aesthetic preferences for simple patterns. Thus God causes both the salience of the line pattern to humans and the existence of the line pattern in Nature.”
Eamadin: “The problem with this is that it explains too much. Based solely on this argument, we would expect that when looking up at the sky, we should see it entirely populated by simple and aesthetic arrangements of stars. Instead it looks mostly random and scattershot, with a few striking exceptions like those which you have pointed out.”
Galileo: “Your point is well taken. All I can imagine now is that there must be some sort of ethereal force that links some stars together, gradually pushing them so that they end up in nearly straight lines.”
Eamadin: “Perhaps that will be the final answer in the end. Or perhaps we will discover that it is the whim of a capricious Creator with an unusual habit for placing unsolvable mysteries in our paths. I sometimes feel this way myself.”
Galileo: “I confess, I have felt the same at times. Well, Eamadin, although we have failed to find a satisfactory explanation for the moment, I feel much less confused about this matter. I must say, I find this method of reasoning by noticing similarities between features of our mind and features of the world quite intriguing. Have you a name for it?”
Eamadin: “In fact, I just thought of it on the spot! I suppose that it is quite generalizable… We come pre-loaded with a set of very salient and intuitive concepts, be they geometric, temporal, or logical. We should be surprised to find these concepts instantiated in the world, unless we know of some causal connection between the patterns in our mind and the patterns in reality. And by Eamadin’s rule of probability-updating, when we notice these similarities, we should increase our strength of belief in these possible causal connections. In the spirit of anachrony, let us refer to this as the Schelling point improbability principle!”
Galileo: “Sounds good to me! Thank you for your assistance, my friend. And now I must return to my exploration of the Cosmos.”










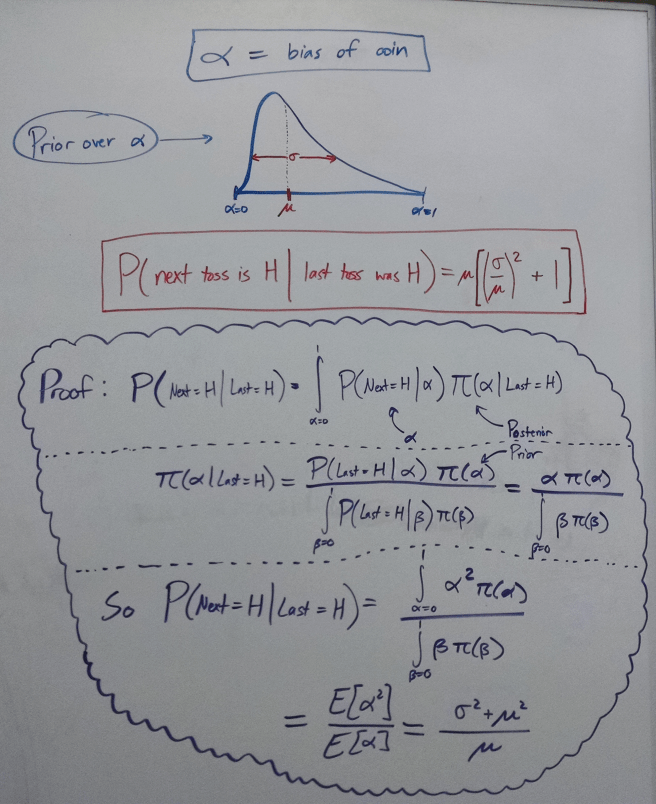
 ) get a weaker update from evidence.
) get a weaker update from evidence. is a constant across models, we can ignore it when comparing models. So for our purposes, we can attempt to maximize the equation:
is a constant across models, we can ignore it when comparing models. So for our purposes, we can attempt to maximize the equation: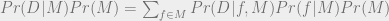

![argmax_M [ Pr(M | D) ] \\~\\ = argmax_M [ Pr(D | M) Pr(M) ] \\~\\ \approx argmax_M [ \frac {Pr(D | f^*(D))} {\sqrt{N}}^k Pr(M)] \\~\\ = argmax_M [ \log(Pr(M)) + \log (Pr(D | f^*(D)) - \frac{k}{2} \log(N) ] \\~\\ = argmin_M [ BIC - \log Pr(M) ]](https://s0.wp.com/latex.php?latex=argmax_M+%5B+Pr%28M+%7C+D%29+%5D+%5C%5C%7E%5C%5C++%3D+argmax_M+%5B+Pr%28D+%7C+M%29+Pr%28M%29+%5D+%5C%5C%7E%5C%5C++%5Capprox+argmax_M+%5B+%5Cfrac+%7BPr%28D+%7C+f%5E%2A%28D%29%29%7D%C2%A0%7B%5Csqrt%7BN%7D%7D%5Ek+Pr%28M%29%5D+%5C%5C%7E%5C%5C++%3D+argmax_M+%5B+%5Clog%28Pr%28M%29%29+%2B+%5Clog+%28Pr%28D+%7C+f%5E%2A%28D%29%29+-+%5Cfrac%7Bk%7D%7B2%7D+%5Clog%28N%29+%5D+%5C%5C%7E%5C%5C++%3D+argmin_M+%5B+BIC+-+%5Clog+Pr%28M%29+%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)

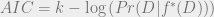



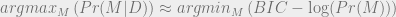 ? Well, just set
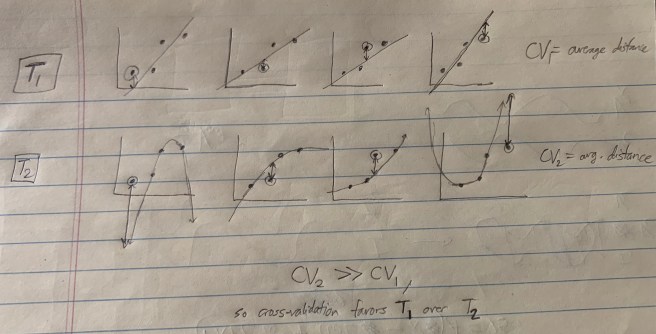
? Well, just set  , and you get the desired result.) Interestingly, this prior ends up rewarding theories for having lots of parameters! This looks pretty bad… it seems like AIC is what you get when you take Bayesian Model Selection and then try to choose a prior that favors overfitting theories. But the practical use and theoretical virtues of AIC warrant, in my opinion, taking a closer look at what’s going on here. Perhaps what’s going on is that the likelihood term Pr(D | M) is actually doing too much to avoid overfitting, so in the end what we need in our prior is one that avoids underfitting! Regardless, we can think of AIC as specifying the unique good prior on models that optimizes for predictive accuracy.
, and you get the desired result.) Interestingly, this prior ends up rewarding theories for having lots of parameters! This looks pretty bad… it seems like AIC is what you get when you take Bayesian Model Selection and then try to choose a prior that favors overfitting theories. But the practical use and theoretical virtues of AIC warrant, in my opinion, taking a closer look at what’s going on here. Perhaps what’s going on is that the likelihood term Pr(D | M) is actually doing too much to avoid overfitting, so in the end what we need in our prior is one that avoids underfitting! Regardless, we can think of AIC as specifying the unique good prior on models that optimizes for predictive accuracy. , where each
, where each 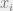 is a value that you choose (your independent variable) and each
is a value that you choose (your independent variable) and each 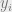 is the resulting value that you measure (the dependent variable). Each of these variables can be pretty much anything – real numbers, n-tuples of real numbers, integers, colors, whatever you want. The goal here is to embrace generality, so as to have a framework that applies to many kinds of inference.
is the resulting value that you measure (the dependent variable). Each of these variables can be pretty much anything – real numbers, n-tuples of real numbers, integers, colors, whatever you want. The goal here is to embrace generality, so as to have a framework that applies to many kinds of inference. We interpret T as making a prediction of a particular value of the dependent variable for each value of the independent variable. Maybe the data is the temperatures of regions at various altitudes, and our theory T says that one over the temperature (1/T) is some particular linear function of the altitude.
We interpret T as making a prediction of a particular value of the dependent variable for each value of the independent variable. Maybe the data is the temperatures of regions at various altitudes, and our theory T says that one over the temperature (1/T) is some particular linear function of the altitude. and the predicted value of y at that point:
and the predicted value of y at that point:  , using some metric, then adding them all up. But there are a whole bunch of distance metrics available to us. Which one should we use? Perhaps the taxicab measure comes to mind (
, using some metric, then adding them all up. But there are a whole bunch of distance metrics available to us. Which one should we use? Perhaps the taxicab measure comes to mind ( ), or the sum of the squares of the differences (
), or the sum of the squares of the differences ( ). We want a good theoretical justification for why any one of these metrics should be preferred over any other, since in general they lead to different conclusions. We’ll see just such justifications shortly. Keep the equation for SOS in mind, as it will turn up repeatedly ahead.
). We want a good theoretical justification for why any one of these metrics should be preferred over any other, since in general they lead to different conclusions. We’ll see just such justifications shortly. Keep the equation for SOS in mind, as it will turn up repeatedly ahead. the observed
the observed  , where
, where  is some random variable drawn from a probability distribution
is some random variable drawn from a probability distribution  .
.
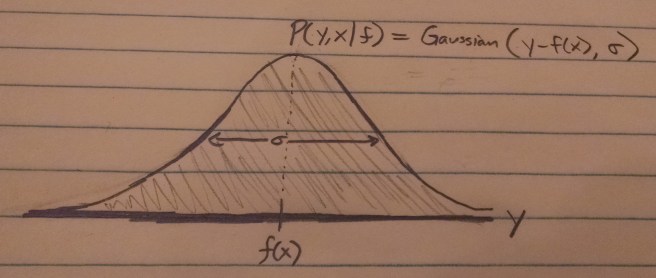
 denotes a random variable drawn from a Gaussian distribution centered around
denotes a random variable drawn from a Gaussian distribution centered around  with a standard deviation of
with a standard deviation of  .
.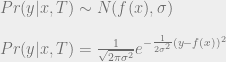
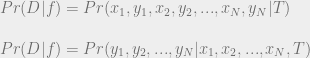
 . But that would require an assumption that our data points are independent. In general, we cannot grant this assumption. But what we can do is expand our theory once more to include a theory of the dependencies in our data points. For simplicity of explication, let’s proceed with the assumption that each of our observations is independent of the others. Said another way, we assume that given T,
. But that would require an assumption that our data points are independent. In general, we cannot grant this assumption. But what we can do is expand our theory once more to include a theory of the dependencies in our data points. For simplicity of explication, let’s proceed with the assumption that each of our observations is independent of the others. Said another way, we assume that given T, 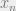 screens off all other variables from
screens off all other variables from 
![f^*(D) = argmax_f [ Pr(D | f) ]](https://s0.wp.com/latex.php?latex=f%5E%2A%28D%29+%3D+argmax_f+%5B+Pr%28D+%7C+f%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
![argmax_f [Pr(D | F)] = argmax_f \left[ e^{-\frac{SOS(f, D)}{2 \sigma^2} } \right] = argmax_f \left[-\frac{SOS(f, D)}{2 \sigma^2} \right] = argmin_f [ SOS(f, D) ]](https://s0.wp.com/latex.php?latex=argmax_f+%5BPr%28D+%7C+F%29%5D+%3D+argmax_f+%5Cleft%5B+e%5E%7B-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%7D+%5Cright%5D+%3D+argmax_f+%5Cleft%5B-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+%3D+argmin_f+%5B+SOS%28f%2C+D%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

![f^*(D) = argmax_f [ Pr(f | D) ]](https://s0.wp.com/latex.php?latex=f%5E%2A%28D%29+%3D+argmax_f+%5B+Pr%28f+%7C+D%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

![argmax_f [ Pr(f | D) ] = argmax_f [ Pr(D | f) Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmax_f [ \log Pr(D | f) + \log Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmax_f [ -\frac{SOS(f, D)}{2 \sigma^2} + \log Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmin_f [ SOS(f, D) - 2 \sigma^2 \log Pr(f) ]](https://s0.wp.com/latex.php?latex=argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+Pr%28D+%7C+f%29+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+%5Clog+Pr%28D+%7C+f%29+%2B+%5Clog+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%2B+%5Clog+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmin_f+%5B+SOS%28f%2C+D%29+-+2+%5Csigma%5E2+%5Clog+Pr%28f%29+%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
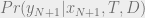 , where
, where  is a future data point. But there are two big problems with this.
is a future data point. But there are two big problems with this. has,
has,