I devoured science fiction as a kid. One of my favorite books was Asimov’s Foundation, which told the story of a splintering Galactic Empire and the seeds of a new civilization that would grow from its ashes. I marveled and was filled with joy at the notion that in our far future humanity might spread across the galaxy, settling countless new planets and bringing civilization to every corner of it.
Then I went to college and learned physics, especially special relativity and cosmology, and learned that there are actually some hugely significant barriers in the way of these visions ever being manifest in reality. Ever since, it has seemed obvious to me that the idea of a galactic civilization, or of humans “colonizing the universe” are purely fantasy. But I am continuously surprised when I hear those interested in futurism throw around these terms casually, as if their occurrence were an inevitability so long as humans stay around long enough. This is deeply puzzling to me. Perhaps these people are just being loose with their language, and when they refer to a galactic civilization, they mean something much more modest, like a loosely-connected civilization spread across a few nearby stars. Or maybe there is a fundamental misunderstanding of both the limitations imposed on us by physics and the the enormity of the scales in question. Either way, I want to write a post explaining exactly why these science fiction ideas are almost certainly never going to become reality.
My argument in brief:
-
We are really slow.
-
The galaxy is really big.
-
The universe is even bigger.
Back in 1977, humans launched the Voyager 1 spacecraft, designed to explore the outer solar system and then to head for the stars. Its trajectory was coordinated to slingshot around Jupiter and then Saturn, picking up speed at each stage, and then finally to launch itself out of the solar system into the great beyond. 36 years later, in 2012, it has finally left the Sun’s heliopause, marking the first steps into interstellar space. It is now 11.7 billion miles from Earth, which sounds great until you realize that this distance is still less than two-tenths of a single percent of one light year.
Compare this to, say, the distance to the nearest star Alpha Centauri, we find that it has traveled less than .05% of the distance. At this rate, it would take another 80,000 years to make contact with Alpha Centauri (if it were aimed in that direction)! On the scale of distances between stars, our furthest current exploration has gotten virtually nowhere. It’s the equivalent of somebody who started in the center of the Earth hoping to burrow up all the way to the surface, and takes 5 days to travel a single meter. Over 42 years, they would have travelled just under 3000 meters.
OK, you say, but that’s unfair. The Voyager was designed in the 70s! Surely we could do better with modern space shuttle design. To which my reply is, sure we can do better now, but not better enough. The fastest thing humans have ever designed is the Helios 2 shuttle, which hit a speed of 157,078 mph at its fastest (.023% of the speed of light). If we packed some people in this shuttle (which we couldn’t) and sent it off towards the nearest star (assuming that it stayed at this max speed the entire journey), guess how long it would take? Over 18 thousand years.
And keep in mind, this is only talking about the nearest star, let alone spreading across the galaxy! It should be totally evident to everybody that the technology we would need to be able to reach the stars is still far far away. But let’s put aside the limits of our current technology. We are still in our infancy as a space-faring species in many ways, and it is totally unfair to treat our current technology level as if it’s something set in stone. Let’s give the futurists the full benefit of the doubt, and imagine that in the future humans will be able to harness incredible quantities of energy that vastly surpass anything we have today. If we keep increasing our energy capacity more and more, is there any limitation on how fast we could get a spacecraft going? Well, yes there is! There is a fundamental cosmic speed limit built into the of the universe, which is of course the speed of light. The speed-vs-energy curve has a vertical asymptote at this value; no finite amount of energy can get you past this speed.
So much for arbitrarily high speeds. What can we do with spacecraft traveling near the speed of light? It turns out, a whole lot more! Suppose we can travel at 0.9 times the speed of light, and grant also that the time to accelerate up to this speed is insignificant. Now it only takes us 4.7 years to get to the nearest star! The next closest star takes us 6.6 years. Next is 12.3 years. This is not too bad! Humans in the past have made years-long journeys to discover new lands. Surely we could do it again to settle the stars.
But now let’s consider the trip to the center of the galaxy. At 90% the speed of light, this journey would take 29,000 years. As you can see, there’s a massive difference between jumping to nearby stars and attempting to actually traverse the galaxy. The trouble is that most people don’t realize just how significant this change in distance scale is. When you hear “distance to Alpha Centauri” and “distance to the center of the Milky Way”, you are probably not intuitively grasping how hugely different these two quantities are. Even if we had a shuttle traveling at 99.99% times the speed of light, it would take over 100,000 years to travel the diameter of the Milky Way.
You might be thinking “Ok, that is quite a long time. But so what! Surely there will be some intrepid explorers that are willing to leave behind the safety of settled planets to bring civilization to brand new worlds. After all, taking into account time dilation, a 1000 year journey from Earth’s perspective only takes 14 years to pass from the perspective of a passenger on a ship traveling at 99.99% percent of the speed of light.”
And I accept that! It doesn’t seem crazy that if humans develop shuttle that travel a significant percentage of the speed of light, we could end up with human cities scattered all across the galaxy. But now the issue is with the idea of a galactic CIVILIZATION. Any such civilization faces a massive problem, which is the issue of communication. Even having a shared society between Earth and a planet around our nearest star would be enormously tricky, being that any information sent from one planet to the other would take more than four years to arrive. The two societies would be perpetually four years behind each other, and this raises some serious issues for any central state attempting to govern both. And it’s safe to say that no trade can exist between two planets that have a 10,000 year delay in communication. Nor can any diplomacy, or common leadership, or shared culture or technology, or ANY of the necessary prerequisites for a civilization.
I think that for these reasons, it’s evident that the idea of a Galactic Empire like Asimov’s could never come into being. The idea of such a widespread civilization must rely on an assumption that humans will at some point learn to send faster than light messages. Which, sure, we can’t rule out! But everything in physics teaches us that we should be betting very heavily against it. Our attitude towards the idea of an eventual real life Galactic Empire should be similar to our attitude towards perpetual motion machines, as both rely on a total rewriting of the laws of physics as we know them.
But people don’t stop at a Galactic Empire. Not naming names, but I hear people that I respect throwing around the idea that humans can settle the universe. This is total madness. The jump in distance scale from diameters of galaxies to the size of the observable universe, is 40 times larger than the jump in distance scale we previously saw from nearby stars to galactic diameters. The universe is really really big, and as it expands, every second more of it is vanishing from our horizon of observable events.
Ok, so let’s take the claim to be something much more modest than the literal ‘settle galaxies all across the observable universe’. Let’s take it that they just mean that humans will spread across our nearest neighborhood of galaxies. The problem with this is again that the distance scale in question is just unimaginably large. Clearly we can’t have a civilization across galaxies (as we can’t even have a civilization across a single galaxy). But now even making the trip is a seemingly insurmountable hurdle. The Andromeda Galaxy (the nearest spiral galaxy to the Milky Way) is 2 million light years away. Even traveling at 99.99% of the speed of light, this would be a 28,000 year journey for those within the ship. From one edge of the Virgo supercluster (our cluster of neighbor galaxies) to the other takes 110 million years at the speed of light. To make this trip doable in a single lifetime requires a speed of 99.999999999999% of c (which would result in the trip taking 16 years inside the spacecraft). The kinetic energy required to get a mass m to these speeds is given by KE = (γ – 1) mc2. If our shuttle and all the people on it have a mass of, say, 1000 kg, the required energy ends up being approximately the entire energy output of the Sun per second.
Again, it’s possible that if humans survive long enough and somehow get our hands on the truly enormous amounts of energy required to get this close to the speed of light, then we could eventually have human societies springing up in nearby galaxies, in total isolation from one another. But (1) it’s far from obvious that we will ever be capable of mastering such enormous amounts of energy, and (2) I think that this is not what futurists are visualizing when they talk about settling the universe.
Let me just say that I still love science fiction, love futurism, and stand in awe when I think of all the incredible things the march of technological progress will likely bring us in the future. But this seems to be one area where the way that our future prospects are discussed is really far off the mark, and where many people would do well to significantly adjust their estimates of the plausibility of the future trajectories they are imagining. Though science and future technology may bring us many incredible new abilities and accomplishments as a species, a galactic or intergalactic civilization is almost certainly not one of them.





 . The total amount of product on the market will be given the label
. The total amount of product on the market will be given the label 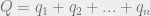 . Since the firms are all selling identical products, it makes sense to assume that the consumer demand function
. Since the firms are all selling identical products, it makes sense to assume that the consumer demand function  will just be a function of the total quantity of the product that is on the market:
will just be a function of the total quantity of the product that is on the market: 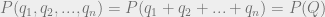 . (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)
. (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)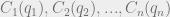 . Now we can figure out the profit of each firm for a given set of output values
. Now we can figure out the profit of each firm for a given set of output values  . This profit is just the amount of money they get by selling the product minus the cost of producing the product:
. This profit is just the amount of money they get by selling the product minus the cost of producing the product:  .
. . This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms!
. This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms! and
and 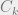 , we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.
, we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.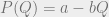 (for some a and b) and
(for some a and b) and  . As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
. As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
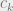 represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.)
represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.) . Rewriting, we get
. Rewriting, we get  . We can’t immediately solve this for
. We can’t immediately solve this for  , because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!
, because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!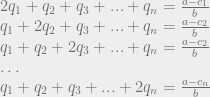



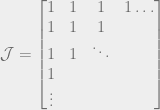



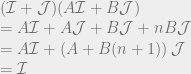


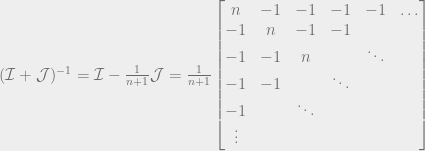
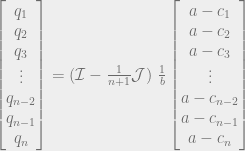
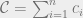
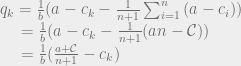
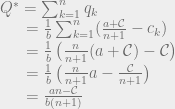
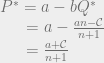



 intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity
intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity  , the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
, the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
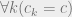

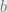 ) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!
) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!