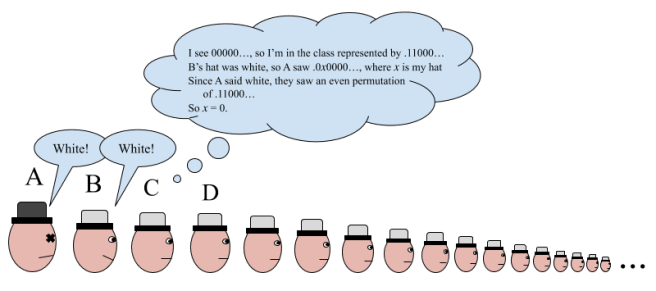A few years ago, Scott Aaronson and a student of his published this paper, in which they demonstrate the existence of a 7918 state Turing machine whose behavior is independent of ZFC. In particular, whether the machine halts or not can not be proven by ZFC. This entails that ZFC cannot prove the value of BB(7918) – the number of steps taken by the longest running Turing machine with 7918 states before halting. And since ZFC is a first order theory and first order logic is complete, the unprovability of the value entails that BB(7918) actually has different values in different models of the axioms! So ZFC does not semantically entail its value, which is to say that ZFC underdetermines the Busy Beaver numbers!
This might sound really surprising. After all, the Busy Beaver numbers are a well-defined sequence. There are a finite number of N-state Turing machines, some subset of which are finitely-running. Just look at the number of steps that the longest-running of these goes for, and that’s BB(N). It’s one thing to say that this value is impossible to prove, but what could it mean for this value to be underdeterminedby the standard axioms of math? Are there some valid versions of math in which this machine runs for different amounts of time than others? But how could this be? Couldn’t we in principle build the Turing machine in the real world and just observe exactly how long it runs for? And if we did this, then we certainly shouldn’t expect to get an indeterminate answer. So what gives?
Well, first of all, the existence of a machine like Aaronson and Yedidia’s is actually not a surprise. For any consistent theory T whose axioms are recursively enumerable, one can build a Turing machine M that enumerates all the syntactic consequences of the axioms and halts if it ever finds a contradiction. That is, M simply starts with the axioms, and repeatedly applies modus ponens and the other inference rules of T’s logic until it reaches a contradiction. Now, if T is strong enough to talk about the natural numbers, then it cannot prove whether or not M halts. This is a result of Gödel’s Second Incompleteness Theorem: If T could prove the behavior of M, then it could prove its own consistency, which would entail that it is inconsistent. This means that no consistent formal theory will be capable of proving all the values of the Busy Beaver numbers; for any theory T there will always be some number N for which the value of BB(N) is in principle impossible to derive from T.
On the other hand, this does not entail that the Busy Beaver numbers do not have definite values. This misconception arises from two confusions: (1) independence and unprovability are not the same thing, and (2) independence does not necessarily mean that there is no single right answer.
On (1): A proposition P is independent of T if there are models of T in which P is true and other models in which it is false. P is unprovable from T if… well, if it can’t be proved from the axioms of T. Notice that independence is a semantic concept (having to do with the different models of a theory), while unprovability is a syntactic one (having only to do with what you can prove using the rules of syntax in T). Those two are equivalent in first order logic, but only because it’s a complete logic: Anything that’s true in all models of a first-order theory is provable from its axioms, so if you can’t prove P from T’s axioms, then P cannot be true in all models; i.e. P is independent. Said another way, first-order theories’ semantic consequences are all also syntactic consequences.
But this is not so in second-order logic! In a second-order theory T, X can be unprovable from T but still true in all models of T. There is a gap between the semantic and the syntactic, and therefore there is a corresponding gap between independence and unprovability.
So while it’s true that the Busy Beaver numbers are independent of any first-order theory you choose, it’s not true that the Busy Beaver numbers are independent of any second-order theory that you choose. We can perfectly well believe that all the Busy Beaver numbers have unique values, which are fixed by some set of second-order axioms, and we just cannot derive the values from these axioms.
And on (2): Even the independence of the Busy Beaver numbers from any first order theory is not necessarily so troubling. We can just say that the Busy Beaver numbers do have unambiguous values, it’s just that due to first-order logic’s expressive limitations, we cannot pin down exactly the model that we want.
In other words, if BB(7918) is 𝑥 in one model and 𝑥+1 in another, this does not have to mean that there is some deep ambiguity in the value of BB(7918). It’s just that only one of the models of your theory is the intended model, the one that’s actually talking about busy beaver numbers and Turing machines, and the other models are talking about some warped version of these concepts.
Maybe this sounds a little fishy to you. How do we know which model is the “correct” one if we can’t ever rule out its competitors?
Well, the inability of first order logic to get rid of these nonstandard models is actually basic feature of pretty much any mathematical theory. In first-order Peano arithmetic, for instance, we find that we cannot rule out models that contain an uncountable number of “natural numbers”. But we don’t then say that we do not know for sure whether or not there are an uncountable infinity of natural numbers. And we certainly don’t say that the cardinality of the set of natural numbers is ambiguous! We just say that unfortunately, first order logic is unable to rule out those uncountable models that don’t actually represent natural numbers.
If this is an acceptable response here, if you find it tempting to say that the inability of first order theories of arithmetic to pin down the cardinality of the naturals tells us nothing whatsoever about the natural numbers’ actual cardinality, then it should be equally acceptable to say of the Busy Beaver numbers that the independence of their values from any given mathematical theory tells us nothing about their actual values!
Sets are more fundamental than integers. We like to think that mathematics evolved from arithmetics and the need to count how many animals are in a group, or something. But first you need to identify a collection, and know that you want that specific collection to be counted. If anything, numbers evolved from the need to assign cardinality to sets.
Asaf Karagila
Ask a beginning philosophy of mathematics student why we believe the theorems of mathematics and you are likely to hear, “because we have proofs!” The more sophisticated might add that those proofs are based on true axioms, and that our rules of inference preserve truth. The next question, naturally, is why we believe the axioms, and here the response will usually be that they are “obvious”, or “self-evident”, that to deny them is “to contradict oneself” or “to commit a crime against the intellect”. Again, the more sophisticated might prefer to say that the axioms are “laws of logic” or “implicit definitions” or “conceptual truths” or some such thing.
Unfortunately, heartwarming answers along these lines are no longer tenable (if they ever were). On the one hand, assumptions once thought to be self-evident have turned out to be debatable, like the law of the excluded middle, or outright false, like the idea that every property determines a set. Conversely, the axiomatization of set theory has led to the consideration of axiom candidates that no one finds obvious, not even their staunchest supporters. In such cases, we find the methodology has more in common with the natural scientist’s hypothesis formation and testing than the caricature of the mathematician writing down a few obvious truths and proceeding to draw logical consequences.
Penelope Maddy, Believing the Axioms
This time we’re going to tackle something very exciting: ZFC set theory. There is no consensus on what exactly serves as the best foundations for mathematics, and there are a bunch of debates between set theorists, type theorists, intuitionists, and category theorists about this. But one thing that nobody doubts is that the concept of a set is extremely fundamental, and naturally pops up everywhere in math. And whether or not ZFC set theory is the best foundations for mathematics, it certainly serves as a solid foundation for a massive amount of it.
We start with the following question: What is a set? Intuitively, we all have a concept of a set which is something like “a set is a well-defined collection of objects.” It turns out that precisely formalizing this, successfully designing an axiom set that captures our intuitive concept of a set without giving rise to paradoxes, is no small feat. Many decades of many of our smartest people working on this problem have culminated in today’s standard formulation: Zermelo-Fraenkel set theory. We’ll go through this formulation axiom by axiom, motivating each one as we go. But before we get to the axioms, a few notes are in order.
First of all, we need to specify our language. We’re going to try to formulate our theory of sets in first-order logic, so to specify our language we’ll need to fill in the constants, predicates, and functions in the language. Amazingly, it’ll turn out that all we need to manually insert into the language is a single binary predicate: ∈. ∈(x,y) will commonly written as x ∈ y, and should be read as “x is an element of y”. All the other set relationships that we care about will be definable in terms of ∈ and the standard symbols of first order logic.
Second important note: our theory of sets will contain only sets and nothing else. This is a little weird; we ordinarily think of sets as being like cardboard boxes that can contain other types of objects besides other sets. But sets for us will be, in the words of Scott Aaronson, “like a bunch of cardboard boxes that you open only to find more cardboard boxes, and so on all the way down.” We could make a two-sorted first-order theory, where some of the objects are sets and others are things-that-are-contained-in-sets (sometimes called urelements), but this would be more complicated than what we need.
(In case you didn’t know what boxes-in-boxes would look like)
So! These two clarifications aside, we are ready to dive into our theory of sets. We will be designing a first-order theory with a single binary predicate ∈, and where all the objects in any model of the theory will be sets. Our first axiom, which you’ll see in every axiomatization of set theory, will be the following:
Here’s what that says in plain English: Take any two sets 𝑥 and 𝑦. If it’s the case that any element of 𝑥 is also an element of 𝑦, and vice versa, then it must be the case that 𝑥 = 𝑦. In plainer English, two sets are the same if they have all the same elements. (The converse of this is guaranteed by the substitution rule of equality: if two sets are the same, then they must have the same elements).
This tells us that a set is defined by its elements. For any set 𝑥, if you were to list all of its members, you have fully specified everything there is to specify about the set. If there was something else you could say about the set that could further distinguish it, then that would mean that two sets with the same members could be distinguished somehow, which they can’t.
Among other things, this tells us that the set {𝑥, 𝑥} is the same thing as the set {𝑥}, because there’s no difference between a set containing 𝑥 “twice” and a set containing 𝑥 “once”. All you can ask of a set 𝑦 is the following: “Is it the case that 𝑥∈𝑦?”, which doesn’t distinguish between 𝑦 = {𝑥} and 𝑦 = {𝑥, 𝑥}. Notice that we’re already slightly violating the intuitive concept of a set as just a bag of things. If a set is defined by what it contains, then it seems reasonable that a set could contain two sets that have the same contents. But “two sets with the same contents” are in fact just one set, by the axiom of extensionality. So in this axiomatization, sets cannot contain duplicates!
Another consequence of the axiom of extensionality is that the set {𝑥, 𝑦} is the same thing as the set {𝑦, 𝑥}. A set is just an unordered “bag” of things. Both those sets contain 𝑥 as well as 𝑦, and there’s no way to ask if 𝑥 comes “first” in the bag.
On to the next axiom! At this point, we’ve got the idea that a set is defined by its members. But we aren’t yet guaranteed the existence of any particular sets. This axiom we’ll introduce now is a good starting point for narrowing down our models to those that contain familiar sets. It actually usually doesn’t appear in most standard axiomatizations of set theory, but that’s only because it can be derived from axioms that we’ll introduce later.
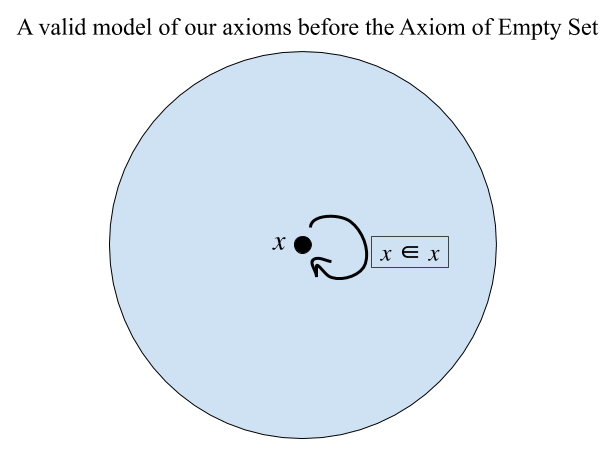
Axiom of Empty Set ∃𝑥∀𝑦 (𝑦 ∉ 𝑥)
This axiom declares the existence of a set 𝑥 that contains no sets. In other words, the empty set exists! This might seem extremely obvious, so much so that we shouldn’t even have to say it (how could there not be a set that contains nothing??) But if all we had was the Axiom of Extensionality, then there would be perfectly good models of our theory in which every set contained other sets. For example, we could have a model with exactly one set 𝑥 that contained itself and nothing else (i.e. a model that satisfied the equation ∀𝑥∀𝑦 (𝑥 = 𝑦∧𝑥∈𝑦)).
So the axiom of the empty set is necessary to constrain our set of models.
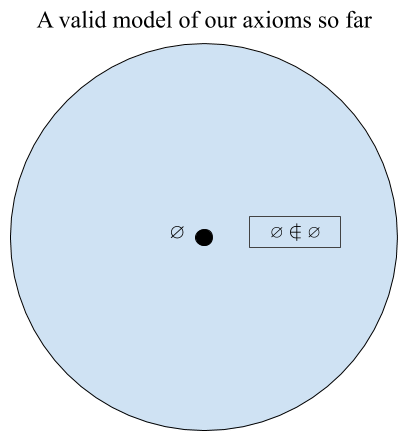
Now we are guaranteed a set with no members, but not guaranteed anything else. In particular, one model we have at this point is that there is just the empty set:
We can amend this by making the following conceptual observation: from any set 𝑥, we can form a new set 𝑦 which contains 𝑥 as an element and nothing else. In other words, you can take any set, package it up, and form a new set out of it! Let’s write this formally.
Axiom of Superset ∀𝑥∃𝑦∀𝑧 (𝑧 ∈ 𝑦 ↔ 𝑧 = 𝑥)
For any set 𝑥, there exists another set 𝑦, such that every element 𝑧 in 𝑦 is equal to 𝑥. Or in other words, every set has another set that contains it and only it. This is a fine axiom, but you’ll never see it in any presentation of the axioms of ZFC. This is again an issue of redundancy, which will be made clear in about 30 seconds, so just hang on.
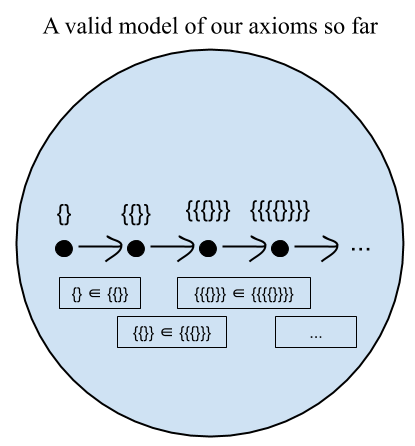
So far we have the existence of the empty set, commonly written ∅. By our new axiom, we also have {∅}, {{∅}}, {{{∅}}}, and so on. But are we guaranteed that these are different objects in every model, or could they be different names for the same objects in some model? For instance, is it possible that ∅ = {∅}? Well, let’s check: Suppose that they are equal. Then, by the substitution property of equality, it would have to be the case that every set inside ∅ is also inside {∅}. But here’s an element of {∅} that isn’t inside ∅: ∅ itself! The empty set contains nothing, whereas the set of the empty set contains something, namely, the empty set! So ∅ and {∅} must be distinct. Similar arguments can be extended to demonstrate that this entire infinite chain of constructions ∅, {∅}, {{∅}}, {{{∅}}}, and so on has no duplicates. So we’ve just ruled out all finite models!
On to the next axiom. Take a look at our collection of “guaranteed” sets and think about what’s missing.
∅, {∅}, {{∅}}, {{{∅}}}, {{{{∅}}}}, …
One thing that’s obviously missing is sets consisting of pairs of any two of these elements. For example, we don’t ever get {∅, {∅}} or {∅, {{∅}}}.
And of course, conceptually, we should be able to take any two sets and form a new set composed of just those two. This will be our next axiom.
Axiom of Pairing ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 = 𝑥 ∨ 𝑤 = 𝑦))
For any two sets x and y, there exists another set z, such that any w is an element of z if and only if it’s either x or y. In other words, z contains just x and y and nothing else.
Take a look at what happens when we pair a set 𝑥 with itself. We just get back {𝑥}! Now we see why the Axiom of Superset was unnecessary: it was just a special case of the Axiom of Pairing.
Alright, now with this new axiom our collection of sets that must exist in every model is becoming pretty complicated. We have those same ones as before:
∅, {∅}, {{∅}}, {{{∅}}}, {{{{∅}}}}, …
But also, now:
{∅, {∅}}, {∅, {{∅}}), {{∅}, {{∅}}), …
Taking pairs and pairs of pairs and so on, we can get arbitrarily complicated sets. So now do we have everything that we want to guarantee exist as sets? I want you to think about if there are any sets we can form out of ∅ that we don’t have yet.
(…)
How about {∅, {∅}, {{∅}}}? Interestingly, we can’t yet get this. We could try pairing {∅, {∅}} with {{∅}}, but that would get us {{∅, {∅}}, {{∅}}}, not {∅, {∅}, {{∅}}}. Essentially, the issue is that any application of the pairing axiom always results in a set with at most two members (even though each of those members might contain more sets). You can never get a set with three or more elements!
The immediate thought might be to add a tripling axiom to complement our pairing axiom. But then we’re just kicking the can down the road, moving the problem one level higher. We’d need a quadrupling axiom as well, as well as a quintupling, and so on forever. That’s not really elegant… is there a way that we can get all of these axioms in one step? Well, the obvious way to do this (quantifying over the n in “n-tupling”) isn’t really accessible to us without second-order logic. So we have to be cleverer.
I encourage you to think about this for a minute. Can you think of a way to guarantee the existence of sets with any numbers of members like {∅, {∅}, {{∅}}} and {∅, {∅}, {{∅}}, {{{∅}}}}?
(…)
It turns out that there is! We just have to take a little bit of an indirect approach. Here’s the axiom that will do the trick:
Axiom of Union ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 ∈ 𝑥 ∨ 𝑤 ∈ 𝑦))
In English: Take any two sets 𝑥 and 𝑦. There exists a new set 𝑧 consisting of everything that’s in either 𝑥 or 𝑦. In other words, the union of 𝑥 and 𝑦 exists! We write this as 𝑥∪𝑦. (Strictly speaking, the axiom of union is typically formalized as saying that the union of any set of sets exists, not just any set of two sets, but this simpler formulation will do for the moment. This other version will only become relevant when we start talking about infinity.)
Say we want to form the set {𝑥, 𝑦, 𝑧}. We first pair 𝑥 with 𝑦 to get the set {𝑥, 𝑦}. Then we pair 𝑧 with itself to get {𝑧}. Now we just union {𝑥, 𝑦} with {𝑧}, and we’re there! You can easily see how this can be extended to arbitrarily complicated combinations of sets.
If you take a few minutes to try to think about everything we can get from just these two axioms, you might convince yourself that we’ve gotten everything. No matter how complicated it looks, you can take any finite set of ∅-members, and see how you can bring together its components using just pairing and union. Each of these components is simpler than the set that contained them all, so we can do the same to them. And eventually we can retrace the whole tree of pairings and unions back to ∅.
But there’s an important qualification there that’s easy to miss: we’ve gotten all the finite sets. Did we get the infinite ones? What about the following set?
{∅, {∅}, {{∅}}, {{{∅}}}, …}
Sure, we can construct any arbitrarily long but finite subset of this infinite set. But are we also guaranteed the whole thing?
It turns out that the answer is no. There is a perfectly consistent model of our axioms that contains no infinite sets, even though it contains arbitrarily large finite sets. There’s even a name for this collection of sets: the hereditarily finite sets! We can recursively define this collection by saying that ∅ is hereditarily finite, and that if a1, …, ak are hereditarily finite, then so is {a1,…,ak}.
For now, just note that since our current axioms allow a model in which no infinite sets exist, we cannot prove the existence of any infinite sets from them (if we could do so, then we could rule out Vω as a model). So if we want to be able to talk about infinity, we have to manually add it in as an axiom! (It’s at this point that the finitists get off board. It’s actually pretty interesting to me that to be a finitist, you don’t necessarily have to believe that there’s a largest set. You could think that sets get unboundedly large, and just refuse to make the additional assumption that sets can be infinitely large.)
ZFC has an axiom that assures the existence of an infinite set. But it isn’t the infinite set that I referenced earlier ({∅, {∅}, {{∅}}, {{{∅}}}, …}). Instead, it’s the following:
The coloring should help to see what’s going on here. Each set is just composed of one copy of every previous set in the sequence. And since each set contains all the previous sets, we can easily define the next set in the sequence: the set after 𝑥 is 𝑥∪ {𝑥}. We’ll call this the successor to 𝑥. This sequence is known as the Von Neumann ordinals, and it’s the standard set-theoretic construction of the natural numbers:
Visualization of the first six Von Neumann ordinals
When we make this association between Von Neumann ordinals and numbers, and define a “successor set” this way, we can show that all the axioms of Peano arithmetic (translated to their set-theoretic version) hold for the set of all Von Neumann ordinals. This means that if we could guarantee the existence of the set {0, 1, 2, …} = {∅, {∅}, {∅, {∅}}, …}, then we could prove the consistency of PA within set theory!
Okay, so let’s write down the axiom that we need to give us an infinite set.
Axiom of Infinity ∃𝑥 (∅∈𝑥∧∀𝑦 (𝑦∈𝑥 → 𝑦∪ {𝑦} ∈𝑥))
(I’ve cheated a little bit here by using symbols like ∅, ∪, and {}, which aren’t technically in the language we’re provided. But for convenience, we’ll accept them as an abbreviation of the full formula, since we know how to translate back to ∈ in principle.)
This says that there exists a set that contains ∅, as well as 𝑦∪ {𝑦} for every 𝑦 inside it. So we’re guaranteed all the Von Neumann ordinals. But notice that this doesn’t tell us that only the Von Neumann ordinals are in this set! We could have all the Von Neumann ordinals, plus a bunch of other objects, as long as each of these objects has its “successor” in the set. In a sense, this is exactly like the problem we had before with PA; try as we might, we inevitably ended up with nonstandard numbers.
The amazing thing about doing this all in terms of sets is that now we actually can remove all the nonstandards! (EDIT: Coming back later to point out thatTHIS IS WRONG. You cannot rule out all nonstandard models of naturals in ANY first order theory, and I should have known better.) The crucial difference is that when doing PA, we couldn’t quantify over sets of numbers, as that would require second-order logic. But in the context of set theory, everything is a set, including numbers. So talking about all sets of numbers is totally do-able in first order!
We want to pare down our set somehow, by ruling out all the other possible sets in our infinite set. But how can we do this? So far, all of our axioms have been about creating new sets, or generating larger sets from existing ones. We don’t have anything that allows us to start with a set that’s too large and then remove some elements to get a smaller set.
Let’s design a new axiom to accomplish this goal. For any set 𝑥 that we have, we should be able to form a new set 𝑦 consisting of only members of 𝑥 that satisfy some property 𝜑 of our choice. Which property? Any of them! If we can define a predicate 𝜑 using some first-order expression, then we should be able to take the subset of any set that we have which satisfy this predicate. Here’s that written formally:
Axiom Schema of Comprehension/Specification ∀𝑥∃𝑦∀𝑧 (𝑧∈𝑦 ↔ (𝑧∈𝑥∧𝜑(𝑧)))
This is an axiom schema, because 𝜑 is just a stand-in for any formula that we choose. We could have 𝜑(𝑥) be the formula 𝑥 = 𝑥, in which case our subset will be the same as the starting set. Or we could have 𝜑(𝑥) be the formula 𝑥 ≠ 𝑥, in which case our subset would be the empty set. (And now you see why the axiom of empty set is redundant; it’s entailed by the existence of any set and the axiom of comprehension!) Basically, for any formula you can write, there’s a special case of the axiom of comprehension. We also can now use the useful set-builder notation: 𝑦 = {𝑧∈𝑥: 𝜑(𝑧)}.
We presented this axiom as a way to narrow down our infinite set to just the finite Von Neumann ordinals, so let’s see how exactly that works. We start with the set that we are granted by our axiom of infinity. Then we consider the subset of this set that satisfies the following property: 𝑥 is the empty set or a successor set, and each of its elements is either zero or a successor of another of its elements. In math, we write the property 𝜑(𝑥) as:
Now the set of finite Von Neumann ordinals is just the set obtained from our infinite set by specifying 𝜑(𝑥)! Okay, so we can get the set of finite Von Neumann ordinals using our axiom of comprehension. (Future me again. Once more, this is wrong. This formula does not actually define the set of the naturals, and no in fact formula does this, for subtle reasons involving the possibility of there existing undefinable infinite descending ∈-chains. However, it does define a set-theoretic object that resembles the natural numbers closely enough so that we can and do treat it as such for all intents and purposes.) But it should also be clear that comprehension can do a whole lot more than just this. We already saw that it gives us the axiom of empty set, but here’s a new example of something that we can do now with comprehension:
Earlier we introduced the axiom of union, and some of you that have familiarity with set theory might have also been expecting an axiom for intersection. The intersection of two sets is just the set of elements that are in both. But this will actually come out as a special case of comprehension! Namely, define 𝜑(𝑤,𝑦) to be the formula 𝑤∈𝑦. Then the set 𝑧 = {𝑤∈𝑥: 𝜑(𝑤,𝑦)} corresponds to the subset of 𝑥 that is also in 𝑦, i.e. the intersection of 𝑥 and 𝑦!
(Interestingly, you can’t use the axiom of comprehension to get unions. Do you see why?)
Historically, most of the mathematicians working on set theory in the early days of its axiomatization used a similar-sounding but much stronger axiom, known as unrestricted comprehension.
Axiom Schema of Unrestricted Comprehension ∃𝑥∀𝑦 (𝑦∈𝑥 ↔ 𝜑(𝑦))
This allows us to form a set out of the collection of ALL sets satisfying some property 𝜑 (not just those elements that you can find in some other existing sets). This is a much prettier and simpler axiom, and seems quite intuitive. Why wouldn’t we be able to just collect all the sets in any given model that satisfy a well-defined formula, and call that thing a set?
Amazingly, this very innocent-sounding axiom ends up destroying the consistency of set theory! This was the astonishing discovery of Bertrand Russell, known as Russell’s paradox. So why does this axiom lead us to a contradiction? Well, consider what you get when 𝜑(𝑦) is the first-order formula 𝑦∉𝑦. You get this set: 𝑥 = {𝑦: 𝑦∉𝑦}, which is the set of sets that don’t contain themselves. Now, if 𝑥 is a set, then either it’s in 𝑥 or it’s not in 𝑥. But hold on: if 𝑥 is inside 𝑥, then by the definition of 𝑥, it can’t contain itself! So it must not be inside 𝑥. But then it satisfies the condition for the sets that are in 𝑥! So since 𝜑(𝑥) is true, 𝑥 must be inside 𝑥 after all! This is a contradiction, and we are necessarily led to the conclusion that 𝑥 can’t have been a set in the first place. But 𝑥 being a set was guaranteed by unrestricted comprehension! And all we used was this and extensionality. So any theory of sets with unrestricted comprehension is inconsistent!
Needless to say, this is a big violation of our intuitive concept of sets. It turns out that you can’t just collect together all objects satisfying some well-defined property and form a set out of them! If you allow this, then you walk straight into a paradox. I think it’s fair to say that this proves that our intuitive concept of sets is actually incoherent. A mathematically consistent theory of sets must have more limitations than the way we imagine sets. In particular, all we will be allowed is restricted comprehension, the axiom from earlier, and we will not in general be allowed to form a new set by combing through the whole universe of sets for those that satisfy a certain property.
Notice, by the way, that restricted comprehension only gets us out of hot water if we don’t have a set that contains all sets. Otherwise, we could just do the exact same trick as before, by forming our paradoxical set as a subset of the set of all sets! So interestingly, the moment that we added restricted comprehension as an axiom, we ruled out any models that included a set that contained everything. Again, this is pretty unintuitive! Our theory of sets allows us to construct a bunch of well-defined sets, but if we collect those sets together, we get something that cannot be called a set, on pain of contradiction!
So, if we look at what we have now, we have all the hereditarily finite sets, as well as the set of all Von Neumann ordinals and many other infinite sets given by the axiom of comprehension (all the definable subsets of the Von Neumann ordinals). However, we’re still not done. Consider the set of all subsets of the Von Neumann ordinals. Can we construct this set somehow from our existing axioms? Cantor proved that we cannot with an ingenious argument that I would totally go through here if this post wasn’t already way too long. He showed that this set is strictly larger in cardinality than the set of Von Neumann ordinals (in particular, that it’s uncountably large), which entailed that we couldn’t get there by any application of the axioms we have so far.
So we need another axiom, to match our feeling that the power set of any set (the set of all its subsets) should itself be a set:
Axiom of Power Set ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ 𝑧⊆ 𝑥)
I’ve cheated again by using the subset symbol ⊆. But just like before, this is only for prettiness of presentation; we can always translate back from 𝑧⊆𝑥 to ∀𝑤 (𝑤∈𝑧 → 𝑤∈𝑥) if necessary. The combination of the power set axiom and the axiom of infinity give us what’s called the cumulative hierarchy (strictly speaking, we’re actually missing a few pieces of the hierarchy, but we’ll patch that in a few minutes). The power set of a set is strictly larger than it in cardinality, so by saying that every power set is a set, we get an infinite chain of increasingly large infinite sets. We have sets the size of the real numbers, as well as the size of all functions from the real numbers to themselves, and so on forever. (You might now start to get a sense of why this particular first-order theory is thought to be powerful enough to serve as a playing field for almost all of mathematics!)
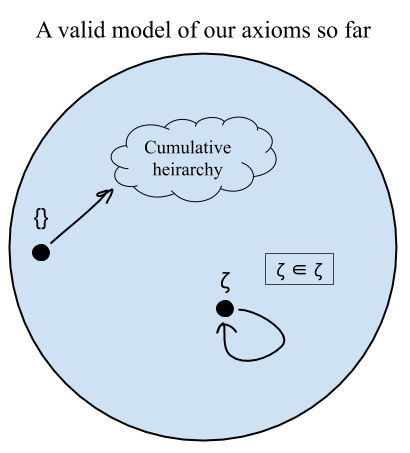
However, despite having guaranteed the existence of this whole enormous universe of sets, we still are not done. We’ve been slightly careless in how we’ve been talking so far; in particular, we have kind of been assuming that the only sets that exist are the ones that we are guaranteeing exist with our axioms. But we haven’t taken care to examine the possibility of models that include perverse objects that we don’t want to call sets in addition to our whole cumulative hierarchy of nice sets.
What do I mean by “perverse”? That’s a good question, and I don’t have a strict definition. The intuitive idea is that we might be able to construct weird nonstandard sets (like we did with numbers) that satisfy our axioms but have “un-set-like properties”, such as containing themselves or having an infinite descending membership chains.
For a simple example, we can imagine a model of our axioms so far that includes the entire cumulative hierarchy (the hereditarily finite sets, the set Vω, and the chain of power sets), plus another set ζ that contains only itself and nothing else. (You can tell that this is a perverse set because of the ugly symbol I used for it.) In other words, ζ = {ζ}. For this to be consistent with our axioms, we’d have to also include all the products of pairing and unioning ζ with our nice sets, like {ζ, ∅} and {ζ, ∅, {∅}}. But once we’ve done that, it’s not clear what we can say to rule out this model using our current axioms.
This turns out to be a big problem when we try using our axiom of restricted comprehension to get the set of Von Neumann ordinals (which is very important for getting our set theory to be able to talk about the natural numbers). I lied a little bit earlier (sorry!) when I said that we could get this set by talking about the sets in our infinite set that were either zero or a successor, and whose every element was either zero or a successor of another of their elements. If you think about this for a little bit, it makes sense why the Von Neumann ordinals fit this description. But that’s not the only thing that fits this description! We also get the set of all Von Neumann ordinals, plus an infinite descending chain of sets ζ = {ζ} = {{ζ}} = {{{…}}} and all their super sets! So to actually pin down the Von Neumann ordinals using comprehension, we need a new axiom that bans these perverse sets.
Here’s another weird thing you can get without banning perverse sets: suppose you have two sets ζ1 and ζ2, such that ζ1 ≠ ζ2, ζ1 = {ζ1}, and ζ2 = {ζ2}. Substituting in ζ1 for itself and ζ2 for itself, we have that ζ1 = {{{…}}} and ζ2 = {{{…}}}.
These two sets appear to have identical structure in terms of what elements they contain, but since ζ1 ≠ ζ2, they contain different elements, so they aren’t in violation of the Axiom of Extensionality! It feels like sets like these are slipping by on a technicality, while still violating the spirit of the Axiom of Extensionality. We can think about the following axiom as the extension of the principle that sets’ identities are solely determined by their elements to these perverse cases:
This says that every non-empty set must contain a set that shares no elements with it. At first glance it might not be obvious why this would help, so let’s take a closer look.
This axiom is automatically true of all of the sets in our cumulative hierarchy, because they all are built out of the empty set ∅, so that’s good. (If it was false of any of our guaranteed sets, then we’d have an inconsistency on our hands.) And it also rules out the set ζ that contains just itself. Why? Well, ζ = {ζ}, so the only element of ζ is itself. But ζ obviously shares elements with itself, because it is non-empty. So ζ doesn’t contain any sets that it shares no elements with! Therefore ζ is not a set.
What about something like ζ = {∅, ζ}? Now that ζ contains the empty set, it’s not in obvious violation of the axiom of regularity. But it is in fact in violation. Here’s the argument: Start with ζ. Pair it with itself to form {ζ}. Now ask, does {ζ} contain any sets that it shares no elements with? It’s easier to see if we expand this using the definition of ζ: {ζ} = {{∅, ζ}}. The problem is that {ζ} contains just one set, ζ, and ζ and {ζ} share an element: namely, ζ itself! So in fact, even adding the empty set won’t help us. The axiom of regularity rules out any sets that contain themselves.
In fact, the axiom of regularity rules out all sets besides those in the cumulative hierarchy. (Future me here: the axiom of regularity technically rules out the possibility of any definable sets outside the cumulative hierarchy, but not all sets.) Why is this? Well, take any set. Either it doesn’t contain elements, in which case it’s the empty set, or it does contain elements. If it does contain elements, then those elements either don’t contain elements (i.e. are the empty set), or do contain elements. If the second, then we look at those elements, and so on. By regularity, we don’t have infinite descending chains of sets, so this process will eventually terminate. And the only way for it to terminate is that each branch ends in the empty set!
So we’ve basically pinned down our universe of sets! It’s just ∅ and all the things we can make out of it. Wait… what? All sets are ultimately just formed from the empty set? That seems a little weird, right?
Yes, there is something a little strange about this formalization of sets. Ultimately, this comes down to our starting desire to have our theory be about sets and only sets. From the start we made the decision to not talk about “urelements”, the term for non-set elements of sets. And by making a strong requirement that sets are defined by their elements, we ended up concluding that all sets are ultimately built out of ∅. The nice thing is that our universe of sets is so large that we can find within it substructures that are isomorphic to models of most of the mathematical structures that we are interested in understanding, even though it all just comes from ∅.
Okay, let’s take a step back and summarize everything that we have so far. Here are our axioms (with some redundancy):
Axiom of Extensionality ∀𝑥∀𝑦 (∀𝑧(𝑧∈𝑥 ↔ 𝑧∈𝑦) → 𝑥 = 𝑦) Axiom of Empty Set ∃𝑥∀𝑦 (𝑦∉𝑥) Axiom of Pairing ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 = 𝑥 ∨ 𝑤 = 𝑦)) Axiom of Union ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 ∈ 𝑥 ∨ 𝑤 ∈ 𝑦))
Axiom of Infinity ∃𝑥 (∅∈ 𝑥 ∧∀𝑦 (𝑦 ∈ 𝑥 → 𝑦 ∪ {𝑦} ∈ 𝑥)) Axiom Schema of Comprehension ∀𝑥∃𝑦∀𝑧 (𝑧∈𝑦 ↔ (𝑧∈𝑥∧𝜑(𝑧))) Axiom of Power Set ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ 𝑧⊆ 𝑥) Axiom of Regularity ∀𝑥 (𝑥 ≠ ∅ → ∃𝑦 (𝑦∈𝑥∧𝑥⋂𝑦 = ∅))
At this point we’ve reached the ‘Z’ in ‘ZFC’. The other two letters stand for one axiom each. The ‘F’ is for Abraham Fraenkel, who realized that these axioms still don’t allow us to prove the existence of all the infinite sets we want. In particular, he proved that we aren’t yet guaranteed the existence of the set {ℕ, 𝒫(ℕ), 𝒫(𝒫(ℕ)), …}, where ℕ is the set of Von Neumann ordinals, and 𝒫(𝑥) is the power set of 𝑥. To fill in this set and the rest of the cumulative hierarchy, he proposed adding an immensely powerful axiom schema:
This is another axiom schema, because there is one instantiation for every definable function f. In plain English, it says that the image of any set 𝑥 under any definable function f is a set. With this axiom, we have what’s called ZF set theory.
Replacement is really strong, and its addition obviates a few of our existing axioms (pairing and comprehension, in particular). Here’s ZF set theory, with only the independent axioms:
Axiom of Extensionality ∀𝑥∀𝑦 (∀𝑧(𝑧∈𝑥 ↔ 𝑧∈𝑦) → 𝑥 = 𝑦) Axiom of Union ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 ∈ 𝑥 ∨ 𝑤 ∈ 𝑦))
Axiom of Infinity ∃𝑥 (∅∈ 𝑥 ∧∀𝑦 (𝑦 ∈ 𝑥 → 𝑦 ∪ {𝑦} ∈ 𝑥)) Axiom of Power Set ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ 𝑧⊆ 𝑥) Axiom of Regularity ∀𝑥 (𝑥 ≠ ∅ → ∃𝑦 (𝑦∈𝑥∧𝑥⋂𝑦 = ∅)) Axiom Schema of Replacement ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ ∃𝑤(𝑤 ∈ 𝑥 ∧ 𝑧 = f(𝑤)))
These six axioms give us ALMOST everything. There’s just one final axiom to fill in, which is historically the most controversial of all: the axiom of choice.
Here’s what the axiom of choice says: There’s always a way to pick exactly one element from each of any collection of non-empty disjoint sets, and form a new set consisting of these elements. Visually, something like this is always possible:
Here’s the common analogy given when explaining the axiom of choice, due to Bertrand Russell:
A millionaire possesses an infinite number of pairs of shoes, and an infinite number of pairs of socks. One day, in a fit of eccentricity, the millionaire summons his valet and asks him to select one shoe from each pair. When the valet, accustomed to receiving precise instructions, asks for details as to how to perform the selection, the millionaire suggests that the left shoe be chosen from each pair. Next day the millionaire proposes to the valet that he select one sock from each pair. When asked as to how this operation is to be carried out, the millionaire is at a loss for a reply, since, unlike shoes, there is no intrinsic way of distinguishing one sock of a pair from the other. In other words, the selection of the socks must be truly arbitrary.
Of course, with socks in the real world we could always just say something like “from each pair, choose the sock that is closer to the floor”. In other words, we can describe the resulting set in terms of some arbitrary relational property of the sock to the external world. But in the abstract world of set theory, all that we have are the intrinsic features of sets. If a set’s elements are intrinsically indistinguishable to us, then how can we choose one out of them?
This is a very imperfect analogy. For one thing, it suggests that we shouldn’t be able to choose one sock from each of a finite collection of pairs of socks. But this is actually do-able in every first-order theory! It’s a basic rule of first-order logic that from ∃𝑥𝜑(𝑥) we can derive 𝜑(𝑦), so long as 𝑦 is a new variable that has not been used before. So if we are told that a set has two members, then we are guaranteed by the underlying logic the ability to choose one of them, even if we are told nothing at all that distinguishes these two members from each other. The problem really only arises when we have an infinite set of pairs of socks, and thus have to make an infinity of arbitrary choices. Proofs are finite, so any statement we can derive will only have a finite number of applications of existential instantiation. So even though we can choose from arbitrarily large but finite sets of sets with just ZF, we need the axiom of choice to choose from infinite sets.
That looks complicated as heck, but all it’s saying is that for any set 𝑥 whose elements are all nonempty and disjoint sets, there exists a set 𝑦 such that for all 𝑧 in 𝑥, 𝑧 and 𝑦 share exactly 1 element. |𝑤| = 1 is shorthand for ∃𝑢 (𝑢∈𝑤∧∀𝑣 (𝑣∈𝑤 → 𝑢 = 𝑣)); 𝑤 contains at least one element 𝑢 and any other elements of 𝑤 are equal to 𝑢.
Here are some statements that are equivalent to the axiom of choice in first-order logic:
Any first-order theory with at least one model of infinite cardinality κ also has at least one model of any infinite cardinality smaller than κ.
The Cartesian product of non-empty sets is non-empty.
The cardinalities of any two sets are comparable.
For any set, you can construct a strict total order such that all of its subsets have a least element.
The cardinality of an infinite set is equal to the cardinality of its square.
Every vector space has a basis.
Every commutative ring with identity has a maximal ideal.
For any set 𝑥 and any onto function f: 𝑥 → 𝑥, f has an inverse.
And here are some statements that are not equivalent to AC, but implied by it:
Compactness Theorem for first-order logic
Completeness Theorem for first-order logic
The law of the excluded middle
Every infinite set has a countable subset.
Every field has an algebraic closure.
There is a non-measurable set of real numbers.
A solid sphere can be split into finitely many pieces which can be reassembled to form two solid spheres of the same size.
That’s right, to prove the Compactness Theorem for first-order logic, you actually need to use the axiom of choice! This means that you can take ZF, add the negation of the axiom of choice, and end up with a first-order model in which compactness doesn’t hold! (A construction of just such a theory can be found here).
And indeed, you can also construct models of ZF¬C in which the Completeness Theorem doesn’t hold! It’s no exaggeration to say that the Compactness Theorem and Completeness Theorem are two of the most important results about first-order logic, so their reliance on the axiom of choice gives us pretty good reason to accept it. (Although technically we only need to accept a slightly weaker version of the axiom of choice tailor-made for these theorems.)
And there you have it, ZFC set theory! Here’s a list of all the axioms we discussed:
Axiom of Extensionality ∀𝑥∀𝑦 (∀𝑧(𝑧∈𝑥 ↔ 𝑧∈𝑦) → 𝑥 = 𝑦) Axiom of Empty Set ∃𝑥∀𝑦 (𝑦∉𝑥) Axiom of Pairing ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 = 𝑥 ∨ 𝑤 = 𝑦)) Axiom of Union ∀𝑥∀𝑦∃𝑧∀𝑤 (𝑤 ∈𝑧↔ (𝑤 ∈ 𝑥 ∨ 𝑤 ∈ 𝑦))
Axiom of Infinity ∃𝑥 (∅∈ 𝑥 ∧∀𝑦 (𝑦 ∈ 𝑥 → 𝑦 ∪ {𝑦} ∈ 𝑥)) Axiom Schema of Comprehension ∀𝑥∃𝑦∀𝑧 (𝑧∈𝑦 ↔ (𝑧∈𝑥∧𝜑(𝑧))) Axiom of Power Set ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ 𝑧⊆ 𝑥) Axiom of Regularity ∀𝑥 (𝑥 ≠ ∅ → ∃𝑦 (𝑦∈𝑥∧𝑥⋂𝑦 = ∅)) Axiom Schema of Replacement ∀𝑥∃𝑦∀𝑧 (𝑧∈ 𝑦 ↔ ∃𝑤(𝑤 ∈ 𝑥 ∧ 𝑧 = f(𝑤))) Axiom of Choice ∀𝑥 ([∀𝑧 (𝑧∈𝑥 → (𝑧 ≠ ∅∧∀𝑤 ((𝑤∈𝑥∧𝑧 ≠ 𝑤) → (𝑧∩𝑤) = ∅)))] → ∃𝑦∀𝑧 (𝑧∈𝑥 → |𝑧∩𝑦| = 1))
I was planning on going into some of the fun facts about and implications of ZFC set theory in this post, but since I’ve gone on for way too long just defining the theory, I will save this for the next post! For now, then, I leave you with a pretty picture:
This post is about the most startling puzzle I’ve ever heard. First, two warm-up hat puzzles.
Four prisoners, two black hats, two white hats
Four prisoners are in a line, with the front-most one hidden from the rest behind a wall. Each is wearing a hat, but they can’t see its color. There are two black hats and two white hats, and all four know this.
As soon as any prisoner figures out the color of their own hat, they must announce it. If they’re right, everybody goes free. They cannot talk to each other or look any direction but forwards.
Are they guaranteed freedom?
Solution
Yes, they are! If D sees the same color hat on B and C’s heads, then he can conclude his own hat’s color is the other, so everybody goes free. If he sees differently colored hats, then he cannot conclude his hat color. But C knows this, so if D doesn’t announce his hat color, then C knows that his hat color is different from B’s and they all go free. Done!
Next:
Ten prisoners, unknown number of black and white hats
Each prisoner is randomly assigned a hat. The number of black and white hats is unknown. Starting from the back, each must guess their hat color. If it matches they’re released, and if not then they’re killed on the spot. They can coordinate beforehand, but cannot exchange information once the process has started.
There is a strategy that gives nine of the prisoners 100% chance of survival, and the other a 50% chance. What is it?
Solution
A10 counts the number of white hats in front of him. If it’s odd, he says ‘white’. Otherwise he says ‘black’. This allows each prisoner to learn their own hat color once they hear the prisoner behind them.
— — —
Alright, now that you’re all warmed up, let’s make things a bit harder.
Countably infinite prisoners, unknown number of black and white hats, no hearing
There are a countable infinity of prisoners lined up with randomly assigned hats. They each know their position in line.
The hat-guessing starts from A1 at the back of the line. Same consequences as before: the reward for a right guess is freedom and the punishment for a wrong guess is death.
The prisoners did have a chance to meet and discuss a plan beforehand, but now are all deaf. Not only can they not coordinate once the guessing begins, but they also have no idea what happened behind them in the line.
The puzzle for you is: Can you find a strategy that ensures that only finitely many prisoners are killed?
Oh boy, the prisoners are in a pretty tough spot here. We’ll give them a hand; let’s allow them logical omniscience and the ability to memorize an uncountable infinity of information. Heck, let’s also give them an oracle to compute any function they like.
Give it a try!
(…)
(…)
Solution
Amazingly, the answer is yes. All but a finite number of prisoners can be saved.
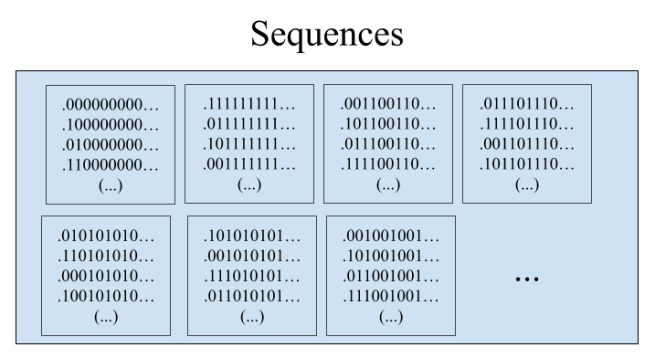
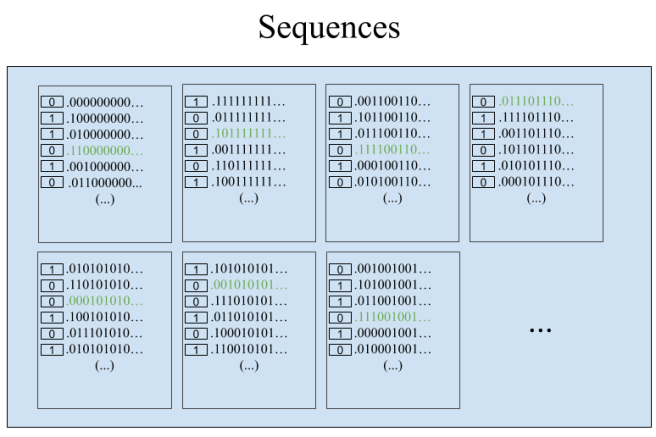
Here’s the strategy. First start out by identifying white hats with the number 0, and black hats with the number 1. Now the set of all possible sequences of hats in the line is the set of all binary sequences. We define an equivalence relation on such sequences as follows: 𝑥 ~ 𝑦 if and only if 𝑥 and 𝑦 are identical after a finite number of digits in the sequence. This will partition all possible sequences into equivalence classes.
For example, the equivalence class of 0 will just be the subset of the rationals whose binary expansion ends at some point (i.e. the subset of the rationals that can be written as an integer over a power of 2). Why? Well, if a binary sequence 𝑥 is equivalent to .000000…, then after a finite number of digits of 𝑥, it will have to be all 0s forever. And this means that it can be written as some integer over a power of 2.
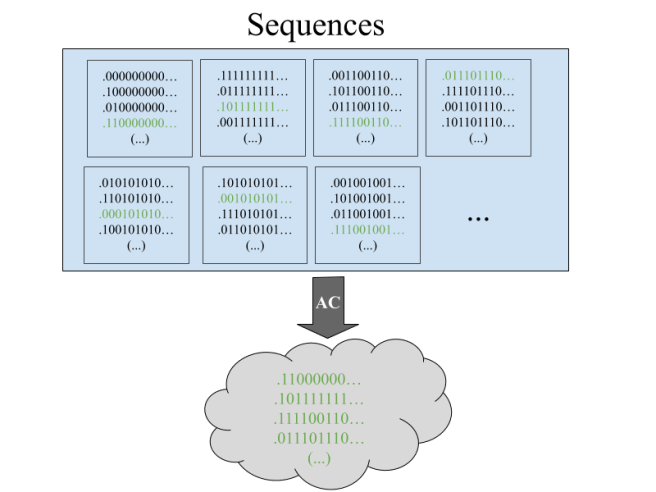
When the prisoners meet up beforehand, they use the axiom of choice to select one representative from each equivalence class. (Quick reminder: the axiom of choice says that for any set 𝑥 of nonempty disjoint sets, you can form a new set that shares exactly one element with each of the sets in 𝑥.) Now each prisoner is holding in their head an uncountable set of sequences, each one of which represents an equivalence class.
Once they’re in the room, every prisoner can see all but a finite number of hats, and therefore they know exactly which equivalence class the sequence of hats belongs to. So each prisoner guesses their hat color as if they were in the representative sequence from the appropriate equivalence class. Since the actual sequence and the representative sequence differ in only finitely many places (all at the start), all entries are going to be the same after some finite number of prisoners. So every single prisoner after this first finite batch will be saved!
This result is so ridiculous that it actually makes me crack up thinking about it. There is surely some black magic going on here. Remember, each prisoner can see all the hats in front of them, but they know nothing about the total number of hats of each color, so there is no correlation between the hats they see and the hat on their head. And furthermore, they are deaf! So they can’t learn any new information from what’s going on behind them! They literally have no information about the color of their own hat. So the best that each individual could do must be 50/50. Surely, surely, this means that there will be an infinite number of deaths.
But nope! Not if you accept the axiom of choice! You are guaranteed only a finite number of deaths, just a finite number that can be arbitrarily large. How is this not a contradiction? Well, for it to be a contradiction, there has to be some probability distribution over the possible outcomes which says that Pr(finite deaths) = 0. And it turns out that the set of representative sequences form a non-measurable set (a set which cannot have a well-defined size using the ordinary Lebesgue measure). So no probability can be assigned to it (not zero probability, literally undefined)! Now remember that zero deaths occur exactly when the real sequence is one of the representative sequences. This means that no probability can be assigned to this state of affairs. The same thing applies to the state of affairs in which one prisoner dies, or two prisoners, and so on. You literally cannot define a probability distribution over the number of prisoners to die.
By the way, what happens if you have an uncountable infinity of prisoners? Say we make them infinitely thin and then squeeze them along the real line so as to populate every point. Each prisoner can see all but a finite number of the other prisoner’s hats. Let’s even give them hats that have an uncountable number of different colors. Maybe we pick each hat color by just randomly selecting any frequency of visible light.
Turns out that we can still use the axiom of choice to guarantee the survival of all but finitely many prisoners!
Colbert’s reaction when he first learned about the uncountable version of the hat problem
One last one.
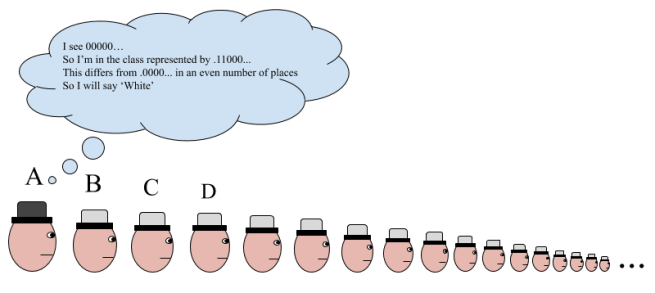
Countably infinite prisoners, unknown number of black and white hats, with hearing
We have a countable infinity of prisoners again, each with either a black or white hat, but this time they can hear the colors called out by previous prisoners. Now how well can they do?
The answer? (Assuming the axiom of choice) Every single prisoner can be guaranteed to survive except for the first one, who survives with 50% probability. I really want this to sink in. When we had ten prisoners with ten hats, they could pull this off by using their knowledge of the total number of black and white hats amongst them. Our prisoners don’t have this anymore! They start off knowing nothing about the number of white and black hats besides what they can see in front of them. And yet they still get out of it with all but one prisoner guaranteed freedom.
How do they do this? They start off same as before, defining the equivalence relation and selecting a representative sequence from each equivalence class. Now they label every single sequence with either a 0 or a 1. A sequence gets a 0 if it differs from the representative sequence in its equivalence class in an even number of places, and otherwise it gets a 1. This labeling has the result that any two sequences that differ by exactly one digit have opposite labels.
Now the first person (A) just says the label of the sequence he sees. For the next person up (B), this is the sequence that starts with their hat. And remember, they know which equivalence class they’re in, since they can see everybody in front of them! So all they need to do is consider what the label of the sequence starting with them would be if they had a white hat on. If it would be different than the label they just heard, then they know that their hat is black. And if it would be the same, then their hat is white!
The person in front of B knows the equivalence class they’re in, and now also knows what color B’s hat was. So they can do the exact same reasoning to figure out their hat color! And so on, saving every last countable prisoner besides A..
Let’s see an example of this, for the sequence 100000…
And so on forever, until every last prisoner besides A is free.
This set of results is collectively the most compelling argument I know for rejecting AC, and I love it.
Last time we saw that no first-order theory could successfully pin down the natural numbers as a unique model. We also saw that in fact no sound and complete theory with the property of finite provability could pick out ℕ; any such theory has a Compactness Theorem, from which you can prove the existence of nonstandard models of numbers that include infinities of numbers larger than any of the naturals.
Worse, we saw that due to the Löwenheim-Skolem theorem, any first-order theory of the naturals has uncountable models, as well as models of every infinite cardinality. What followed from this was that try as we might, any first-order theory will fail to prove elementary facts about the natural numbers, like that there are a countable infinity of them or that no number is larger than 0, 1, 2, 3, and all the rest of the standard naturals.
Now, with the limitations in our ability to prove all true facts about the natural numbers firmly established, I want to talk about a theorem that seems to be in contradiction with this. This is the Completeness Theorem, proven by the same Kurt Gödel who later discovered the Incompleteness Theorems.
In a few words, the Completeness Theorem says that in any first-order theory, that which is semantically entailed is also syntactically entailed. Or, said differently, the Completeness Theorem says that a first order theory can prove everything that is true in all its models.
This sounds great! It’s the dream of mathematicians to be able to construct a framework in which all truths are provable, and Gödel appears to be telling us that first order logic is just such a framework.
But hold on, how do we reconcile this with what we just said: that there are true facts about the natural numbers that can’t be proven? And how do we reconcile this with what Gödel later proved: the Incompleteness Theorems? The First Incompleteness Theorem shows that that in any axiomatic system of mathematics, there will be true statements about arithmetic that cannot be proven within the system. These seem to be in stark contradiction, right? So which is right; Completeness or Incompleteness? Can we prove everything in first-order logic or not?
It turns out that there is no contradiction here. The Completeness Theorem is true of first order logic, as is the Incompleteness Theorem. What’s required is a subtle understanding of exactly what each theorem is saying to understand why the apparent conflict is only apparent.
There are two senses of completeness. One sense of completeness refers to theories in a particular logic. In this sense, a theory is complete if it can prove the truth or falsity of every well-formed formula. Gödel’s Incompleteness Theorems are about this sense of completeness: no theory rich enough to talk about the natural numbers can prove all statements about the natural numbers.
The second sense of completeness refers to logical frameworks themselves. A logical framework is complete if for every theory in that logic, all the semantically valid statements can be proven. Gödel’s Completeness Theorem is about this sense of completeness. In first-order logic, any theory’s semantic consequences are syntactic consequences.
Let’s go a little deeper into this.
What Gödel showed in his First Incompleteness Theorem is that one can encode the statements of any logical theory (first order or second order) as natural numbers. Then, if your theory is expressive enough to talk about the natural numbers, you produce a type of circularity: Your theory makes statements about the natural numbers, and the natural numbers encode statements from the theory. Gödel exploited this circularity to produce a sentence whose interpretation is something like “This sentence has no proof in T” (where T is your chosen theory). This sentence corresponds to some complicated fact about the properties of the natural numbers, because all sentences are encoded as natural numbers. If it’s false, then that means that the sentence does have a proof, so it’s true. And if it’s true, then it has no proof. The conclusion is that for any theory T, there are true statements about the natural numbers that cannot be proven by T.
The Incompleteness Theorem plays out slightly differently in first and second order logic. In first-order logic, anything that’s true in all models is provable. It’s just that there is no theory that has the natural numbers as a unique model. The best you can do in first-order logic is develop a theory that has the natural numbers as one out of many models. But this means that there is no first-order theory whose semantic consequences are all the truths about the natural numbers! (This is a neat way to actually prove the inevitability of nonstandard models of arithmetic, as a necessary consequence of the combination of the Completeness and Incompleteness theorems.)
And as it happens, any theory that has a model of the natural numbers is also going to have models in which Gödel’s statement is actually false! Remember that Gödel’s statement, if false, says that it is provable, which is to say that some number encodes a proof of it. In nonstandard models of arithmetic, there will be nonstandard numbers that encode a “proof” of Gödel’s statement, using Gödel’s encoding. It’s just that these “proofs” are not actually going to be things that we recognize as valid (for example, nonstandard numbers can represent infinitely long proofs). They’re proofs according to Gödel’s encoding, but Gödel’s encoding only represents valid proofs insofar as we assume that only natural numbers are being used in the encoding. So since Gödel’s statement is not true in all models of any first-order theory of arithmetic, it’s not provable from the axioms of the theory. And this is totally consistent with any first-order theory being complete! All that completeness means is that anything that is true in all models of a theory is also provable!
Now, how does this play out in second-order logic? Well, in second-order logic, you can uniquely pin down the natural numbers with a second-order theory. This is where the Incompleteness Theorem swoops in and tells you that the semantic consequences are not all syntactic consequences. Since there are second-order theories whose semantic consequences are all the truths about the natural numbers, these theories must have as semantic consequences the truth of the Gödel statement, which by construction means that they cannot have the Gödel statement as a syntactic consequence.
So either way you go, first or second order, you’re kinda screwed. In first-order, you can prove all the semantic consequences of a theory. It’s just that no theory has the full set of semantic consequences that we want, because first-order logic doesn’t have the expressive power to pin down the types of mathematical structures that we are interested in. And in second-order theories, you do have the expressive power to pin down the types of mathematical structures we care about, but as a consequence lose the property that all semantic consequences can be proved.
Regardless, there are fundamental limitations in our ability to prove all the facts that we want to prove as mathematicians. Hilbert’s program has crumbled. You can choose a theory that guarantees you the ability to prove all its semantic consequences, but lacks the expressive power to uniquely pin down the natural numbers. Or you can choose a theory that has the expressive power to uniquely pin down the natural numbers, but guarantees you the inability to prove all its semantic consequences.
Previously, we talked about the distinction between a logic, a language, a theory, and a model, and introduced propositional and first order logic. We toyed around with some simple first-order models, and began to bump our heads against the expressive limitations of the language of first order logic. Now it’s time to apply what we’ve learned to some REAL math! Let’s try to construct a first order theory of the natural numbers. N = {0, 1, 2, 3, …}
The first question we have to ask ourselves is what our language should be. What constants, predicates, and functions do we want to import into first order logic? There are many ways you could go here, but one historically popular approach is the following:
Constants: 0 Functions: S, +, × Predicates: ≥
We add just one constant, 0, three functions (a successor function to get the rest of the numbers from 0, as well as addition and multiplication), and one predicate for ordering the numbers. Let’s actually make this a little simpler, and talk about a more minimal language for talking about numbers:
Constants: 0
Functions: S
Predicates: None
This will be a good starting point, and from here we can easily define +, ×, and ≥ if necessary later on. Now, take a look at the following two axioms:
∀x (Sx ≠ 0)
∀x∀y (x ≠ y → Sx ≠ Sy)
In plain English, axiom 1 says that 0 is not the successor of any number. And axiom 2 says that two different numbers can’t have the same successor.
Visually, the first axiom tells us that this situation can’t happen:
And the second axiom tells us that this situation can’t happen:
Now, we know that 0 is a number, because it’s a constant in our language.
By axiom 1, we know that S0 cannot be 0. So it’s something new.
S0 cannot go to 0, because of axiom 1. And it can’t go to itself, as that would be a violation of axiom 2. So it has to go to something new:
Now, where does SS0 get sent? Not to 0, for the same reason as before. And not to either S0 or SS0, because then we’d have a violation of axiom 2. So it must go to a new number. You can see where this is going.
These two axioms really cleverly force us to admit an infinite chain of unique new numbers. So is that it? Have we uniquely pinned down the natural numbers?
It turns out that the answer is no. Consider the following model:
This is perfectly consistent with our axioms! No number goes to 0 via the successor function, and no two different numbers have the same successor. But clearly this is not a model of the natural numbers. One quick and easy patch on this is just to add a new axiom, banning any numbers that are their own successor.
3. ∀x (Sx ≠ x)
Now, we’ve taken care of this problem, but it’s a symptom of a larger issue. Here’s a model that’s perfectly consistent with our new axioms:
In the same vein as before, we can patch this with a new axiom, call it 3’:
3’. ∀x (SSx ≠ x)
But now we have the problem of three-loops, which require their own axiom to be ruled out (3’’. ∀x (SSSx ≠ x)). And in general, this approach will end up requiring us to have an infinite axiom schema, one axiom for each loop length that we need to ban.
However, even then we’re not done! Why? Well, once we’ve banned all loops, we run into the following problem:
We can fix this by specifying that 0 is the only number that is not the successor of any number. Formally, this looks like:
∀x (∀y (Sy ≠ x) → x = 0)
Okay, so that takes care of other copies of the natural numbers. But we’re still not done! Take a look at the following model:
This model violates none of our axioms, but is clearly not the natural numbers. We’re running into a lot of problems here, and our list of axioms is getting really long and unwieldy. Is there any simpler system of axioms that will uniquely pin down the natural numbers for us?
The amazing fact is that no, this is not possible. In fact, no matter how hard you try, you will never be able to rule out models of your axioms that contain “nonstandard numbers” in first-order logic.
We’ll prove this using a beautiful line of reasoning, which I think of as one of the simplest and most profound arguments I’ve encountered. There’s several subtle steps here, so read carefully:
Step 1
We’re going to start out by proving a hugely important theorem called the Compactness Theorem.
Suppose that a first order theory T has no model.
Then there is no consistent assignment of truth values to all WFFs.
So you can prove a contradiction from T. (follows from completeness)
All proofs must be finite, so if you can prove a contradiction from T, you can do it in a finite number of steps.
If the proof of contradiction takes a finite number of steps, then it uses only a finite number of T’s axioms.
So there is a proof of contradiction from a finite subset of T’s axioms.
So there’s a finite subset of T’s axioms that has no model. (follows from soundness)
So if T has no model, then there’s a finite subset of T’s axioms that has no model.
The Compactness Theorem as it’s usually stated is the contrapositive of this: If all finite subsets of T’s axioms have a model, then T has a model. If you stop to think about this for a minute, it should seem pretty surprising to you. (It’s trivial for the case that T contains a finite number of axioms, of course, but not if T has an infinity of axioms.)
Also notice that our proof of the theorem barely relied on what we’ve said about the properties of first order logic at all! In fact, it turns out that there is a Compactness Theorem in any logic that is sound (syntactic entailment implies semantic entailment, or in other words: that which is provable is true in all models), complete (semantic entailment implies syntactic entailment, or: that which is true in all models is provable), and only allows finite proofs.
In other words, any logic in which the provable statements are exactly those statements that are true in all models, no more and no less, and in which infinite proofs are considered invalid, will have this peculiar property.
Step 2
Now, we use the Compactness Theorem to prove our desired result.
Suppose we have a first order theory T that has the natural numbers N as a model.
We create a new theory T’ by adding a constant symbol ω and adjoining an infinite axiom schema:
‘ω ≥ 0’
‘ω ≥ S0’
‘ω ≥ SS0’
‘ω ≥ SSS0’ (And so on…)
N is no longer a model of T’, because T’ says that there is a number that’s larger than every natural number, which is false in N.
But T’ still has a model, because of compactness:
Any finite subset of the axioms of T’ has a finite number of statements that look like ‘ω > x’. But this is consistent with ω being a natural number! (because for any set of natural numbers you can find a larger natural number)
So N is a model of any finite subset of the axioms of T’.
So by compactness, T’ has a model. This model is nonstandard (because earlier we saw that it’s not N).
Furthermore, any model of T’ is a model of T, because T’ is just T + some constraints.
So since T’ has a nonstandard model, so does T.
Done!
The conclusion is the following: Any attempt to model N with a first order theory is also going to produce perverse nonstandard models in which there are numbers larger than any natural number.
Furthermore, this implies that no first order theory of arithmetic can prove that there is no number larger than every natural number. If we could, then we would be able to rule out nonstandard models. But we just saw that we can’t! And in fact, we can realize that ω, as a number, must have a successor, which can’t be itself, and which will also have a successor, and so on forever, so that we will actually end up with an infinityofinfinitely-large numbers, none of which we have any power to deny the existence of.
But wait, it gets worse! Compactness followed from just three super elementary desirable features of our logic: soundness, completeness, and finite provability. So this tells us that our inability to uniquely pin down the natural numbers is not just a problem with first order logic, it’s basically a problem with any form of logic that does what we want it to do.
Want to talk about the natural numbers in a Hilbertian logical framework, where anything that’s true is provable and anything that’s provable is true? You simply cannot. Anything you say about them has to be consistent with an interpretation of your statements in which you’re talking about a universe with an infinity of infinitely large numbers.
Löwenheim-Skolem Theorem
Just in case your mind isn’t sufficiently blown by the Compactness Theorem and its implications, here’s a little bit more weirdness.
The Löwenheim-Skolem Theorem says the following: If a first-order theory has at least one model of any infinite cardinality, then it has at least one model of EVERY infinite cardinality.
Here’s an intuition for why this is true: Take any first order theory T. Construct a new theory T’ from it by adding κ many new constant symbols to its language, for any infinite cardinality κ of your choice. Add as axioms c ≠ c’, for any two distinct new constant symbols. The consistency of the resulting theory follows from the Compactness Theorem, and since we got T’ by adding constraints to T, any model of T’ must be a model of T as well. So T has models of any infinite cardinality!
The Löwenheim-Skolem Theorem tells us that any first order theory with the natural numbers as a model also has models the size of the real numbers, as well as models the size of the power set of the reals, and the power set of the power set of the reals, and so on forever. Not only can’t we pin down the natural numbers, we can’t even pin down their cardinality!
And in fact, we see from this that no first-order statement can express the property of “being a specific infinite cardinality.” If we could do this, then we could just add this statement to a theory as an axiom and rule out all but one infinite cardinality.
Here’s one more for you: The Löwenhiem-Skolem Theorem tells us that any attempt to talk about the real numbers in first order logic will inevitably have an interpretation that refers solely to a set that contains a countable infinity of objects. This implies that in first order logic, almost all real numbers cannot be referred to!
Similarly, a first order set theory must have countable models. But keep in mind that Cantor showed how we can prove the existence of uncountably infinite sets from the existence of countably infinite sets! (Namely, just take a set that’s countably large, and power-set it.) So apparently, any first order set theory has countable models that… talk about uncountable infinities of sets? This apparent contradiction is known as Skolem’s paradox, and resolving it leads us into a whole new set of strange results for how to understand the expressive limitations of first order logic in the context of set theory.
Mathematical logic is the study of the type of reasoning we perform when we do mathematics, and the attempt to formulate a general language as the setting in which all mathematics is done. In essence, it is an attempt to form a branch of mathematics, of which all other branches of mathematics will emerge as special cases.
You might sort of think that when speaking at this level of abstraction, there will nothing general and interesting to say. After all, we’re trying to prove statements not within a particular domain of mathematics, but theorems that are true across a wide swath of mathematics, potentially encompassing all of it.
The surprising and amazing thing is that this is not the case. It turns out that there are VERY general and VERY surprising things you can discover by looking at the logical language of mathematics, a host of results going by names like the Completeness Theorem, the Incompleteness Theorem, the Compactness Theorem, the Löwenheim-Skolem Theorem, and so on. These results inevitably have a great deal of import to our attitudes towards the foundations of mathematics, being that they generally establish limitations or demonstrate eccentricities in the types of things that we can say in the language of mathematics.
My goal in this post is to provide a soft introduction to the art of dealing in mathematics at this level of ultimate abstraction, and then to present some of the most strange things that we know to be true. I think that this is a subject that’s sorely missing this type of soft introduction, and hope I can convey some of the subject’s awesomeness!
— — —
To start out with, why think that there is any subject matter to be explored here? Different branches of mathematics sometimes appear to be studying completely different types of structures. I remember an anecdote from an old math professor of mine, who worked within one very narrow and precisely defined area of number theory, and who told me that when she goes to talks that step even slightly outside her area of specialty, the content of the lectures quickly incomprehensible to her. Why think that there is such a common language of mathematics, if specialists in mathematics can’t even understand each other when talking between fields?
The key thing to notice here is that although different fields of mathematics are certainly wildly different in many ways, there nevertheless remain certain fundamental features that are shared in all fields. Group theorists, geometrists, and number theorists will all accept the logical inference rule of modus ponens (if P is true and P implies Q, then Q is true), but none of them will accept its converse (if Q is true and P implies Q, then P is true). No matter what area of mathematics you study, you will accept that if P(x) is true for all x, then it is true for any particular x you choose. And so on. These similarities may seem obvious and trivial, but they HAVE to be obvious and trivial to be things that every mathematician agrees on. The goal, then, is to formalize a language that has these fundamental inference rules and concepts built in, and that has many special cases to account for the differences between domains of math, specified by some parameters that are freely chosen by any user of the system.
There are actually several distinct systems that attempt to accomplish this task. Generally speaking, there are three main branches, in order of increasing expressive power: propositional logic, first order (predicate) logic, and second order logic.
Reasoning In Zeroth Order
Let’s start with propositional logic, sometimes called “zeroth order logic.” Propositional logic is the framework developed to deal with the validity of the following types of arguments:
Argument 1
2+2=4.
If 2+2=4, then 1+3=4.
So 1+3=4.
Argument 2
The Riemann hypothesis is false and P = NP.
So P = NP.
Notice that it doesn’t matter if our premises are true or not. Logical validity doesn’t care about this, it just cares that the conclusions really do follow from the premises. This is a sign of the great generality at which we’re speaking. We’re perfectly fine with talking about a mathematical system in which the Riemann hypothesis is false, or in which 2+2 is not 4, just so long as we accept the logical implications of our assumptions.
Propositional logic can express the validity of these arguments by formalizing rules about valid uses of the concepts ‘and’, ‘if…then…’, ‘or’, and so on. It remains agnostic to the subject matter being discussed by not fully specifying the types of sentences that are allowed to be used in the language. Instead, any particular user of the language can choose their set of propositions that they want to speak about.
To flesh this out more, propositional logic fulfills the following three roles:
Defines an alphabet of symbols.
Specifies a set of rules for which strings are grammatical and which are not.
Details rules for how to infer new strings from existing strings.
In more detail:
The set of symbols in propositional logic are split into two categories: logical symbols and what I’ll call “fill-in-the-blank” symbols. The logical symbols are (, ), ∧, ∨, ¬, and →. The fill-in-the-blank symbols represent specific propositions, that are specified by any particular user of the logic.
Some strings are sensible and others not. For example, the string “P∧∧” will be considered to be nonsensical, while “P∧Q” will not. Some synonyms for sensible strings are well-formed formulas (WFFs), grammatical sentences, and truth-apt sentences. There is a nice way to inductively generate the set of all WFFs: Any proposition is a WFF, and for any two WFFs F and F’, the following are also WFFs: (F∧F’), (F∨F’), ¬F, (F→F’).
These include rules like modus ponens (from P and P→Q, derive Q), conjunction elimination (from P∧Q, derive P), double negation elimination (from ¬¬P, derive P), and several more. They are mechanical rules that tell you how to start with one set of strings and generate new ones in a logically valid way, such that if the starting strings are true than the derived ones must also be true. There are severaldifferentbutequivalent formulations of the rules of inference in propositional logic.
A propositionallanguage fills in the blanks in the logic. Say that I want to talk about two sentences using propositional logic: “The alarm is going off”, “A robber has broken in.” For conciseness, we’ll abbreviate these two propositions as A for alarm and R for robber. All I’ll do to specify my language is to say “I have two propositions: {A, R}”
The next step is to fill in some of the details about the relationships between the propositions in my language. This is done by supplementing the language with a set of axioms, and we call the resulting constrained structure a propositional theory. For instance, in my example above we might add the following axioms:
A→R
A∨R
In plain English, these axioms tell us that (1) if the alarm is going off, then a robber has broken in, and (2) an alarm is going off or a robber has broken in.
Finally, we talk about the models of our theory. Notice that up until now, we haven’t talked at all about whether any statements are true or false, just about syntactic properties like “The string P∨¬ is not grammatical” and about what strings follow from each other. Now we interpret our theory by seeing what possible assignments of truth values to the WFFs in our language are consistent with our axioms and logical inference rules. In our above example, there are exactly two interpretations:
Model 1: A is true, R is true
Model 2: A is false, R is true
These models can be thought of as the possible worlds that are consistent with our axioms. In one of them, the alarm has gone off and a robber has broken in, and in the other, the alarm hasn’t gone off and the robber has broken in.
Notice that R turns out true in both models. When a formula F is true in all models of a theory, we say that the theory semantically entails F, and write this as T ⊨ F. When a formula can be proven from the axiomsof the theory using the rules of inference given by the logic, then we say that the theory syntactically entails F, and write this as T ⊢ F.
This distinction between syntax and semantics is really important, and will come back to us in later discussion of several important theorems (notably the completeness and incompleteness theorems). To give a sneak peek: above we found that R was semantically entailed by our theory. If you’re a little familiar with propositional logic, you might have also realized that R can be proven from the axioms. In general, syntactic truths will always be semantic truths (if you can prove something, then it must be true in all models, or else the models would be inconsistent. But a model is by definition a consistent assignment of truth values to all WFFs). But a natural question is: are all semantic consequences of a theory also syntactic consequences? That is, are all universal truths of the theory (things that are true in every model of the theory) provable from the theory?
If the answer is yes, then we say that our logic is complete. And it turns out that the answer is yes, for propositional logic. Whether more complex logics are complete turns out to be a more interesting question. More on this later.
This four-step process I just laid out (logic to language to theory to model) is a general pattern we’ll see over and over again. In general, we have the following division of labor between the four concepts:
Logic: The logic tells us the symbols we may use (including some fill-in-the-blank categories of symbols), the rules of grammar, and a set of inference rules for deriving new strings from an existing set.
Language: The language fills in the blanks in our logic, fully specifying the set of symbols we will be using.
Theory: The theory adds axioms to the language.
Model: A model is an assignment of truth values to all WFFs in the language, consistent with the axioms and the inference rules of our logic.
It’s about time that we apply this four-step division to a more powerful logic. Propositional logic is pretty weak. Not much interesting math can be done in a purely propositional language, and it’s wildly insufficient to capture our notion of logically valid reasoning. Consider, for example, the following argument:
Socrates is a man.
All men are mortal.
So, Socrates is mortal.
This is definitely a valid argument. No rational agent could agree that 1 and 2 are true, and yet deny the truth of 3. But can we represent the validity of this argument in propositional logic? No!
Consider that the three sentences “Socrates is a man”, “All men are mortal”, and “Socrates is mortal” are distinct propositions, and the relationships between them are too subtle for propositional logic to capture. Propositional logic can’t see that the first proposition is asserting the membership of Socrates to a general class of things (“men”), and that the second proposition is then making a statement about a universal property of things in this class. It just sees two distinct propositions. To propositional logic, this argument just looks like
P
Q
Therefore, R
But this is not logically valid! We could make it valid by adding as a premise the sentence (P∧Q)→R, which corresponds to the English sentence “If Socrates is a man and all men are mortal, then Socrates is mortal.” But this should be seen as a tautology, something that is provable in any first order theory that contains the propositions P Q and R, not a required additional assumption. Worse, if somebody came along and stated the proposition A = “Aristotle is a man”, then we would need a whole ‘nother assumption to assert that Aristotle is also mortal! And in general, for any individual instance of this argument, we’d need an independent explanation for its validity. This is not parsimonious, and indicative that propositional logic is missing something big.
Missing what? To understand why this argument is valid, you must be able to reason about objects, properties, and quantification. This is why we must move on to an enormously more powerful and interesting logic: first order logic.
Reasoning In First Order
First order logic is a logic, so it must fill the same three roles as we saw propositional logic did above. Namely, it must define the alphabet, the grammar, and the inference rules.
Symbols Logical: ∧∨ ¬ → ( ) ∀∃ =
Variables: x y z w …
Constants: ______
Predicates: ______
Functions: ______
That’s right, in first order we have three distinct categories of fill-in-the-blank symbols. Intuitively, constants will be names that refer to objects, predicates will be functions from objects to truth values, and functions will take objects to objects. To take an everyday example, if the objects in consideration are people, then we might take ‘a’ to be a constant referring to a person named Alex, ’T’ to be a predicate representing ‘is tall’, and ‘f’ to be a function representing “the father of”. So T(a) is either true or false, while f(a) doesn’t have a truth value (it just refers to another object). But T(f(a)) does have a truth value, because it represents the sentence “Alex’s father is tall.”
Next, we define well-formed formulas. This process is more complicated than it was for propositional logic, because we have more types of things than we did before, but it’s not too bad. We start by defining a “term”. The set of terms is inductively generated by the following scheme: All constants and variables are terms, and any function of terms is itself a term. Intuitively, the set of terms is the set of objects that our language is able to “point at”.
With the concept of terms in hand, we can define WFFs through a similar inductive scheme: Any predicate of terms is a WFF. And for any WFFs F and F’, (F∧F’), (F∨F’), (¬F), (F→F’), ∀x F, ∃x F are all WFFs. The details of this construction are not actually that important, I just think it’s nice how you can generate all valid first order formulas from fairly simple rules.
Good! We have an alphabet, a grammar, and now all we need from our logic is a set of inference rules. It turns out that this set is just going to be the inference rules from propositional logic, plus some new ones:
Quantifier elimination: From ∀x P(x) derive P(t) (for any term t and predicate P) Quantifier introduction: From P(t) derive ∃x P(x) (for any term t and predicate P)
That’s it, we’ve defined first order logic! Now let’s talk about a first order language. Just like before, the language is just obtained by filling in the blanks left open by our logic. So for instance, we might choose the following language:
Constants: a
Functions: f
Predicates: none
In specifying our function, we have to say exactly what type of function it is. Functions can take as inputs a single object (“the father of”) or multiple objects (“the nearest common ancestor of”), and this will make a difference to how they are treated. So for simplicity, let’s say that our function f just takes in a single object.
A first order theory will simply be a language equipped with some set of axioms. Using our language above, we might have as axioms:
∀x (f(x) ≠ x)
∀x (f(x) ≠ a)
In plain English, we’re saying that f never takes any object to itself or to a.
And lastly, we get to the models of a first order theory. There’s an interesting difference between models here and models in propositional logic, which is that to specify a first order model, you need to first decide on the size of your set of objects (the size of the ‘universe’, as it’s usually called), and then find a consistent assignment of truth values to all propositions about objects in this universe.
So, for instance, we can start searching for models of our theory above by starting with models with one object, then two objects, then three, and so on. We’ll draw little diagrams below in which points represent objects, and the arrow represents the action of the function f on an object.
No 1-element universe.
No 2-element universe.
3-element universe
4 element universes
And so on…
It’s a fun little exercise to go through these cases and see if you can figure out why there are no models of size 1 or 2, or why the one above is the only model of size 3. Notice, by the way, that in the last two images, we have an object for which there is no explicit term! We can’t get there just using our constant and our functions. Of course, in this case we can still be clever with our quantifiers to talk about the Nameless One indirectly (for instance, in both of these models we can refer to the object that is not equal to a, f(a), or f(f(a))) But in general, the set of all things in the universe is not going to be the same as the set of things in the universe that we can name.
Here’s a puzzle for you: Can you make a first order sentence that says “I have exactly four objects”? That is, can you craft a sentence that, if added as an axiom to our theory, will rule out all models besides the ones that have exactly four elements?
(…)
(Think about it for a moment before moving on…)
(…)
Here’s how to do it for a universe with two objects (as well as a few other statements of interest). The case of four objects follows pretty quickly from this.
“I have at most two objects” = ∃x∃y∀z (z=x ∨ z=y)
“I have exactly two objects” = ∃x∃y (x≠y ∧∀z(z=x ∨ z=y))
“I have at least two objects” = ∃x∃y (x≠y)
Another puzzle: How would you say “I have an infinity of objects”, ruling out all finite models?
(…)
(Think about it for a moment before moving on…)
(…)
This one is trickier. One way to do it is to introduce an infinite axiom schema: “I have at least n objects” for each n.
This brings up an interesting point: theories with infinite axioms are perfectly permissible for us. This is a choice that we make that we could perfectly well deny, and end up with a different and weaker system of logic. How about infinitely long sentences? Are those allowed? No, not in any of the logics we’re talking about here. A logic in which infinite sentences are allowed is called an infinitary logic, and I don’t know too much about such systems (besides that propositional, first, and second order logics are not infinitary).
Okay… so how about infinitely long derivations? Are those allowed? No, we won’t allow those either. This one is more easy to justify, because if infinite derivations were allowed, then we could prove any statement P simply by the following argument “P, because P, because P, because P, because …”. Each step logically follows from the previous, and in any finite system we’d eventually bottom out and realize that the proof has no basis, but in a naive infinite-proof system, we couldn’t see this.
Alright, one last puzzle. How would you form the sentence “I have a finite number of objects”? I.e., suppose you want to rule out all infinite models but keep the finite ones. How can you do it?
(…)
(Think about it for a moment before moving on…)
(…)
This one is especially tricky, because it turns out to be impossible! (Sorry about that.) You can prove, and we will prove in a little bit, that no first order axiom (or even infinite axiom schema) is in general capable of restricting us to finite models. We have run up against our first interesting expressive limitation of first-order logic!
Okay, let’s now revisit the question of completeness that I brought up earlier. Remember, a logic is complete if for any theory in that logic, the theory’s semantic implications are the same as its syntactic implications (all necessary truths are provable). Do you think that first order logic is complete?
The answer: Yes! Kurt Gödel proved that it is in his 1929 doctoral dissertation. Anything that is true in all models of a first order theory, can be proven from the axioms of that theory (and vice versa). This is a really nice feature to have in a logic. It’s exactly the type of thing that David Hilbert was hoping would be true of mathematics in general. (“We must know. We will know!”) But this hope was dashed by the same Kurt Gödel as above, in his infamous incompleteness theorems.
There will be a lot more to say about that in the future, but I’ll stop this post for now. Next time, we’ll harness the power of first order logic to create a first order model of number theory! This will give us a chance to apply some powerful results in mathematical logic, and to discover surprising truths about the logic’s limitations.