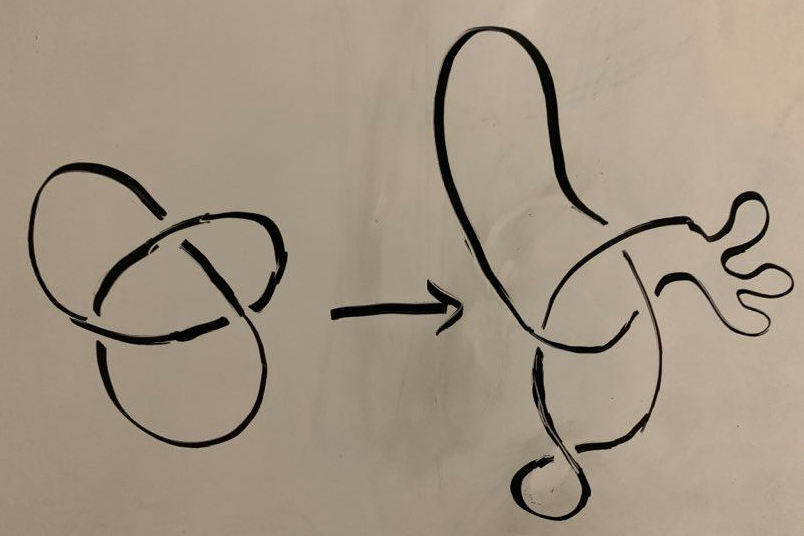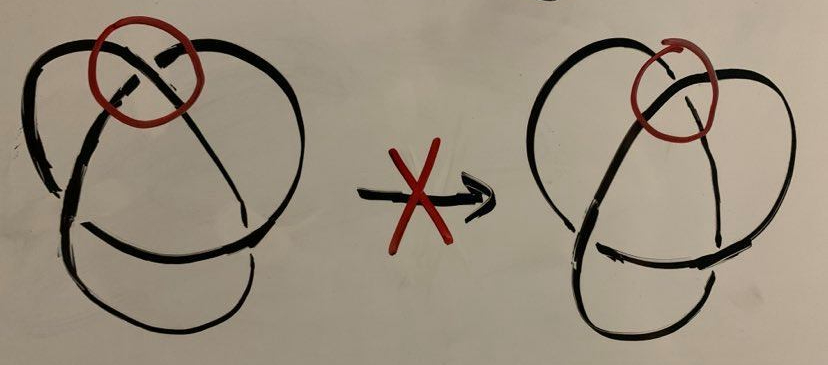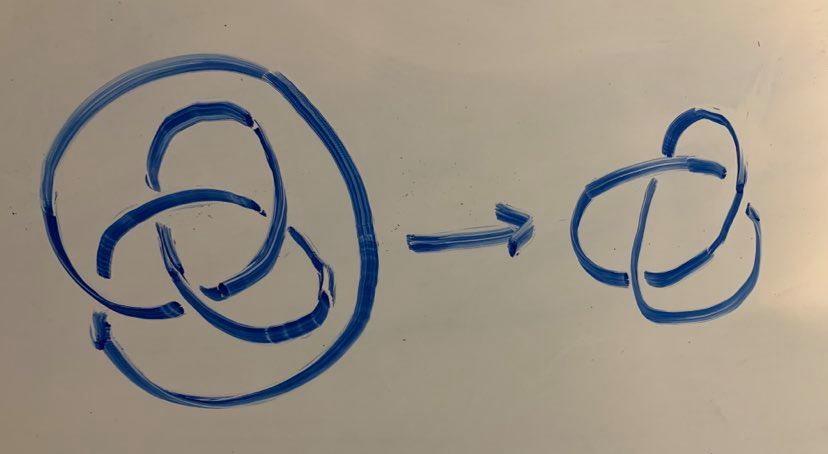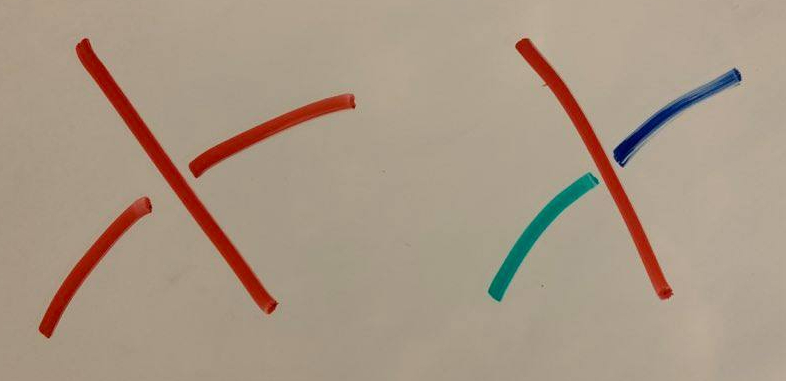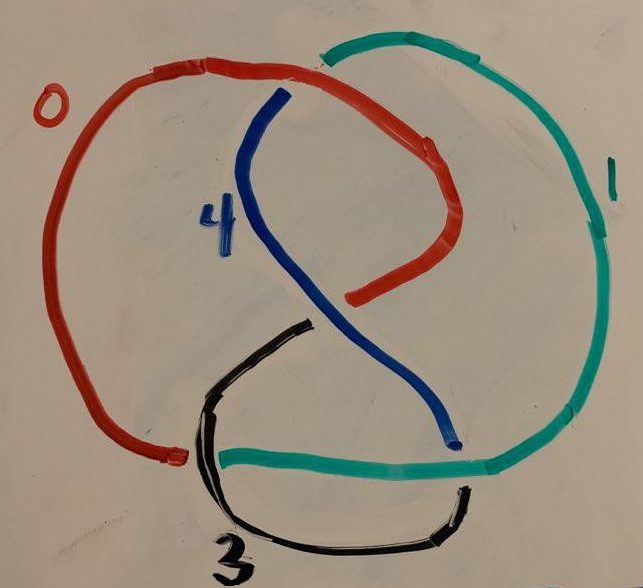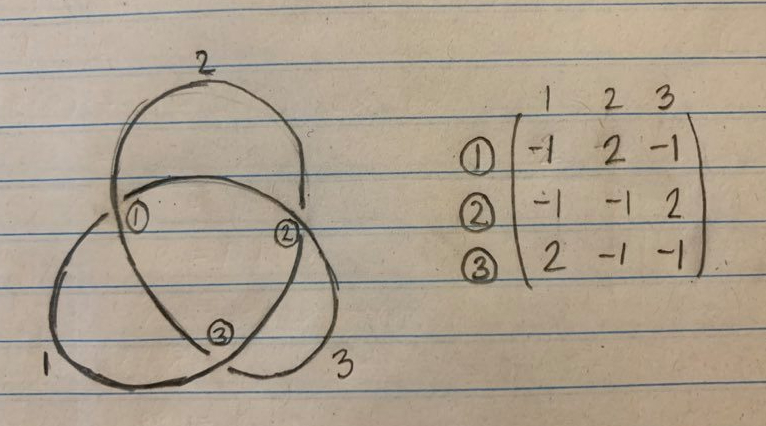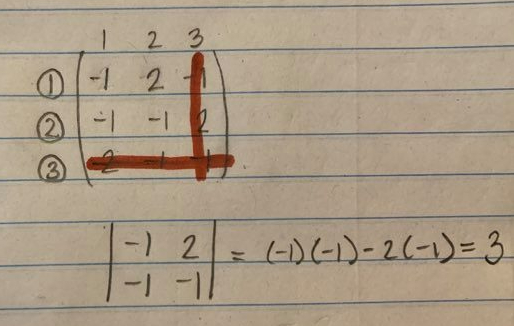Credit to Joel David Hamkins, who I heard discussing this paradox on an episode of the podcast My Favorite Theorem.
Define a finite game to be any two-player turn-based game such that every possible playthrough ends after finitely many turns. For example, tic-tac-toe is a finite game because every game ends in at most nine turns.. So is chess with the 50-move-rule enforced (if 50 moves are taken without any pawn advances or captures, then the game ends in a draw). In both these examples, there’s an upper bound to how long the game can last, but this is not required. A game of transfinite Nim would count as finite; every game lasts for only finitely many turns, even though there is no upper bound on the number of turns it takes.
Now, consider the game Hypergame. To play Hypergame, Player 1 begins by choosing any finite game G. Then Player 2 plays the first move of G, Player 1 plays the second move of G, and so on until the game is completed. (Since Player 1 chose a finite game, this will always happen after some finite amount of time.)
Is Hypergame a finite game? Yes, we can easily see that it must be. Whatever game Player 1 chooses will be over after n steps, for some finite n. So that playthrough of Hypergame will have taken n+1 steps.
But if Hypergame is a finite game, then it is a valid choice for the first move of Hypergame! So we can now imagine the following playthrough of Hypergame:
A Troubling Playthrough of Hypergame Player 1: For the finite game that we shall play, I pick Hypergame. Player 2: Hm, okay. So now I’m playing the first move of Hypergame. So I must now choose any finite game. I’ll choose Hypergame! Player 1: Alright so I’m again playing the first move of this new game of Hypergame. I’ll choose Hypergame again. Player 2: And I choose Hypergame again as well. So on forever…
At no point does either player violate the rules of Hypergame. And yet, we ended up with an infinite playthrough of Hypergame, which we proved was impossible! So we have a contradiction. What is the resolution?
✵✵✵
Here’s one possible resolution, analogous to the resolutions of similar set-theoretic paradoxes.
We can think about a game as a directed rooted tree. The vertices of the tree correspond to game states, and the edges correspond to the allowed moves. The root of the tree corresponds to the starting game state, and Player 1 gets to choose which edge to travel along first. From the new vertex, Player 2 decides the next edge to travel along. And so on. The tree’s leaves correspond to ending states of the game, and each leaf is labelled according to which player won in that ending state.
In this framework, what is a finite game? As I defined it above, a finite game is just any directed rooted tree such that every path starting at the root ends at a leaf after passing through finitely many edges. This corresponds perfectly to the idea that every possible playthrough of the game takes only finitely many turns. Notice that a finite game is not necessarily a finite tree! The game tree of a finite game is only finite if it’s also finitely branching. In other words, for a game to have a finite tree requires not just that every playthrough is finitely long, but that each player always has only finitely many choices on their turn.
For instance, the game tree of Hypergame is not a finite tree, because Player 1 has infinitely many possible finite games to choose from on his first turn. How big exactly is the game tree of Hypergame? We know that we have to have a vertex corresponding to the start of any finite game, so it must be at least as large as the set of all finite games. But how large is this set?
This is where we run into problems. The game tree of a finite game can be arbitrarily large. Consider the game which starts by Player 1 choosing any real number and then immediately losing. The height of the game tree is 1, but its width is the cardinality of the continuum. Similarly for any set X we can find a game whose tree has cardinality |X|. This means that there are finite games of arbitrary cardinalities. But then as a corollary to the nonexistence of a largest cardinality, we know that there is no set of all finite games! And this implies that Hypergame has no game tree! More precisely, there is no set corresponding to the game tree of Hypergame as we defined it.
Couldn’t we instead think about Hypergame as a proper class? Sure! But then when we choose a finite game in our first move, we couldn’t be picking Hypergame, as the property “is a finite game” would only apply to sets and not proper classes. This means that we can’t actually select Hypergame as our first move! And so we avoid the paradoxical conclusion that we can keep picking Hypergame ad infinitum.
I find it quite fascinating that the seemingly innocent notion of a finite game can lead us into paradoxes involving proper classes!
To each atomic proposition P assign a natural number p. If that natural number is even, then its corresponding proposition is true. If the number is odd then the proposition is false.
If you have two numbers n and m and you multiply them, the result is even so long as either n or m is even. So multiplication is like or; P∨Q corresponds to pq.
Negation is like adding 1: even becomes odd and odd becomes even. So ¬P corresponds to p+1.
Consider addition: p+q is even if p and q are both even or both odd. So p+q is like the biconditional ↔.
Other connectives can be formed out of these. Take P∧Q: P∧Q is equivalent to ¬(¬P∨¬Q), which is (p+1)(q+1) + 1. So P∧Q corresponds to pq+p+q+2. P→Q is ¬P∨Q, which is (p+1)q.
The logical constants ⊤ and ⊥ correspond to numerical constants: ⊤ can be assigned 0 and ⊥ assigned 1, for instance.
Tautologies translate to algebraic expressions which are always even. For instance, P→P translates to (p+1)p, which is always even. P→(Q→P) translates to (p+1)(q+1)p, which is also always even. P∨¬P translates to p(p+1), always even.
Contradictions translate to algebraic expressions which are always odd. P∧¬P translates to (p+1)(p+2) + 1, which is always odd. And so on.
Inference rules can be understood as saying: if all the premises are even, then the conclusion will be even. Take conjunction elimination: P∧Q ⊨ P. This says that if (p+1)(q+1) + 1 is even then p is even, which ends up being right if you work it out. Modus ponens: P, P→Q ⊨ Q. This says that if p and (p+1)q are both even, then q is even. Again works out!
You can also work the other way: For any number p, p(p+1) is even. Translating into propositional logic, this says that P∨¬P is a tautology. We’ve proved the law of the excluded middle! It’s interesting to note that earlier we saw that P→P translates to (p+1)p. So in some sense the law of the excluded middle is just self-implication but with the two products reversed!
A group of six men (A, B, C, D, E, and F) and six women (a, b, c, d, e, and f) are chosen so that everybody has a perfect match of the opposite gender. They are given the following clues:
If they can figure out everybody’s perfect matches, the group will get a million dollars to share! Can they figure it out?
If you figure that one out, then here’s the next level, with ten pairs and twelve clues!
A group of ten men (ABCDEFGHIJ) and ten women (abcdefghij) are chosen so that everybody has a perfect match of the opposite gender. They are given the following twelve clues:
F and f are not a match
J and h are not a match
B and e are not a match
D and d are a match
H and c are a match
The pairing (Ai Bb Ca Dd Ee Fc Gj Hg If Jh) contains exactly 2 matches.
The pairing (Af Be Cg Dj Eh Fd Gi Hc Ia Jb) contains exactly 4 matches.
The pairing (Af Be Ca Dd Ej Fh Gi Hb Ig Jc) contains exactly 2 matches.
The pairing (Aa Bc Ci Dd Eg Fj Gf Hb Ih Je) contains exactly 2 matches.
The pairing (Af Bi Ce Dd Eh Fg Gj Hc Ia Jb) contains exactly 5 matches.
The pairing (Af Ba Cb Dd Eh Fi Gj Hc Ie Jg) contains exactly 5 matches.
The pairing (Af Bi Ch Dd Eb Fg Gj Hc Ia Je) contains exactly 7 matches.
Can you help them get their million dollars?
✯✯✯
Some background on the puzzle:
I didn’t actually come up with it out of nowhere, I encountered in the wild! A few days ago I started watching a new Netflix reality show called “Are You The One?” The premise of the show: ten men and ten women are paired up via a matchmaking algorithm, and if they can all figure out their other halves after living together for a month, then they win one million dollars. It’s an extremely corny show, but there was one aspect of it which I found pretty interesting: it’s a perfect setting for Bayesian experimental design! Me being me, I spent the whole show thinking about the math of how contestants get information about their potential “perfect matches”.
Let’s start with a very basic look at the underlying math. Ten pairs, chosen from two groups of ten, gives ten factorial possible matchings. 10! is 3,628,800, which is a lot of possibilities. If you were to randomly choose the ten matches, with no background information, you’d have a .000028% chance of getting everything right. This is about as likely as you are to correctly guess the outcome of 22 tosses of an unbiased coin in a row!
Of course, the show isn’t so cruel as to force them to just guess with no information. For one thing, they have a whole month to get to know each other and gather lots of that subtle tricky-to-quantify social evidence. But more importantly, every episode they get two crucial pieces of information:
First, they get to choose one pair (a man and a woman) to go into the “Truth Booth”. The group is then informed whether these two are a genuine match or not.
And second, at the end of each episode the entire group gathers together, everybody pairs off with one another, and they are told how many pairs they got right (though not which ones). On the final episode, the matching they choose determines whether they get the million dollars or not.
I call the first type of test the individual pair test and the second the group test. And this is where the two types of clues in the above puzzles come from! The clues for the second puzzle are actually just a translation of the tests that the group decided to do in the first seven episodes. (So if you successfully solved it, then feel good about yourself for being the type of person that would have won the million.) Interestingly, it turns out that by the seventh episode they could had already figured out everybody’s perfect match, but it took them three more episodes to get to that point! Silly non-logically-omniscient humans.
Putting aside the puzzle we started with, the show setup naturally lends itself to some interesting questions. First of all, is there a strategy that guarantees that the group will get the million dollars by the tenth episode? In other words, is ten pair tests and nine group tests sufficient to go from 3,628,800 possibilities to 1?
I am not yet sure of the answer. The fact that the group in season one managed to narrow it down to a single possible world with only seven episodes seems like evidence that yes, those 19 tests do provide enough evidence. In addition, there have been eight seasons and in only one did the group fail to find the correct matches. (And in the season whose group failed, they started with eleven pairs – multiplying the number of possible worlds by 11 – and used two fewer pair tests than previous seasons.)
However, it’s worth keeping in mind that while the group of twenty individuals was far from logically omniscient, they did have a great wealth of additional social evidence, and that evidence may have allowed them to make choices for their tests that yielded much more expected information than the optimal test in the absence of social information. (I’m also suspicious that the producers might be a little more involved in the process than they seem. There are a few seasons where the group is consistently getting 2 or 3 matches until the last episode where they suddenly get everything right. This happens in season 3, and by my calculations there were still four possible worlds consistent with all their information by the time of the last matching ceremony!)
We can also ask the Bayesian experimental design question. What’s the optimal pair test/group test to perform, given the set of remaining possible worlds?
We can solve this fairly easily using a brute force approach. Consider the problem of finding the optimal pair test. First we actually generate the set of all possible worlds (where each world is a specification of all ten matches). Let N be the size of this set. Then we look through all possible pairs of individuals (i, j), and for each pair calculate the number of worlds in which this pair is a match. Call this quantity nij. Then the expected number of worlds remaining after performing a pair test on (i, j) is:
nij Pr(i and j are a match) + (N – nij) Pr(i and j are not a match) = nij2/N+ (N – nij)2/N
So we simply search for the pair (i, j) that minimizes nij2 + (N – nij)2. This is equivalent to maximizing nij (N – nij): the product of the number of worlds where (i, j) is a match and the number of worlds where (i, j) is not a match.
We do pretty much the same thing for the group test. But here’s where we run into a bit of trouble: though our algorithm is guaranteed to return an optimal test, the brute force approach has to search through 10!10! possibilities, and this is just not feasible. The time taken to solve the problem grows exponentially in the number of worlds, which grows exponentially in the number of individuals.
So we have another interesting question on our hands: Is there an efficient algorithm for calculating the optimal pair/group test? In the more general setting, where the tests are not restricted to just being pair tests or group tests, but can be a test of ANY boolean expression, this is the question of whether SAT can be solved efficiently. And given that SAT is known to be NP-complete (it was in fact the first problem to be proven NP-complete!), this more general question ends up being equivalent to whether P = NP!
Try to answer the question in the title for yourself. An election has n votes for candidate A, m votes for candidate B, and no third candidate. Candidate A wins, so n > m. Assuming that the votes were equally likely to be counted in any order, what’s the probability that candidate A was always ahead? (Note that “always ahead” precludes the vote being tied at any point.)
My friend showed me this puzzle a couple of days ago and told me that there’s an extremely simple way to solve it. After trying a bunch of complicated things (including some wild Pascal’s triangle variants), I eventually relented and asked for the simple solution. Not only is there a short proof of the answer, but the answer is itself incredibly simple and elegant. See if you can do better than I did!
(…)
(…)
(…)
(Read on only after you’ve attempted the problem!)
(…)
(…)
(…)
So, here’s the solution. We start by considering the opposite of A always being ahead, which is that A is either behind or that the vote is tied at some point. Since we know that A eventually wins, A being behind at some point implies that at a later point A and B are tied. So the opposite of A always being ahead is really just that there is a tie at some point.
Pr(A is always ahead | n votes for A, m votes for B) = 1 – Pr(A is behind at some point or tied at some point | n, m) = 1 – Pr(There’s a tie at some point | n, m)
Now, let’s consider the probability of a tie at some point. There are two ways for this to happen: either the first vote is for A or the first vote is for B. The first vote being for B entails that there must be a tie at some point, since A must eventually pull ahead to win. This allows us to say the following:
Pr(Tie at some point | n, m) = Pr(Tie at some point & A is first vote | n, m) + Pr(Tie at some point & B is first vote | n, m) = Pr(Tie at some point & A is first vote | n, m) + Pr(B is first vote | n, m) = Pr(Tie at some point & A is first vote | n, m) + m/(n+m)
Now, the final task is to figure out Pr(Tie at some point & A is first vote | n, m). If you haven’t yet figured it out, I encourage you to pause for a minute and think it over.
(…)
(…)
Alright, so here’s the trick. If there’s a tie at some point, then up to and including that point there are an equal number of votes for A and B. But this means that there are the same number of possible worlds in which A votes first as there are possible worlds in which B votes first! And this means that we can say the following:
Pr(Tie at some point & A is first vote | n, m) = Pr(Tie at some point & B is first vote | n, m)
And this is exactly the probability we’ve already solved!
Pr(Tie at some point & B is first vote | n, m) = Pr(B is first vote | n, m) = m/(n+m)
And now we’re basically done!
Pr(Tie at some point | n, m) = m/(n+m) + m/(n+m) = 2m/(n+m)
Pr(A is always ahead | n, m) = 1 – Pr(Tie at some point | n, m) = 1 – 2m/(n+m) = (n – m) / (n + m)
And there we have it: The probability that A is always ahead is just the difference in votes over the total number of votes! Beautiful, right?
We can even more elegantly express this as simply the percent of people that voted for A minus the percent that voted for B.
(n – m) / (n + m) = n/(n+m) – m/(n+m) =%A – %B
This tells us that even in the case where candidate A gets 75% of the vote, there’s still a 50/50 chance that they fall behind at some point!
An example of this: the recent election had Biden with 81,283,485 votes and Trump with 74,223,744 votes. Imagining that there were no third candidates, this would mean that Biden had 52.27% of the popular vote and Trump had 47.73%. And if we now pretend that the votes were equally likely to be counted in any order, then this tells us that there would only be a 9.54% chance that Biden would be ahead the entire time! Taking into account the composition of mail-in ballots, which were counted later, this means that Trump having an early lead was in fact exactly what we should have expected. The chance that Biden would have fallen behind at some point was likely quite a bit higher than 90.5%!
Recently I’ve been thinking about both quantum mechanics and chess, and came up with a chess variant that blends the two. The difference between ordinary chess and quantum chess is the ability to put your pieces in superpositions. Here’s how it works!
Movement
There are five modes of movement you can choose between in quantum chess: Move, Split, Merge, Collapse, and Branchmove.
Modes 1 and 2 are for non-superposed pieces, and modes 3, 4, and 5 are for superposed pieces.
Mode 1: Move
This mode allows you to move just as you would in an ordinary chess game.
Mode 2: Split
In the split mode, you can choose a non-superposed piece and split it between two positions. You can’t choose a position that is occupied, even by a superposed piece, meaning that splitting moves can never be attacks.
One powerful strategy is to castle into a superposition, bringing out both rooks and forcing your opponent to gamble on which side of the board to stage an attack on.
Mode 3: Merge
In mode 3, you can merge the two branches of one of your superposed pieces, recombining them onto a square that’s accessible from both branches.
You can’t merge to a position that’s only accessible from one of the two branches, and you can’t merge onto a square that’s occupied by one of your own superposed pieces, but merge moves can be attacks.
Mode 4: Collapse
Mode 4 is the riskiest mode. In this mode, you choose one of your superposed pieces and collapse it. There are two possible outcomes: First, it might collapse to the position you clicked on. In this case, you now have a choice to either perform an ordinary move…
… or to split it into a new superposition.
But if you get unlucky, then it will collapse to the position you didn’t select. In this case, your turn is over and it goes to your opponent.
Mode 5: Branch Move
Finally, in a branch move, you relocate just one branch of the superposition, without collapsing the wave-function or affecting the other branch.
Piece Interactions
Attacking a Superposed Piece
What happens if you attack a superposed piece? The result is that the superposed piece collapses. If the piece collapses onto the square you attacked, then you capture it.
But if it collapses onto the other branch of the superposition, then it is safe, and your piece moves harmlessly into the square you just attacked.
This means that attacking a superposed piece is risky! It’s possible for your attack to backfire, resulting in the attacker being captured next turn by the same piece it attacked.
It’s also possible for a pawn to move diagonally without taking a piece, in a failed attack.
Line of Sight
Superposed pieces block the lines of sight of both your pieces and your opponent’s pieces. This allows you to defend your pieces or block open files, without fully committing to defensive positions.
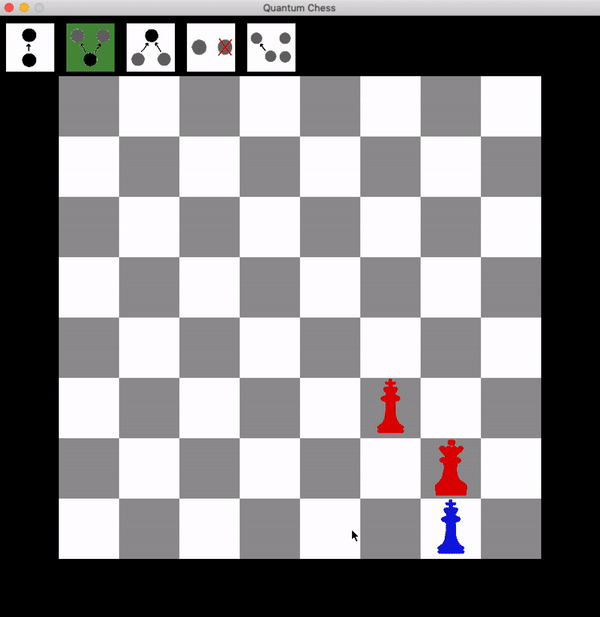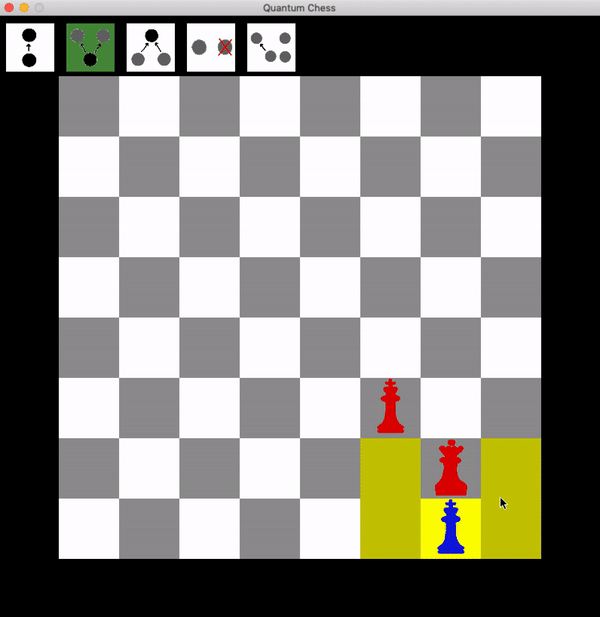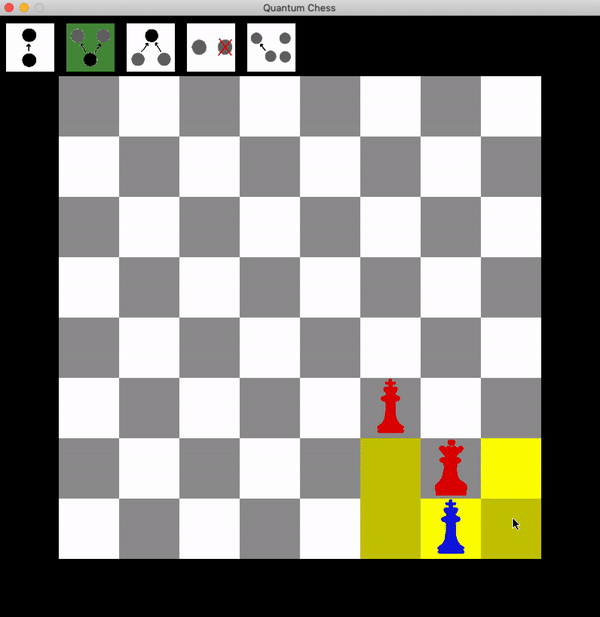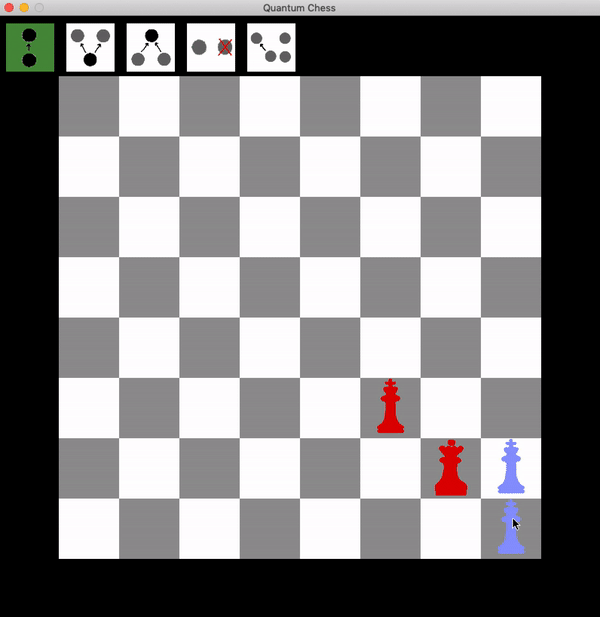
Winning the Game
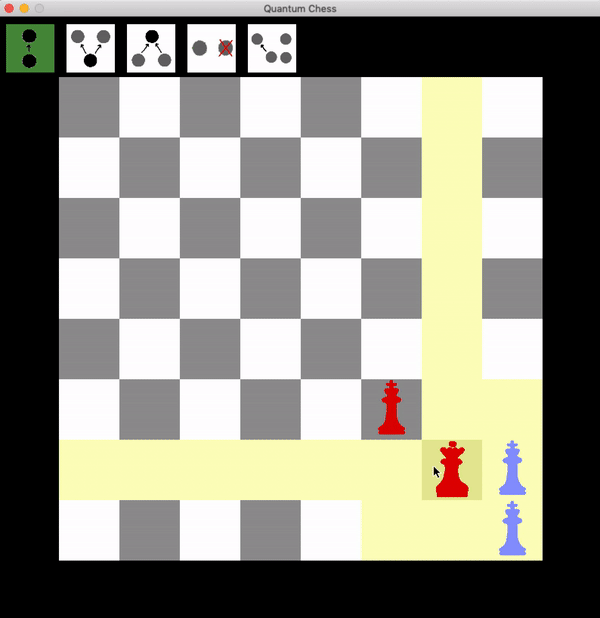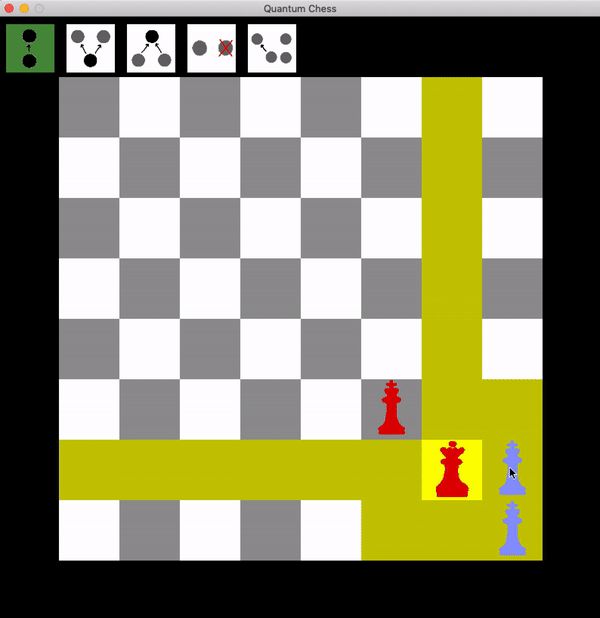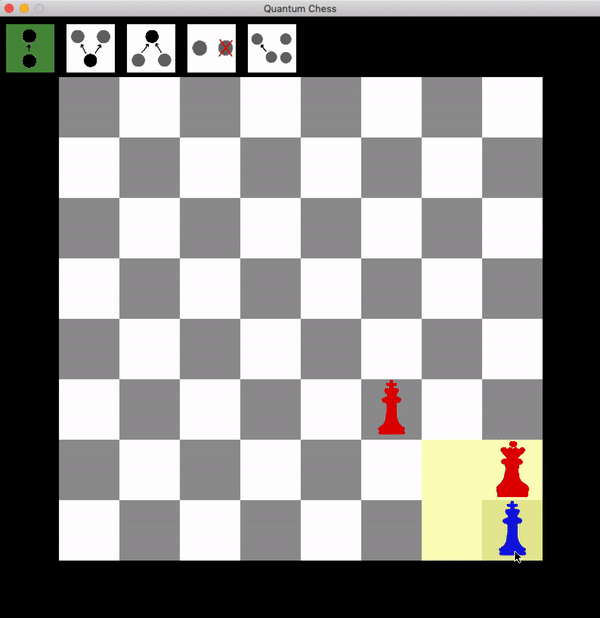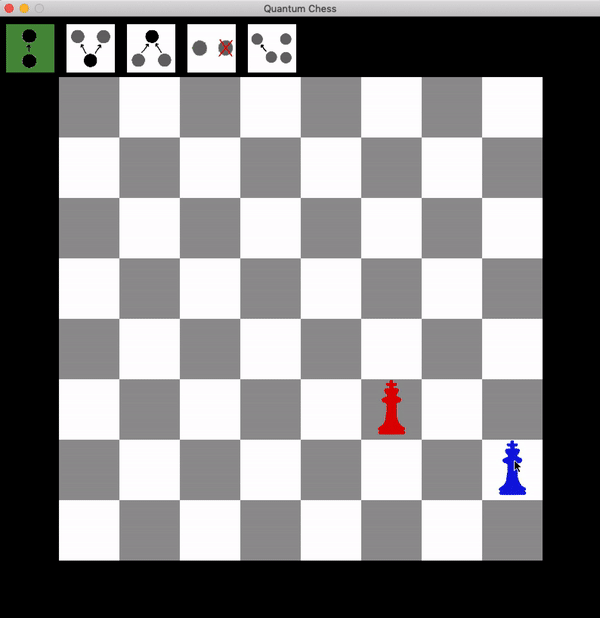
To win quantum chess, you must actually take the opponent’s king. Let’s see why it’s not enough to just get the opponent into a position that would ordinarily be checkmate:
It’s blue’s turn now, and things look pretty lost. But look what blue can do:
Now the red queen has to choose one of the two targets to attack, and there’s a 50% chance that she gets it wrong, in which case the blue king can freely take the red queen, turning a sure loss into a draw!
So how can red get a guaranteed win? It takes patience. Rather than trying to attack one of the two squares, the red queen can hang back and wait for a turn.
Now the blue king has two choices: leave superposition, after which they can be taken wherever they go. Or move one branch of the superposition, but any possible branch move results in a safe shot at the king with the queen. This can be repeated until the king is taken.
And that’s quantum chess! I’ve played several games with friends, and each time have noticed interesting and surprising strategies arising. Let me leave you with a quantum chess puzzle. Here’s a position I found myself in, playing red:
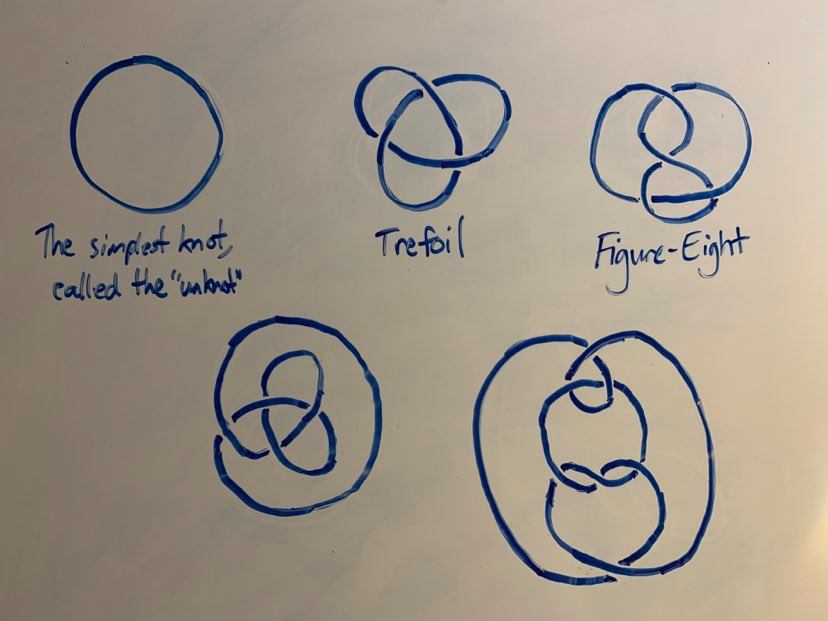
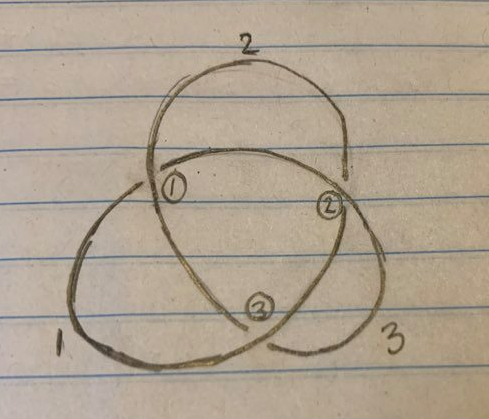
A knot is a closed loop in three dimensional space that doesn’t intersect itself. Some examples:
Knot diagrams are what you just saw: two dimensional representations of the three dimensional objects. It should be obvious that any one knot has many different diagrams. This raises an immediate question: given two knot diagrams, do they represent the same knot?
We need to be clear on what we mean by “the same knot”, of course. The intuition here is fairly obvious: you can rotate, stretch, and wiggle any section of a knot without fundamentally changing it.
What you CANNOT do is cut and reconnect the knot or pass one section of a knot through another of its sections.
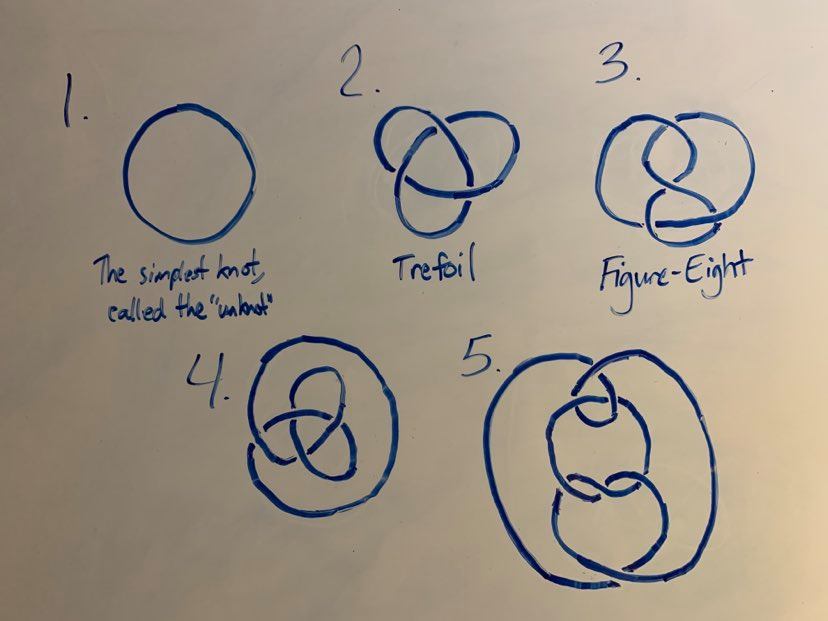
Looking back at our starting five example knots, ask yourself if any of them represent the same knot:
It might not be too obvious, but 2 and 4 represent the same knot, and so do 1 and 5! These equivalences (especially the equivalence between 1 and 5) should hopefully give a flavor for the difficulty of the general problem of determining equivalence between knots. While it’s sometimes possible to answer this by mere examination, it’s more often impossible. Even in cases where it seems very intuitively obvious (like, for instance, that the trefoil is not just an unknot in disguise), it’s hard to come up with a way to PROVE this fact.
When faced by a hard problem, we should begin thinking of the structure of a general solution. What we’d really like is a recipe for an algorithm that takes in two knot diagrams and decides whether they represent the same knots. (For economy of space and ease of reading, I’ll proceed to refer to “knot diagrams that represent equivalent knots” as “equivalent knot diagrams”.)
Here’s a naive first pass at a solution: Take either of the two knot diagrams you’re given. Start wiggling it around in all the allowed ways. At each step, check if you’ve obtained the other knot diagram. If you ever do, return True. Otherwise return False.
Maybe you see the problem here. In fact there are at least two major problems. (I said it was a naive first pass.)
The first big problem is in the “otherwise return False”. At what point in the algorithm do you actually reach this “otherwise” clause? Assuming that the two knot diagrams really do represent different knots, then you can keep manipulating the starting knot diagram in more and more complicated ways forever. At each stage you might get original knot diagrams, and at no stage are you justified in giving up and returning False. In other words, even if this algorithm worked as I described it, it could only ever decide equivalence of two equivalent knot diagrams. If handed two inequivalent knot diagrams, it would run forever. Thus this is really an algorithm for semi-deciding knot-diagram equivalence, not deciding it.
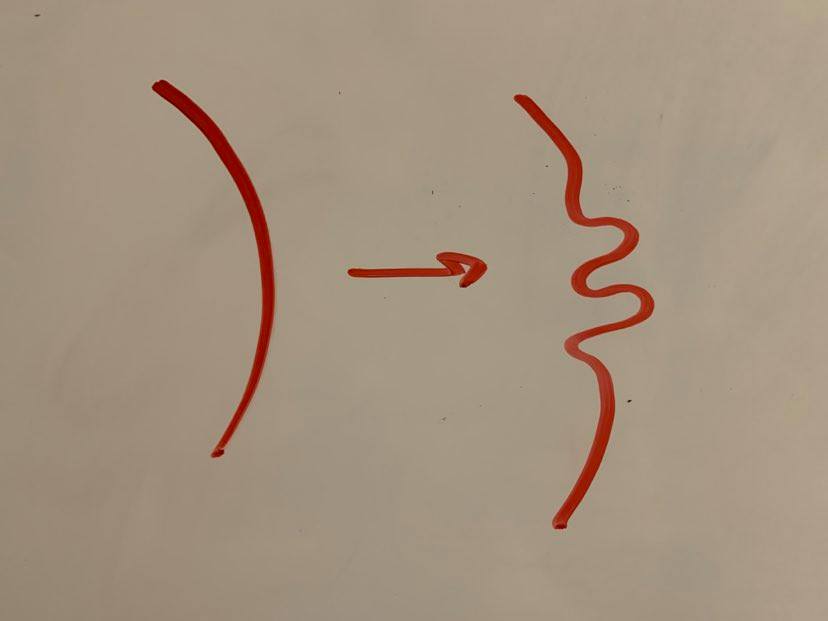
The second big problem is in the “start wiggling it around in all the allowed ways.” How would we describe the set of allowed transformations of a knot diagram to a computer? In particular, could we simplify down the allowed transformations to a finite set that would ensure that we really had done ALL possible manipulations? The answer to this is obviously no. Consider the following transformation:
Each transformation like this produces a new knot diagram, simply by wiggling one side in an arbitrary way. But how many possible wiggles are there? Clearly an uncountable infinity: you can do arbitrarily small disruptions centered on any point along the knot, leaving the rest undisturbed, and get a distinct knot diagram each time.
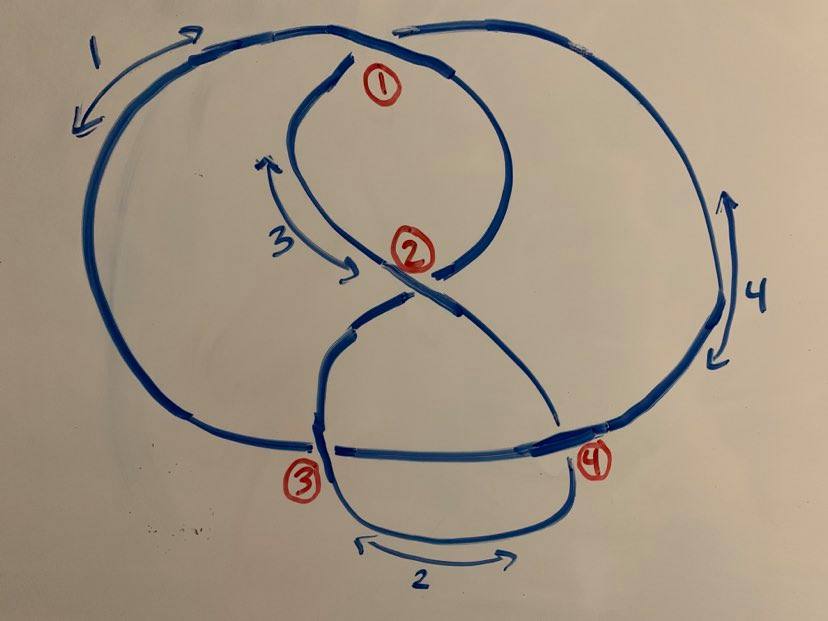
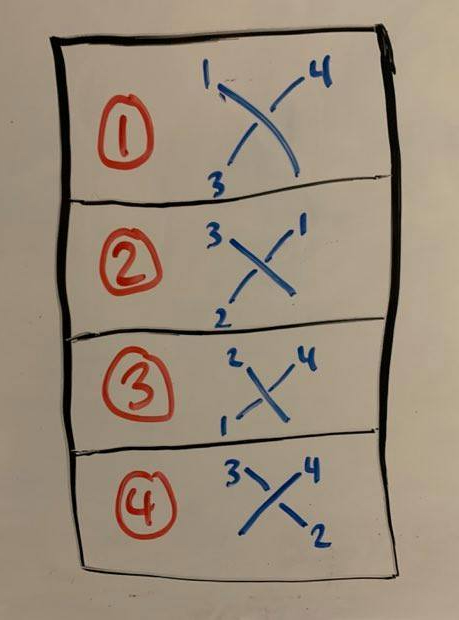
The “uncountable infinity” aspect of this second problem can actually be quickly resolved by sharpening our original question. Rather than regarding a knot diagram as any two-dimensional projection of a knot, we can think about a knot diagram as defined by its various crossings. For instance, we can label each uninterrupted “arc” in a knot diagram, as well as each crossing point.
We now produce an alternative description of knot diagrams, obtained by describing how each arc interacts with each crossing point.
Crucially, our new description is not affected by the uncountably many small wiggles that do not make any substantial changes to the knot diagram. I.e., they do not affect the way that the various arcs cross under or above each other. We call this “equivalence of knot diagrams up to planar isotopy”, where planar isotopy is meant to refer to changes in a knot that don’t affect the structure of the crossings.
That’s one helpful step towards fixing up our algorithm. However, we are still in need of a finite set of transformations that we are sure generates ALL possible transformations on knot diagrams. I encourage you to think about this problem for a moment, and come up with a set of transformations to knot diagrams that you think are sufficient to produce knot diagrams.
(…)
(…)
I’ll leave a little space for you to try to come up with an answer for yourself. It’s not an easy exercise, but might be fun to test your knot-theoretic intuitions on.
(…)
(…)
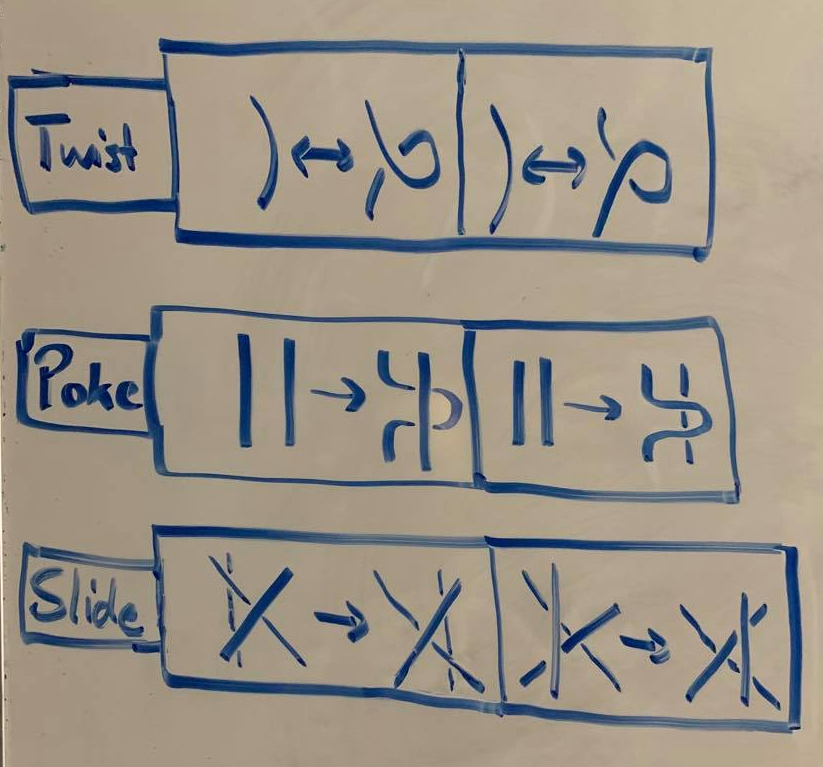
Reidemeister Moves
It turns out that a set of six very simple transformations suffices for this task, discovered by Kurt Reidemeister. There are three categories of transformations:
If two knot diagrams are equivalent, then there is a sequence of Reidemeister moves that transforms one to the other (up to planar isotopy).
It’s pretty fun to try to construct such sequences for oneself, and in doing so you’ll develop an intuition for why repeated Reidemeister moves suffice to generate all transformations. Try the earlier example of the two diagrams for the trefoil! I can do it in ten moves, can you do better?
So, this is great news! Our naive first attempt at building an algorithm to determine equivalence can be implemented (though it still only semi-decides equivalence rather than deciding it). Choose one of the diagrams, and run through all finite sequences of Reidemeister moves in any order. At each stage we check if we get the other diagram by application of these moves, and if so return True.
So with the help of the Reidemeister moves, we’ve successfully semidecided the equivalence problem. But it turns out that we can do better. Reidemeister moves not only allow us to determine that two diagrams are equivalent, but they lead us to a powerful tool to determine that two diagrams are inequivalent. The key concept here is invariants.
Invariants
Imagine that we found some quantity Q, calculated from a knot diagram, such that no matter how we alter the knot diagram, that quantity never changes. Now if we’re given two knot diagrams D1 and D2, and find that Q(D1) ≠ Q(D2), then we have conclusively demonstrated the inequivalence of the two diagrams! Why? Because if there was some way to transform D1 into D2, and since every transformation holds fixed Q(D1), then Q(D2) would have to equal Q(D1)!
The hard part, of course, is finding invariants. But this is much easier when we have the help of Reidemeister moves! To show that Q(D) is an invariant quantity, all we need to do is show that the value of Q doesn’t change when we apply any Reidemeister move to the diagram D. This basically amounts to checking six simple cases, which is not too bad.
So, let’s go to our first invariant quantity: three-colorability.
3-Colorability
Three-colorability is quite simple: a knot is three-colorable if it’s possible to color each knot such that at each crossing either all three arcs are the same color, or all three are different.
Notice that any knot can be trivially 3-colored by just letting every arc be the same color; to avoid this we add the requirement that for a 3-coloring to be valid, it must use at least two distinct colors.
It’s a fun exercise to show that this quantity is invariant using Reidemeister moves. The simplest case is the twist. Essentially all we need to do is show that if we apply a twist to a 3-colorable diagram, we can still 3-color the new diagram, AND that there’s a way to “untwist” a 3-colorable diagram so that we still retain 3-colorability. The proof is actually quite trivial; note that the crossing at any twist must be monochrome, since two of the involved arcs are actually the same.
Try convincing yourself that 3-colorabiity is preserved under the other Reidemeister moves!
So, 3-colorability is an invariant. There’s a very nice consequence of this. The trefoil is three-colorable, and the unknot (having only one arc) is not.
So this proves that the trefoil can not be unknotted! This was probably intuitively obvious from the outset, but we can now rest comfortably in the certainty of a mathematical proof.
p-Colorability
A fun exercise: try to 3-color the figure-eight knot, and see why it’s not possible.
This shows that the figure-eight knot is not equivalent to the trefoil. But what about the unknot? Neither the unknot and the figure-eight knot are 3-colorable, and yet they are not equivalent! So 3-colorability, while quite cool, isn’t the whole story. However, there’s a nice generalization of 3-colorability to p-colorability for any prime p.
Think about colors as numbers. So our set of three colors from the last section will just be {0, 1, 2}. A coloring is then a function mapping arcs to {0, 1, 2}. This gives us an algebraic way of expressing the 3-colorability property:
If x, y, and z are the colors of the three arcs connecting at a crossing, with z being the arc that passes above the crossing, then 2z – x – y = 0 (mod 3). It’s easily checkable that this is equivalent to the condition that each crossing is either monochrome, or else the three arcs are different colors.
We generalize this to any prime p as follows:
Our set of colors will be {0, 1, …, p – 1}. If for each crossing, 2z – x – y = 0 mod p, and at least two colors are used, then the knot is p-colorable.
For each prime p, p-colorability is an invariant, meaning that we have now gone from one invariant quantity to a countable infinity of invariants! We also can now distinguish the figure-eight knot from the unknot: the first is 5-colorable, while the unknot is not.
Five-coloring the figure-eight – check for yourself that the algebraic condition (2z – x – y = 0 mod 5) is satisfied
An exercise: try 5-coloring the trefoil. Is it possible?
However, this is not the end of the story. For one thing, it’s not so easy to determine if an arbitrary knot is p-colorable. It’s doable, sure, by trying all the possible colorings, but we want a quicker method. This will be addressed in the next section.
Much more importantly, we’ll see in the next section that there are knot diagrams that have the same colorability profile (i.e. D1 is p-colorable iff D2 is p-colorable, for each p), and yet represent different knots. So we need an even more powerful invariant to discriminate these from one another.
Knot Determinant
Take any knot and label its arcs and crossings with natural numbers.
Then construct a matrix M, where the (i, j) component corresponds to arc i and crossing j. If arc i isn’t involved in crossing j, then Mij = 0. If arc i is involved in crossing j, and passes over it, then Mij = 2. And if arc i passes under crossing j, then Mij = -1.
Now, cross out any row and column of your choice, and take the determinant of the remaining matrix. Take its absolute value, and you have the knot determinant.
You know what I’m going to say next: the knot determinant is an invariant! Not only is it an invariant, but it also fully determines the colorability profile of a knot! The rule is that if a knot has knot determinant N, then for any prime p > 2, N is p-colorable if and only if p divides N.
For instance, say we calculate that a knot has determinant 33. We immediately conclude that the knot is 3-colorable, 11-colorable, and not p-colorable for any other prime.
This is pretty incredible. We now have a simple deterministic procedure for looking at a knot diagram and producing a number that gives us the entire colorability profile of the knot. But wait, there’s more!
Suppose we have two knot diagrams, one with determinant 15, and the other with determinant 45. These two indicate the same colorability profile: 3-colorable, 5-colorable, and nothing else. But since the determinants are different, the two knots are not equivalent! In other words, any two knots with different determinants that have all the same prime factors (but with possibly different powers of those prime factors) will have the exact same colorability profile, and will nonetheless be proven inequivalent by the knot determinant!
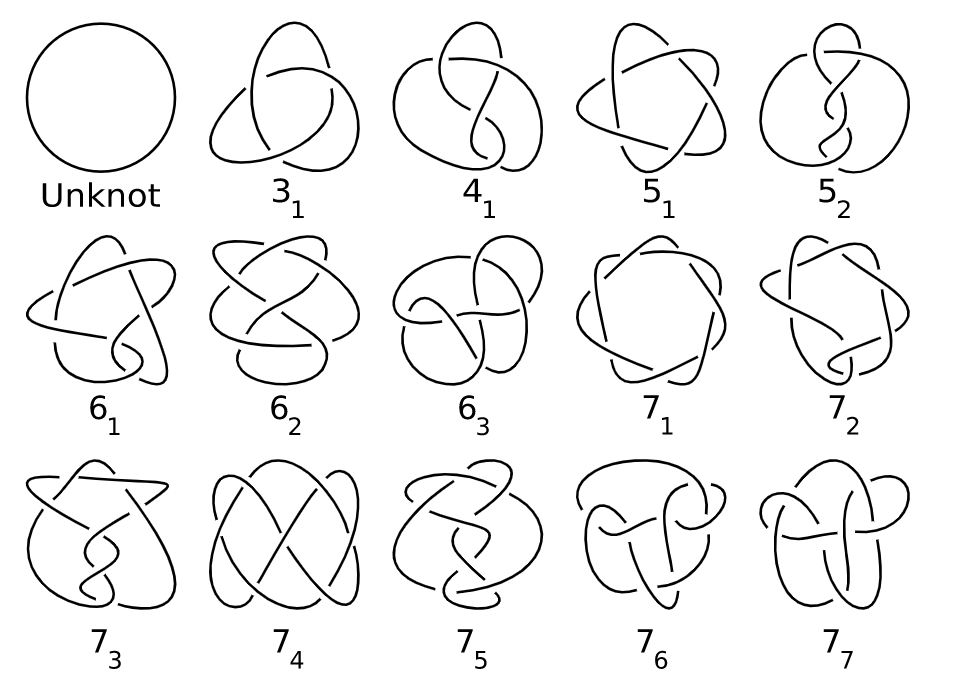
We’ve now reached the end of this dive into knot theory, but only because we’ve begun to near the end of my knowledge of the subject. By no means does the theory of knots end here. The knot determinant, amazing though it is, still does not fully pin down the different knots up to equivalence. There are distinct knots with the same determinant. If we were to dive further, we’d next look into a polynomial invariant, the Alexander polynomial. Going deeper, there’s hyperbolic invariants, involving the complement of a knot in hyperbolic space. Then there’s links, which are structures consisting of multiple knots linked together in some way, which have their own theory and periodic table. And we can even consider knotting spheres in four-dimensional space, or in general n-dimensional spheres in n+1-dimensional space! Plus there’s the operation of the knot sum, which we can use to combine distinct knots and get a new one. This operation is commutative and associative, and gives rise to the notion of prime and composite knots. And the coolness just keeps going on from here!
If nothing else, I hope I’ve convinced you that the subject of knots is of great mathematical interest and inspired you to look into it yourself. I’ll leave you with the first few rows of a (necessarily infinite) periodic table of knots, showing the prime knots up to seven crossings:
Polish notation is a mathematical notation system that allows you to eliminate parentheses without ambiguity. It’s called “Polish” because the name of its Polish creator, Jan Łukasiewicz, was too difficult for people to pronounce.
A motivating example: Suppose somebody says “p and q implies r”. There are two possible interpretations of this: “(p and q) implies r” and “p and (q implies r)”. The usual way to disambiguate these two is to simply add in parentheses like I just did. Another way is to set an order-of-operations convention, like that “and” always applies before “implies”. This is what’s used in basic algebra, and what allows you to write 2 + 2 ⋅ 4 without any fear that you’ll be interpreted as meaning (2 + 2) ⋅ 4.
Łukasiewicz’s method was to make all binary connectives into prefixes. So “A and B” because “and A B”, “P implies Q” becomes “implies P Q”, and so on. In this system, “(p and q) implies r” translates to “implies and p q r”, and “p and (q implies r)” translates to “and p implies q r”. Since the two expressions are different, there’s no need for parentheses! And in general, no ambiguity ever arises from lack of parentheses when using Polish notation.
If this is your first time encountering Polish notation, your first reaction might be to groan and develop a slight headache. But there’s something delightfully puzzling about reading an expression written in Polish notation and trying to understand what it means. Try figuring out what this means: “implies and not p or q s r”. Algebra can be written in Polish notation just as easily, removing the need for both parentheses AND order-of-operations. “2 + 2 = 4” becomes “+ 2 2 = 4”, or even better, “= + 2 2 4”.
Other binary connectives can be treated in Polish notation as well, creating gems like: “If and you’re happy you know it clap your hands!” “When life is what happens you’re busy making plans.” “And keep calm carry on.” “Therefore I think, I am.” (This last one is by of the author the Meditations). Hopefully you agree with me that these sentences have a nice ring to them, though the meaning is somewhat obscured.
But putting connectives in front of the two things being connected is not unheard of. Some examples in English: “ever since”, “because”, “nonwithstanding”, “whenever”, “when”, “until”, “unless”. Each of these connects two sentences, and yet can appear in front of both. When we hear a sentence like “Whenever he cheated on a test the professor caught him”, we don’t have any trouble parsing it. (And presumably you had no trouble parsing that entire last sentence either!) One could imagine growing up in a society where “and” and “or” are treated the same way as “ever since” and “until”, and perhaps in this society Polish notation would seem much more natural!
Slightly related to sentential connectives are verbs, which connect subjects and objects. English places its verbs squarely between the subject and the object, as does Chinese, French, and Spanish. But in fact the most common ordering is subject-object-verb! 45% of languages, including Hindi, Japanese, Korean, Latin, and Ancient Greek, use this pattern. So for instance, instead of “She burned her hand”, one would say “she her hand burned”. This is potentially weirder to English-speakers than Polish notation; it’s reverse Polish notation!
9% of languages use Polish notation for verbs (the verb-subject-object pattern). These include Biblical Hebrew, Arabic, Irish, and Filipino. In such languages, it would be grammatical to say “Loves she him” but not “She loves him”. (3% of languages are VOS – loves him she – 1% are OVS – him loves she – and just a handful are OSV – him she loves).
Let’s return to English. Binary prepositions like “until” appear out front, but they also swap the order of the two things that they connect. For instance, “Until you do your homework, you cannot go outside” is the same as “You cannot go outside until you do your homework”, not “You do your homework until you cannot go outside”, which sounds a bit more sinister.
I came up with some examples of sentences with several layers of these binary prepositions to see if the same type of confusion as we get when examining Polish notation for “and” or “implies” sets in here, and oh boy does it.
Single connective Since when the Americans dropped the bomb the war ended, some claimed it was justified.
Two connectives, unlayered Since when the Americans dropped the bomb the war ended, when some claimed it was an atrocity others argued it was justified.
Still pretty readable, no? Now let’s layer the connectives.
One layer Whenever he was late she would weep. She would weep whenever he was late.
Two layers Since whenever he was late she would weep, he hurried over. He hurried over, since she would weep whenever he was late.
Three layers Because since whenever he was late she would weep he hurried over, he left his wallet at home. He left his wallet at home, because he hurried over since she would weep whenever he was late.
Four layers Because because since whenever he was late she would weep he hurried over he left his wallet at home, when he was pulled over the officer didn’t give him a ticket. The officer didn’t give him a ticket when he was pulled over, because he left his wallet at home because he hurried over since she would weep whenever he was late.
Five layers When he heard because because since whenever he was late she would weep he hurried over he left his wallet at home, when he was pulled over the officer didn’t give the man a ticket, the mayor was outraged at the lawlessness. The mayor was outraged at the lawlessness when he heard the officer didn’t give the man a ticket when he was pulled over because he left his wallet at home because he hurried over since she would weep whenever he was late.
Read that last one out loud to a friend and see if they believes you that it makes grammatical sense! With each new layer, things become more and more… Polish. That is, indecipherable. (Incidentally, Polish is SVO just like English). Part of the problem is that when we have multiple layers like this, phrases that are semantically connected can become more and more distant in the sentence. It reminds me of my favorite garden-path sentence pattern:
The mouse the cat the dog chased ate was digested. (The mouse that (the cat that the dog chased) ate) was digested. The mouse (that the cat (that the dog chased) ate) was digested.
The phrases that are meant to be connected, like “the mouse” and “was digested” are sandwiched on either side of the sentence, and can be made arbitrarily distant by the addition of more “that the X verbed” clauses.
Does anybody know of any languages where “and” comes before the two conjuncts? What about “or”? English does this with “if”, so it might not be too much of a stretch.
A concept: a book that starts by assuming the understanding of the reader and using concepts freely, and as you go on it introduces a simple formal procedure for defining words. As you proceed, more and more words are defined in terms of the basic formal procedure, so that halfway through, half of the words being used are formally defined, and by the end the entire thing is formally defined. Once you’re read through the whole book, you can start it over and read from the beginning with no problem.
I just finished a set theory textbook that felt kind of like that. It started with the extremely sparse language of ZFC: first-order logic with a single non-logical symbol, ∈. So the alphabet of the formal language consisted of the following symbols: ∈ ( ) ∧ ∨ ¬ → ↔ ∀ ∃ x ‘. It could have even started with a sparser formal language if it was optimizing for alphabet economy: ∈ ( ∧ ¬ ∀ x ‘ would suffice. As time passed and you got through more of the book, more and more things were defined in terms of the alphabet of ZFC: subsets, ordered pairs, functions from one set to another, transitivity, partial orders, finiteness, natural numbers, order types, induction, recursion, countability, real numbers, and limits. By the last chapter it was breathtaking to read a sentence filled with complex concepts and realize that every single one of these concepts was ultimately grounded in this super simple formal language we started with, with a finitistic sound and complete system of rules for how to use each one.
But could it be possible to really fully define ALL the terms used by the end of the book? And even if it were, could the book be written in such a way as to allow an alien that begins understanding nothing of your language to read it and, by the end, understand everything in the book? Even worse, what if the alien not only understands nothing of your language, but starts understanding nothing of the concepts involved? This might be a nonsensical notion; an alien that can read a book and do any level of sophisticated reasoning but doesn’t understand concepts like “and” and “or“.
One way that language is learned is by “pointing”: somebody asks me what a tree is, so I point to some examples of trees and some examples of non-trees, clarifying which is and which is not. It would be helpful if in this book we could point to simple concepts by means of interactive programs. So, for instance, an e-book where an alien reading the book encounters some exceedingly simple programs that they can experiment with, putting in inputs and seeing what results. So for instance, we might have a program that takes as input either 00, 01, 10, or 11, and outputs the ∧ operation applied to the two input digits. Nothing else would be allowed as inputs, so after playing with the program for a little bit you learn everything that it can do.
One feature of such a book would be that it would probably use nothing above first-order logical concepts. The reason is that the semantics of second-order logic cannot be captured by any sound and complete proof system, meaning that there’s no finitistic set of rules one could explain to an alien so that they know how to use the concepts involved correctly. Worse, the set of second-order tautologies is not even recursively enumerable (worse than the set of first-order tautologies, which is merely undecidable), so no amount of pointing-to-programs would suffice. First-order ZFC can define a lot, but can it define enough to write a book on what it can define?
In the game of Nim, you start with piles of various (whole number) heights. Each step, a player chooses one pile and shrinks it by some non-zero amount. Once a pile’s height has been shrunk to zero, it can no longer be selected by a player for shrinking. The winner of the game is the one that takes the last pile to zero.
Here’s a sample game of Nim:
Starting state 3, 2 After Frank’s move 2, 2 After Marie’s move 2, 1 After Frank’s move 0, 1 After Marie’s move 0, 0
Marie takes the last pile to zero, so she is the winner. Frank’s second-to last move was a big mistake; by reducing the first pile from 2 to 0, he left the only remaining pile free to be taken by Marie. In a game of Nim, you should never leave only one pile remaining at the end of your turn. If Frank had instead shrunk the first pile from 2 to 1, then the state of the piles would be (1, 1). Marie would be forced to shrink one of the two piles to zero, leaving Frank to take the final pile and win.
The strategy of Nim with two piles is extremely simple: in your turn you should always even out the two piles if possible. This is only possible if the heights are different at the start of your turn. See if you can figure out why this strategy guarantees a win!
Transfinite Nim is a version of Nim where the piles are allowed to take infinite ordinal values. So for instance, a game might have the following starting position:
Starting state ω2 + ω, ω1 + ε0
If Marie is moving first, then can she guarantee a win? What move should she make?
It turns out that the strategy for two-pile Transfinite Nim is exactly the same as for two-pile Finite Nim. Marie has a guaranteed win, because the two piles are different values. Each move she’ll just even the piles out. So for her first move, she should do the following:
Starting state ω2 + ω, ω1 + ε0 After Marie’s move ω2 + ω, ω2 + ω
No matter what Frank does next, Marie can just “copy” that move on the other pile, guaranteeing that Marie always has a move as long as Frank does. This proves that Marie must have the last move, and therefore win.
One important feature of Transfinite Nim is that even though we’re dealing with infinitely large piles, every game can only last finitely long. In other words, Frank has no strategy for delaying his loss infinitely long, and thus forcing a sort of “stalemate by exhaustion.” This is because the ordinals are well-ordered, and any decreasing sequence of well-ordered items must terminate. (Why? Just consider the definition of a well-ordered set: every subset has a least element. If the game were to continue infinitely long, each step decreasing the state but never terminating, then the sequence of states would be a subset of the ordinals which has no least element!)
Although the strategy of Transfinite Nim is in one sense no more interesting than Finite Nim, the game does have some interesting features that it inherits from the ordinals. For instance, there are sets of ordinal numbers such that the ordering between them is uncomputable. For such sets, the ability to compute the winning strategy is called into question.
For instance, the set of all countable ordinals is uncomputable. The quick proof is that there are uncountably many countable ordinals – otherwise in ZFC the set of countable ordinals would itself be a countable ordinal and would thus contain itself – and any Turing machine can only compare countably many things. However, there are also uncomputable ordinals that are countable! If α is a countable ordinal, then we can find some bijection (not necessarily order-preserving) between α and ω, meaning that we can meaningfully ask if a Turing machine can compare any two of α’s elements (each represented by some natural number). And for an uncomputable countable ordinal, we know that no Turing machine can successfully compute its order type.
The smallest uncomputable ordinal (which, in ZFC, is exactly the set of all computable ordinals) is called the Church Kleene ordinal and written ω1CK. Imagine the starting state of the game is two different ordinals that are both larger than ω1CK. If you’re moving first, then you have to determine which of the two ordinals is larger, in order to even them out. But this is not in general possible! So even if you go first and the two piles are different sizes, you might not be able to guarantee a win.
Suppose Marie is allowed uncomputable strategies, and Frank is only allowed computable strategies. Suppose further that the starting state involves two countable ordinals A and B, both larger than the Church-Kleene, and that the ordinals are expressed in some standard notation (so that you can’t write the same ordinal two different ways). There are a few cases.
Case 1: A = B, Marie goes first. Marie decreases one of the two ordinals. Despite not being able to compute the order on the ordinals, Frank can just mimic her move. This will continue until Frank wins.
Case 2: A = B, Frank goes first. Frank decreases one of the two ordinals, and Marie mimics. Marie eventually wins.
Case 3: A ≠ B, Marie goes first. Marie can tell which of the ordinals is larger, and decreases that one to even out the two piles. Marie wins.
Case 4: A ≠ B, Frank goes first. Frank can’t tell which of the ordinals is larger and can’t try to even them out, as doing so might result in an invalid move (trying to increase the smaller pile to the height of the larger one). So Frank does some random move, after which Marie is able to even out the two piles. Marie wins.
There’s a subtlety in Case 4, which is that Frank could gamble by guessing that B is the bigger ordinal and then decreasing it to A. If he has no other information, then half the time he’ll end up successfully evening them out, in which case he continues to win the game. But the other half of the time he’ll have made an invalid move. If we assume that players cannot run strategies that have some chance of choosing invalid moves (for instance, if each player has to be able to prove that their move is valid in advance), then Frank’s gamble would not be allowed and he would go on to lose.
Finally, here’s a starting state for a game of Transfinite Nim:
ω1, ℶ1
ω1 is the first uncountable ordinal, and ℶ1 is the first ordinal with continuum cardinality. Frank goes first. Does he have a winning strategy?
The answer to this question depends on whether ω1 = ℶ1, or in other words the Continuum Hypothesis! If the two are equal, then Frank can’t win, because he’s starting with two even piles. And if ω1 < ℶ1, then Marie can’t win, because Frank can decrease the ℶ1 pile to ω1.
If we suppose that the players must be able to prove a move’s validity in ZFC before playing that move, then the first player couldn’t decrease the ℶ1 pile to ω1. The first player still has to do something, and whatever he does will change the state to two ordinals that are comparable by ZFC. What about larger starting ordinals whose size comparison is independent of ZFC, like ω15 and ℶ15? If the new state after the first player’s move move also involves two ordinals whose size comparison is independent of ZFC, then the second player will also be unable to even them out. This continues until one of them eventually decreases a pile to an ordinal whose size is comparable by ZFC to the other pile. So the winner will depend on who knows more pairs of ordinals less than the starting values with values that ZFC can’t compare. In fact, each player wants to force the other player to make the values ZFC-comparable, so they’ll be able to even the piles out on their turn.
What if our players are allowed to use different proof systems from each other? Then adjudication of whether a move is valid requires that we fix some meta-theoretic proof system as our judge. For instance, suppose our meta-theory is ZFC + V=L (in which case ω1 does equal ℶ1). In this case, if a player is using a theory from which they can prove that ω1 < ℶ1, they might end up making a move that we judge as invalid, even though in their view it’s perfectly valid. Presumably then each player has to reason within their own theory about what is valid according to the judge’s meta-theory. But perhaps these judgements will be fallible! If so, then the victor may end up depending on who has a better theory of the judge’s meta-theory!
In ZFC set theory, we specify a collection of sentences within a first-order language to count as our axioms. The models of this collection of sentences are the set-theoretic universes (and many of these models are “unintended” – pesky perversions in which the set of naturals ω is uncountably large, as one example – but we’ll put this aside for this post). Most of the axioms act as constraints that all sets must follow. For instance, the axiom of pairing says that “For any sets x and y, there must exist another set containing as elements just x and y and nothing else”. This is an axiom that begins with universal quantification over the sets of the universe, and then states some requirement that must hold of all these sets.
The anti-set program is what you get when you take each of these restriction axioms, and negate the restriction it imposes on all sets. So, for instance, the axiom of anti-pairing says that for any sets x and y, there must NOT exist any set {x, y}. Contrast this with the simple negation of pairing, which would tell us only that there exist two sets x and y such that their pair doesn’t exist. The anti-axiom is much stronger than the negated axiom, in that it requires NO pairs to exist.
Not all axioms begin with universal quantifiers, in particular the axiom of infinity, which simply asserts that a set exists that satisfies a certain property. To form the axiom of anti-infinity, we simply negate the original axiom (so that no sets with that property exist).
As it turns out, the anti-set program, if applied to ALL the axioms of ZFC, ends in disaster and paradox. In particular, a contradiction can be derived from anti-comprehension, from anti-replacement, and from anti-extensionality. We don’t handle these cases the same way. Anti-comprehension and anti-replacement are simply discarded, being too difficult to patch. By contrast, anti-extensionality is replaced by ordinary extensionality. What’s up with that? The philosophical justification is simply that extensionality, being the most a priori of the bunch, is needed to justify us calling the objects in our universe sets at all.
There’s one last consideration we must address, which regards the axiom of anti-choice. I am currently uncertain as to whether adding this axiom makes the theory inconsistent. One thing that is currently known about the axiom of anti-choice is that with its addition, out go all finite models (there’s a really pretty proof of this that I won’t include here). In the rest of this post, I will be excluding anti-choice from the axioms and only exploring models of anti-ZF.
With that background behind us, let me list the axioms of anti-ZF.
Anti-Pairing ∀x∀y∀z∃w (w ∈ z ∧ w ≠ x ∧ w ≠ y) No set is the pair of two others.
Anti-Union ∀x∀y∃z (z ∈ y ∧ ¬∃w (z ∈ w ∧ w ∈ x)) No set is the union of another.
Anti-Powerset ∀x∀y∃z (z ∈ y ∧ ∃w (w ∈ z ∧ w ∉ x)) No set contains all existing subsets of another.
Anti-Foundation ∀x∀y (y ∈ x → ∃z (z ∈ x ∧ z ∈ y)) Every set’s members have at least one element in common with it.
Anti-Infinity ∀x∃y ((y is empty ∧ y ∉ x) ∨ (y ∈ x ∧ ∃z (z = S(y) ∧ z ∉ x))) Every set either doesn’t contain all empty sets, or has an element whose successor is outside the set.
If the axioms of ZF are considered to be a maximally nice setting for mathematics, then perhaps the axioms of anti-ZF can be considered to be maximally bad for mathematics.
We need to now address some issues involving the axiom of anti-infinity. First, the abbreviations used: “y is empty” is shorthand for “∀z (z ∉ y)” and “z = S(y)” is shorthand for “∀w (w ∈ z ↔ (w ∈ y ∨ w = y))” (i.e. z = y ⋃ {y}).
Second, it turns out that from the other axioms we can prove that there are no empty sets. So the first part of the disjunction is always false, meaning that the second part must always be true. Thus we can simplify the axiom of anti-infinity to the following statement, which is logically equivalent in the context of the other axioms:
Anti-Infinity ∀x∃y (y ∈ x ∧ ∃z (z = S(y) ∧ z ∉ x)) Every set has an element whose successor is outside the set.
Let’s now prove some elementary consequences of these axioms.
Theorems
>> There are no empty sets. Anti-Union ⊢ ¬∃x∀y (y ∉ x) Suppose ∃x∀y (y ∉ x). Call this set ∅. So ∀y (y ∉ ∅) Then ⋃∅ = ∅. But this implies that the union of ∅ exists. This contradicts anti-union.
>> There are no one-element sets. Anti-Pairing ⊢ ¬∃x∃y∀z (z ∈ x ↔ z = y) Suppose that ∃x∃y∀z (z ∈ x ↔ z = y). Then ∃x∃y∀z (z ∈ x ↔ (z = y ∨ z = y)). But this is a violation of anti-pairing, as then x would be the pair of y and y. Contradiction.
>> There are no two-element sets. Anti-Pairing ⊢ ¬∃x∃y∃z∀w (w ∈ x ↔ (w = y ∨ w = z)) Suppose that ∃x∃y∃z∀w (w ∈ x ↔ (w = y ∨ w = z)). Then w is the pair of y and z, so anti-pairing is violated. Contradiction.
>> No models of anti-ZF have just N-element sets (for any finite N). Suppose that a model of anti-ZF had only N-element sets. Take any of these sets and call it X. By anti-infinity, X must contain an element with a successor that is outside the set. Call this element Y and its successor S(Y). Y cannot be its own successor, as then its successor would be inside the set. This means that Y ∉ Y. Also, Y is an N-element set by assumption. But since Y ≠ S(Y), S(Y) must contain all the elements of Y in addition to Y itself. So S(Y) contains N+1 elements. Contradiction.
>> There is no set of all sets. Suppose that there is such a set, and call it X. By Anti-Infinity, X must contain an element Y with a successor that’s outside of X. But no set is outside of X, by assumption! Contradiction.
>> No N-element model of anti-ZF can have N-1 sets that each contain N-1 elements. Suppose that this were true. Consider any of these sets that contain N-1 elements, and call it X. By the same argument made two above, this set must contain an element whose successor contains N elements. But there are only N sets in the model, so this is a set of all sets! But we already know that no such set can exist. Contradiction.
>> Every finite set of disjoint sets must be its own choice function. By a choice function for a set X, I mean a set that contains exactly one element in common with each element of X. Suppose that X is a finite set of disjoint sets. Let’s give the elements of X names: A1, A2, A3, …, AN. By anti-foundation, each An must contain at least one element of X. Since the Ans are disjoint, these elements cannot be the same. Also, since there are only N elements of X, no An can contain more than one element of X. So each element of X contains exactly one element of X. Thus X is a choice function for X!
The next results come from a program I wrote that finds models of anti-ZF of a given size.
>> There are no models of size one, two, three or four.
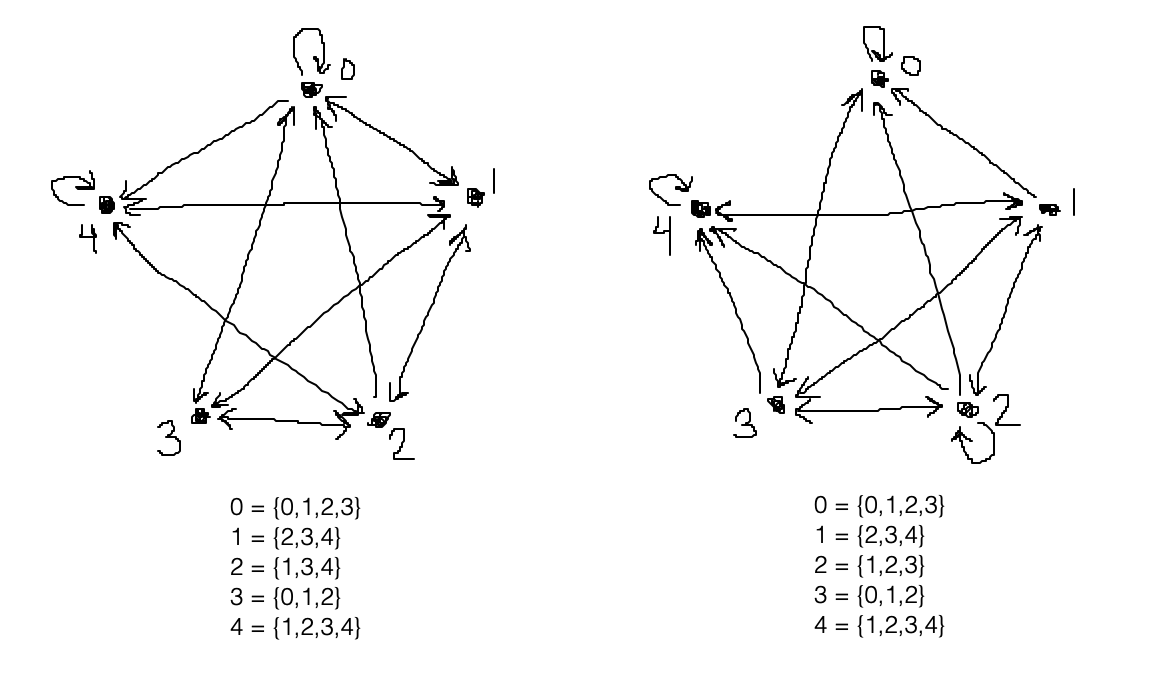
>> There are exactly two non-isomorphic models of size five.
Here are pictures of the two:
Now, some conjectures! I’m pretty sure of each of these, especially Conjecture 2, but haven’t been able to prove them.
Conjecture 1: There’s always a set that contains itself.
Conjecture 2: There can be no sets of disjoint sets.
Conjecture 3: In an N-element model, there are never less than three sets with fewer than N-1 elements.