You have lots of beliefs about the world. Each belief can be written as a propositional statement that is either true or false. But while each statement is either true or false, your beliefs are more complicated; they come in shades of gray, not blacks and whites. Instead of beliefs being on-or-off, we have degrees of beliefs – some beliefs are much stronger than others, some have roughly the same degree of belief, and so on. Your smallest degrees of belief are for true impossibilities – things that you can be absolutely certain are false. Your largest degrees of beliefs are for absolute certainties, the other side of the coin.
Now, answer for yourself the following series of questions:
- Can you quantify a degree of belief?
By quantify, I mean put a precise, numerical value on it. That is, can you in principle take any belief of yours, and map it to a real number that represents how strongly you believe it? The in principle is doing a lot of work here; maybe you don’t think that you can in practice do this, but does it make conceptual sense to you to think about degrees of belief as quantities?
If so, then we can arbitrarily scale your degrees of belief by translating them into what I’ll call for the moment credences. All of your credences are on a scale from 0 to 1, where 0 is total disbelief and 1 is totally certain belief. We can accomplish this rescaling by just shifting all your degrees of belief up by your lowest degree of belief (that which you assign to logical impossibilities), and then dividing each degree of belief by the difference between your most distant degrees of belief.
Now,
- If beliefs B and B’ are mutually exclusive (i.e. it is impossible for them both to be true), then do you agree that your credence in one of the two of them being true should be the sum of your credences in each individually?
Said more formally, do you agree that if Cr(B & B’) = 0, then Cr(B or B’) = Cr(B) + Cr(B’)? (The equal sign here should be a normative equals sign. We are not asking if you think this is descriptively true of your degrees of beliefs, but if you think that this should be true of your degrees of beliefs. This is the normativity of rationality, by the way, not ethics.)
If so, then your credence function Cr is really a probability function (Cr(B) = P(B)). With just these two questions and the accompanying comments, we’ve pinned down the Kolmogorov axioms for a simple probability space. But we’re not done!
Next,
- Do you agree that your credence in two statements B and B’ both being true should be your credence in B’ given that B is true, multiplied by your credence in B?
Formally: Do you agree that P(B & B’) = P (B’ | B) ∙ P(B)? If you haven’t seen this before, this might not seem immediately intuitively obvious. It can be made so quite easily. To find out how strongly you believe both B and B’, you can firstly imagine a world in which B is true and judge your credence in B’ in this scenario, and then secondly judge your actual credence in B being the real world. The conditional probability is important here in order to make sure you are not ignoring possible ways that B and B’ could depend upon each other. If you want to know the chance that both of somebody’s eyes are brown, you need to know (1) how likely it is that their left eye is brown, and (2) how likely it is that their right eye is brown, given that their left eye is brown. Clearly, if we used an unconditional probability for (2), we would end up ignoring the dependency between the colors of the right and left eye.
Still on board? Good! Number 3 is crucially important. You see, the world is constantly offering you up information, and your beliefs are (and should be) constantly shifting in response. We now have an easy way to incorporate these dynamics.
Say that you have some initial credence in a belief B about whether you will experience E in the next few moments. Now you see that after a few moments pass, you did experience E. That is, you discover that B is true. We can now set P(B) equal to 1, and adjust everything else accordingly:
For all beliefs B’, Pnew(B’) = P(B’ | B)
In other words, your new credences are just your old credences given the evidence you received. What if you weren’t totally sure that B is true? Maybe you want P(B) = .99 instead. Easy:
For all beliefs B’: Pnew(B’) = .99 ∙ P(B’ | B) + .01 ∙ P(B’ | ~B)
In other words, your new credence in B’ is just your credence that B is true, multiplied by the conditional credence of B’ given that B is true, added to your credence that B is false times the conditional credence of B’ given that B is false.
We now have a fully specified general system of updating beliefs; that is, we have a mandated set of degrees of beliefs at any moment after some starting point. But what of this starting point? Is there a rationally mandated prior credence to have, before you’ve received any evidence at all? I.e., do we have some a priori favored set of prior degrees of belief?
Intuitively, yes. Some starting points are obviously less rational than others. If somebody starts off being totally certain in the truth of one side of an a posteriori contingent debate that cannot be settled as a matter of logical truth, before receiving any evidence for this side, then they are being irrational. So how best to capture this notion of normative rational priors? This is the question of objective Bayesianism, and there are several candidates for answers.
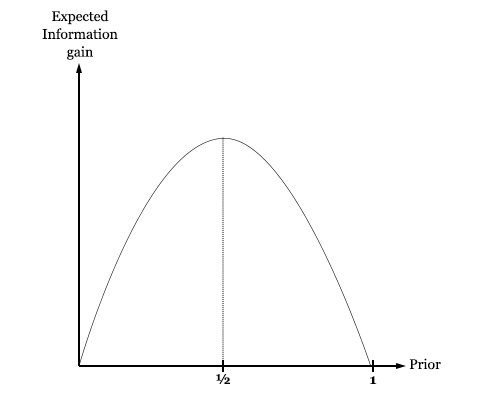
One candidate relies on the notions of surprise and information. Since we start with no information at all, we should start with priors that represent this state of knowledge. That is, we want priors that represent maximum uncertainty. Formalizing this notion gives us the principle of maximum entropy, which says that the proper starting point for beliefs is that which maximizes the entropy function ∑ -P logP.
There are problems with this principle, however, and many complicated debates comparing it to other intuitively plausible principles. The question of objective Bayesianism is far from straightforward.
Putting aside the question of priors, we have a formalized system of rules that mandates the precise way that we should update our beliefs from moment to moment. Some of the mandates seem unintuitive. For instance, it tells us that if we get a positive result on a 99% accurate test for a disease with a 1% prevalence rate, then we have a 50% chance of having the disease, not 99%. There are many known cases where our intuitive judgments of likelihood differ from the judgments that probability theory tells us are rational.
How do we respond to these cases? We only really have a few options. One, we could discard our formalization in favor of the intuitions. Two, we could discard our intuitions in favor of the formalization. Or three, we could accept both, and be fine with some inconsistency in our lives. Presuming that inconsistency is irrational, we have to make a judgment call between our intuitions and our formalization. Which do we discard?
Remember, our formalization is really just the necessary result of the set of intuitive principles we started with. So at the core of it, we’re really just comparing intuitions of differing strengths. If your intuitive agreement with the starting principles was stronger than your intuitive disagreement with the results of the formalization, then presumably you should stick with the formalization.
Another path to adjudicating these cases is to consider pragmatic arguments for our formalization, like Dutch Book arguments that indicate that our way of assigning degrees of beliefs is the only one that is not exploitable by a bookie to ensure losses. You can also be reassured by looking at consistency and convergence theorems, that show the Bayesian’s beliefs converging to the truth in a wide variety of cases.
If you’re still with me, you are now a Bayesian. What does this mean? It means that you think that it is rational to treat your beliefs like probabilities, and that you should update your beliefs by conditioning upon the evidence you receive.
***
So what’s next? Are we done? Have all epistemological issues been solved? Unfortunately not. I think of Bayesianism as a first step into the realm of formal epistemology – a very good first step, but nonetheless still a first. Here’s a simple example of where Bayesianism will lead us into apparent irrationality.
Imagine we have two different beliefs about the world: B1 and B2. B2 is a respectable scientific theory: one that puts its neck out with precise predictions about the results of experiments, and tries to identify a general pattern in the underlying phenomenon. B1 is a “cheating” theory: it doesn’t have any clue what’s going to happen before an experiment, but after an experiment it peeks at the results and pretends that it had predicted it all along. We might think of B1 as the theory that perfectly fits all of the data, but only through over-fitting on the data. As such, B1 is unable to make any good predictions about future data.
What does Bayesianism say about these two theories? Well, consider any single data point. Let’s suppose that B2 does a good job predicting this data point, say, P(D | B2) = 99%. And since B1 perfectly fits the data, P(D | B1) = 1. If our priors in B1 and B2 are written as P1 and P2, respectively, then our credences update as follows:
Pnew(B1) = P(B1 | D) = P1 / (P1 + .99 P2)
Pnew(B2) = P(B2 | D) = .99 P2 / (P1 + .99 P2)
For N similar data points, we get:
Pnew(B1) = P(B1 | Dn) = P1 / (P1 + .99n P2)
Pnew(B2) = P(B2 | Dn) = .99n P2 / (P1 + .99n P2)
What happens to these two credences as n gets larger and larger?
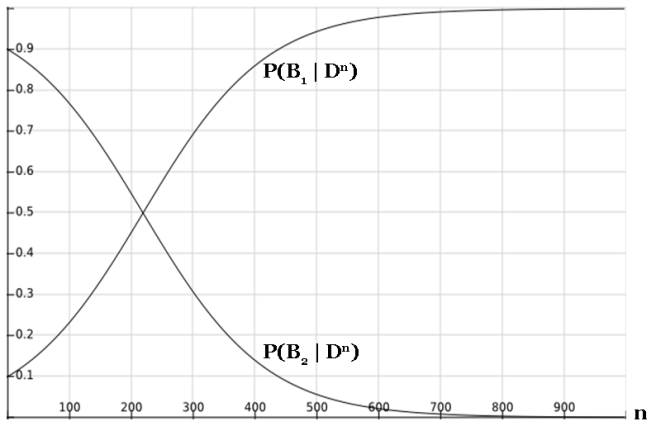
As we can see, our credence in B1 approaches 100% exponentially quickly, and our credence in B2 drops to 0% exponentially quickly. Even if we start with an enormously low prior in B1, our credence will eventually be swamped as we gather more and more data.
It looks like in this example, the Bayesian is successfully hoodwinked by the cheating theory, B1. But this is not quite the end of the story for Bayes. The only single theory that perfectly predicts all of the data you receive in the infinite evidence limit is basically just the theory that “Everything that’s going to happen is what’s going to happen.” And, well, this is surely true. It’s just not very useful.
If instead we look at B1 as a sequence of theories, one for each new data point, then we have a way out by claiming that our priors drop as we go further in the sequence. This is an appeal to simplicity – a theory that exactly specifies 1000 different data points is more complex than a theory that exactly specifies 100 different data points. It also suggests a precise way to formalize simplicity, by encoding it into our priors.
While the problem of over-fitting is not an open-and-shut case against Bayesianism, it should still give us pause. The core of the issue is that there are more intuitive epistemic virtues than those that the Bayesian optimizes for. Bayesianism mandates a degree of belief as a function of two ingredients: the prior and the evidential update. The second of these, Bayesian updating, solely optimizes for accommodation of data. And setting of priors is typically done to optimize for some notion of simplicity. Since empirically distinguishable theories have their priors washed out in the limit of infinite evidence, Bayesianism becomes a primarily accommodating epistemology.
This is what creates the potential for problems of overfitting to arise. The Bayesian is only optimizing for accommodation and simplicity, but what we want is a framework that also optimizes for prediction. I’ll give two examples of ways to do this: cross validation and posterior predictive checking.
I’ve talked about cross validation previously. The basic idea is that you split a set of data into a training set and a testing set, optimize your model for best fit with the training set, and then see how it performs on the testing set. In doing so, you are in essence estimating how well your model will do on predictions of future data points.
This procedure is pretty commonsensical. Want to know how well your model does at predicting data? Well, just look at the predictions it makes and evaluate how accurate they were. It is also completely outside of standard Bayesianism, and solves the issues of overfitting. And since the first half of cross validation is training your model to fit the training set, it is optimizing for both accommodation and prediction.
Posterior predictive checks are also pretty commonsensical; you ask your model to make predictions for future data, and then see how these predictions line up with the data you receive.
More formally, if you have some set of observable variables X and some other set of parameters A that are not directly observable, but that influence the observables, you can express your prior knowledge (before receiving data) as a prior over A, P(A), and a likelihood function P(X | A). Upon receiving some data D about the values of X, you can update your prior over A as follows:
P(A) becomes P(A | D)
where P(A | D) = P(D | A) P(A) / P(D)
To make a prediction about how likely you think it is that the next data point will be X, given the data D, you must use the posterior predictive distribution:
P(X | D) = ∫ P(X | A) ∙ P(A | D) dA
This gives you a precise probability that you can use to evaluate the predictive accuracy of your model.
There’s another goal that we can aim towards, besides accommodation, simplicity, or prediction. This is distance from truth. You might think that this is fairly obvious as a goal, and that all the other methods are really only attempts to measure this. But in information theory, there is a precise way in which you can specify the information gap between any given theory and reality. This metric is called the Kullback-Leibler divergence (DKL), and I’ll refer to it as just information divergence.
DKL = ∫ Ptrue log(Ptrue / P) dx
This term, if parsed correctly, represents precisely how much information you gain if you go from your starting distribution P to the true distribution Ptrue.
For example, if you have a fair coin, then the true distribution is given by (Ptrue(H) = .5, Ptrue(T) = .5). You can calculate how far any other theory (P(H) = p, P(T) = 1 – p) is from the truth using DKL.
DKL = .5 ∙ [ log(1 / 2p) + log(1 / 2(1-p)) ]
I’ve graphed DKL as a function of p here:
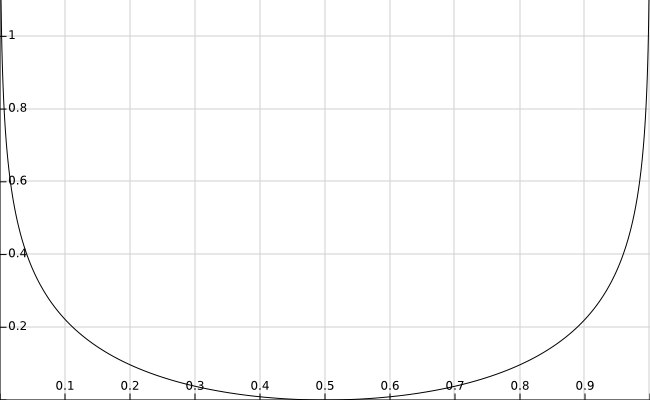
As you can see, the information divergence is 0 for the correct theory that the coin is fair (p = 0.5), and goes to infinity as you get further away from this.
This is all well and good, but how is this practically applicable? It’s easy to minimize the distance from the true distribution if you already know the true distribution, but the problem is exactly that we don’t know the truth and are trying to figure it out.
Since we don’t have direct access to Ptrue, we must resort to approximations of DKL. The most famous approximation is called the Akaike information criterion (AIC). I won’t derive the approximation here, but will present the form of this quantity.
AIC = k – log(P(data | M))
where M = the model being evaluated
and k = number of parameters in M
The model that minimizes this quantity probably also minimizes the information distance from truth. Thus, “lower AIC value” serves as a good approximation to “closer to the truth”. Notice that AIC explicitly takes into account simplicity; the quantity k tells you about how complex a model is. This is pretty interesting in it’s own right; it’s not obvious why a method that is solely focused on optimizing for truth will end up explicitly including a term that optimizes for simplicity.
Here’s a summary table describing the methods I’ve talked about here (as well as some others that I haven’t talked about), and what they’re optimizing for.
|
Goal |
Method(s) |
| Which theory makes the data most likely? |
Maximum likelihood estimation (MLE) |
|
Which theory is most likely, given the data? |
Bayes Bayesian information criterion (BIC) |
| Maximum uncertainty |
Entropy |
|
Simplicity |
Minimum description length Solomonoff induction |
|
Predictive accuracy |
Cross validation |
|
Distance from truth |
Information divergence (DKL) |