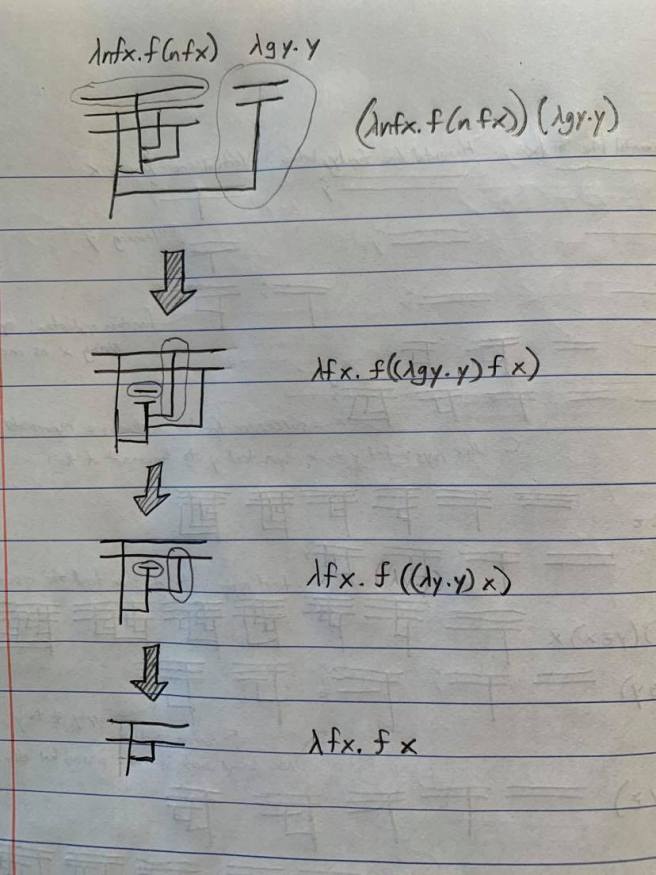
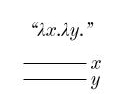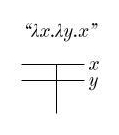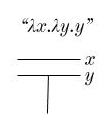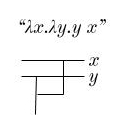Summary
Is there an infinity in between ℵ0 and 2ℵ0? Is there a way to color the plane with countably many colors so that there are no monochromatic triangles lined up with the x and y axes? If these questions seem unrelated to you, then we had the same initial reaction. But it turns out that an intermediate infinity exists if and only if no such coloring exists.
CH and Coloring
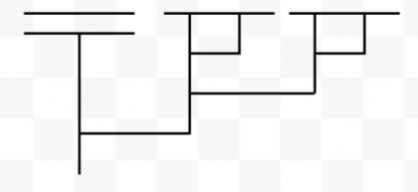
Imagine taking the plane ℝ2 and coloring it entirely. You are allowed infinitely many colors, but only a countable infinity (so no using the whole continuous spectrum). Some example colorings:



The colorings don’t have to be contiguous on the plane like in the ones you just saw. They can have individual points of one color such that neighborhoods of arbitrarily small radius around them are colored differently. So we can get wacky colorings like:

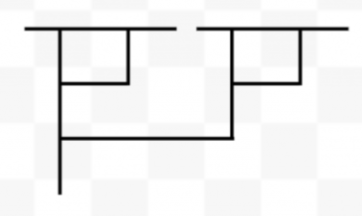
Think about right triangles on the plane that line up with the x and y axes. For instance:
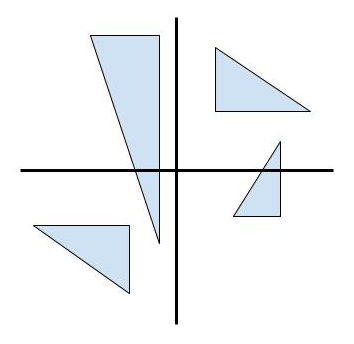
For each of these triangles, of the three sides one must be parallel to the x-axis and another to the y-axis. Now, for a given coloring, we can ask if there exist any triangles whose corners are all the same color. Importantly, we’re only interested in the three corner points, not the entire side length. For the earlier colorings we looked at, we can find such triangles fairly easily:


Even for our wacky coloring, it shouldn’t be too hard to find three points of the same color that meet the criterion.

Now here’s a question for you to ponder: is there any way to color the plane so that no such monochromatic right triangles exist?
I encourage you to pause here and try your best to come up with such a coloring. Use this as a chance to develop some intuitions on whether you think that a coloring like this should exist or not. It’s important to keep in mind that the amount of possible right triangles on the plane is 2ℵ0, while the number of colors you have available to you is just ℵ0.
(…)
(pause for thought)
(…)
Now, I shall prove to you that the existence of such a coloring is equivalent to the Continuum Hypothesis! The rest of this post will be more involved, and even though I’ve tried to make it less scary with pictures aplenty, it will most likely take a slow and attentive read-through to grasp. But the proof is really cool, so it’s worth it. Oh and also, I have assumed some things as background knowledge for the sake of space. In particular, understanding the proof requires that you understand what ordinals are and why the set of all countable ordinals is the first uncountable ordinal.
If the Continuum Hypothesis is true, then a coloring with no monochromatic right triangles exists.
The proof outline: Consider the first uncountable ordinal, ω1, which is the set of all countable ordinals. We construct a coloring on ω1 × ω1 that satisfies the no-monochromatic-right-triangles property. If the Continuum Hypothesis is true, then |ω1| = |ℝ|, so we form a bijection from ω1 to ℝ. Finally, we use this bijection to map our coloring on ω1 × ω1 to a coloring on ℝ × ℝ, and show that coloring also satisfies the same property.
Alright, so consider ω1 × ω1. If we were to visualize it, it would look something this:
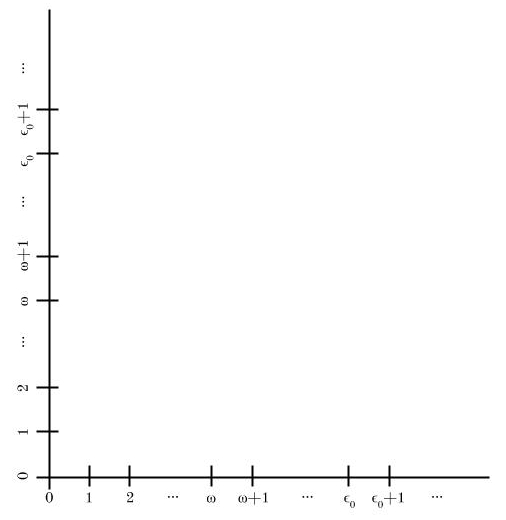
This “plane” is discrete, so in a certain sense it much more closely resembles ℕ2 than ℝ2. The set of colors we’ll be using will be labeled with integers. We split the colors into two categories, the negatives N and the positives P.
N = {-1, -2, -3, …}
P = {0, 1, 2, 3,…}
For each α in ω1, we construct two bijections f: α → N and g: α → P. These bijections exist because every element of ω1 is countable.
We use f and g to construct our coloring. For each α in ω1, we assign the color f(β) to (α, β) for each β < α, and we assign the color g(β) to (β, α), for each β ≤ α.
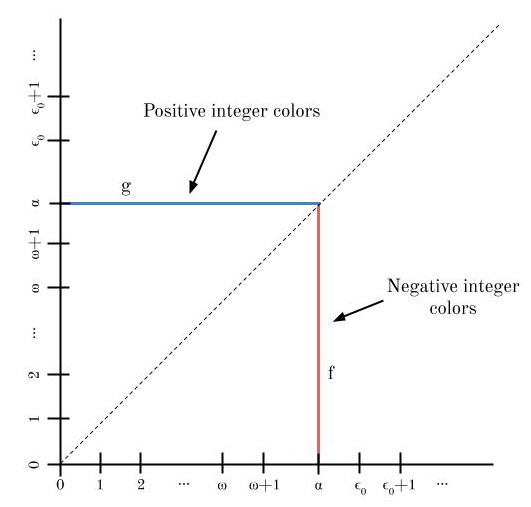
Since f and g are both bijections, no colors are repeated along the path from (α, 0) to (α, α) to (0, α). And we can easily show that no monochromatic right triangles exist under this coloring!
If a triangle crosses y = x, then it has at least one point colored from N and another from P. N and P are disjoint, so the triangle cannot be monochromatic.
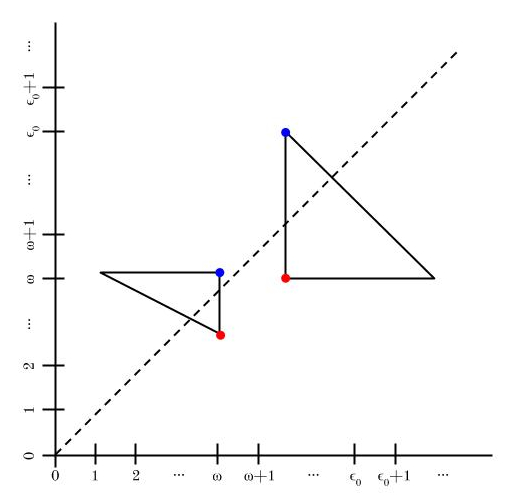
And if a triangle doesn’t cross y = x, then it has two points lined up so as to have different colors:
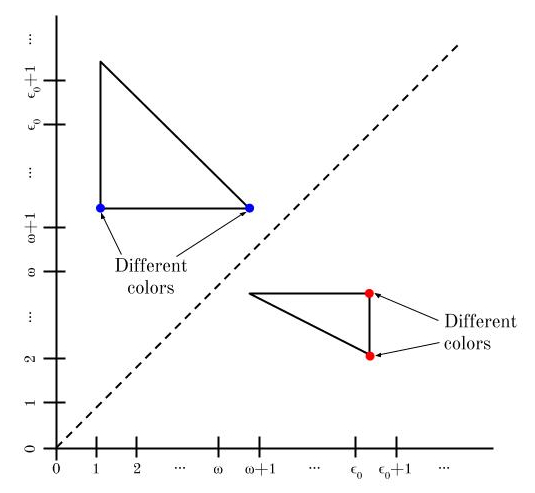
So we have no monochromatic triangles! Now, assuming the Continuum Hypothesis, |ω1| = |ℝ|, so we can form a bijection M from ω1 to ℝ. We use M to map our original coloring to a new coloring on ℝ × ℝ. If (a, b) ∈ ω1 × ω1 is colored C, then we also color (M(a), M(b)) ∈ ℝ × ℝ. Under this map, non-monochromatic triangles stay non-monochromatic. So we’ve constructed a coloring on ℝ × ℝ with no monochromatic triangles!
If a coloring with no monochromatic right triangles exists, then the Continuum Hypothesis is true.
The proof outline here is to show that any infinite subset A of ℝ either has cardinality ℵ0 or 2ℵ0. This shows that there are no intermediate cardinalities between these two.
Consider any infinite subset A ⊆ ℝ. For any a, define Ya to be the y-coordinates of points along the vertical line through (a, 0) that have no color repeats on that line. So Ya = {y ∈ ℝ | the color of (a, y) is different from (a, y’) for all y’ ≠ y}.
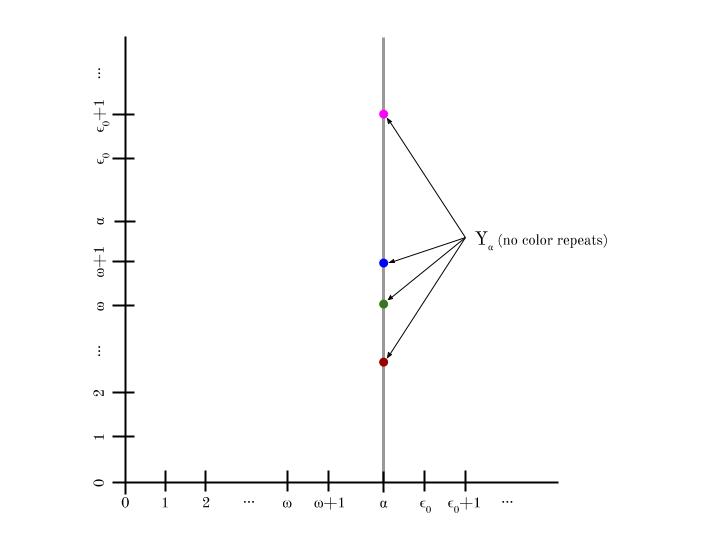
Notice that Ya must be countable, because all its elements have different colors and there are only countably many different colors to have. So |Ya| = ℵ0.
Define YA to be the union of Ya, for each a in A. Since each Ya is countable and A is at least ℵ0, |YA| ≤ |A|⋅ℵ0 = |A|. There are two cases: either YA = ℝ, or YA ≠ ℝ.
Case 1: YA = ℝ. In this case |ℝ| = |YA| ≤ |A|, so |A| ≥ |ℝ|. Since A is a subset of ℝ, this implies that |A| = |ℝ|.
Case 2: YA ≠ ℝ. In this case, there’s some real number y* in ℝ – YA. By definition y* is outside YA, so for each vertical line {x} × ℝ there is at least one point with the same color as (x, y*) besides itself.
Each (x, y*) with x ∈ A must have a different color. Proof: Suppose not. Then we have two elements of A, x1 and x2, such that the color of (x1, y*) is the same as the color of (x2, y*). By the last paragraph’s result, we can pick a third point (x1, y’) that has the same color as (x1, y*). These three points form a monochromatic right triangle, but we’ve assumed that’s impossible! Contradiction.
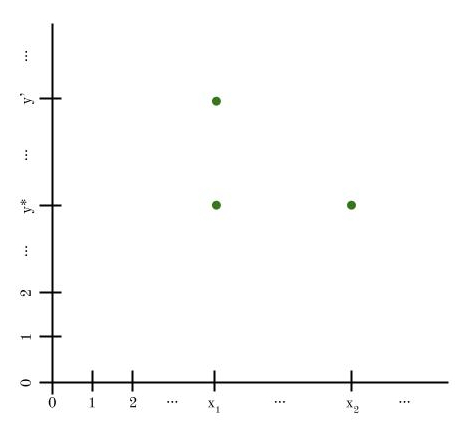
So each point in A × {y*} must have a different color. Thus, the cardinality of A × {y*} must be countable. And A is an infinite set, so |A| = ℵ0.
So in case one |A| = |ℝ| = 2ℵ0, and in case two |A| = ℵ0. And this is true for every infinite subset A of ℝ. So every subset of ℝ is either finite, countable, or has the same cardinality as ℝ. And this is the continuum hypothesis!