What is classification?
Classification is one of the most basic human activities. We wake up to a world of vibrant experience and immediately begin structuring it, organizing it into objects and actions, people and animals, edible and non-edible, friend and foe, and so on. Eventually our system of classifications becomes immense and interconnected, partitioning up the world of blooming buzzing confusion into a million tiny but intelligible pieces.
In the real world, classification is often vague. In math, it can be made a bit more precise through the notion of an equivalence relation. An equivalence relation can be thought of in two ways. First, concretely, it’s a way to “carve up” a set, partitioning it into disjoint pieces called equivalence classes. Every element x of the original set appears in exactly one equivalence class, which is referred to as [x].
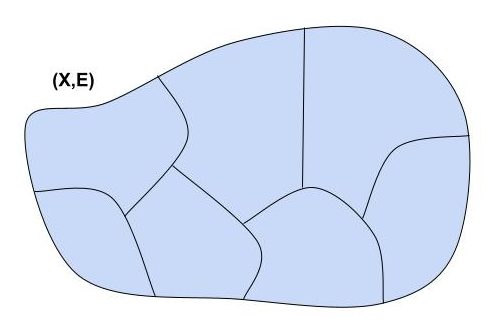
More abstractly, an equivalence relation on a set X is a binary relation E on X satisfying three axioms:
- Reflexivity: (∀x ∈ X) (x E x)
- Symmetry: (∀x,y ∈ X) (x E y ⇒ y E x)
- Transitivity: (∀x,y,z ∈ X) (x E y E z ⇒ x E z)
One can prove that any binary relation satisfying these three axioms yields a carving-up of X in the sense described above.
One thing that classification systems allow you to do is to coarse-grain the world, forgetting about the finer details and remembering only higher-order properties. Rather than think about my dog in particular, I can think about the class of all dogs, and treat this class as an object in its own right. Mathematically, this is called quotienting.
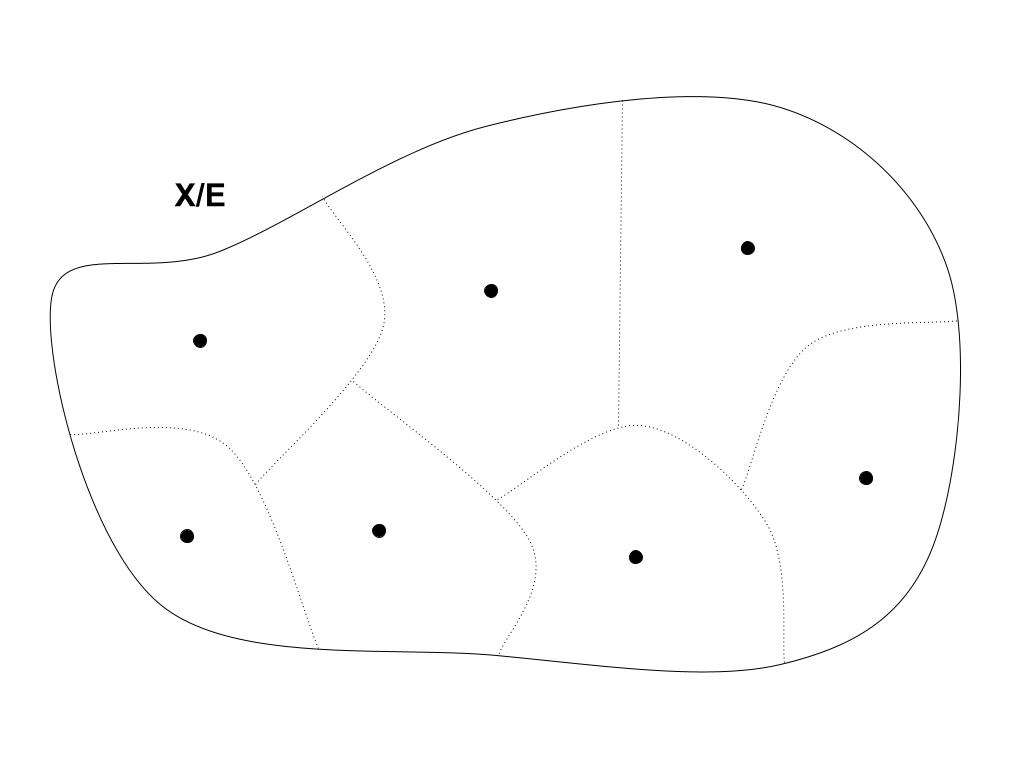
Quotienting is a very common mathematical move that appears wherever there are equivalence relations around. If E is an equivalence relation on a set X, then the quotient of X by E (written X/E) is just the set of all the equivalence classes.
X/E = { [x] | x ∈ X }
Quotienting can change structures in interesting and complicated ways. One of the most common examples is ℤn (the integers mod n), which we get by quotienting the integers ℤ by the “differs-by-n” equivalence relation:
x ~ y ⇔ |x – y| = n
For instance, in ℤ5, the number 2 is identified with the equivalence class [2] = {…, -8, -3, 2, 7, 12, …}.
Equally common, the real numbers are often defined by quotienting. You start with the set of all Cauchy sequences of rational numbers, and consider the equivalence relation of “converging to one another” between sequences:
x ~ y ⇔ limn→∞ |xn – yn| = 0
A real number is defined to be an equivalence class of such sequences. This is a good example of coarse-graining in practice. You never really think of real numbers as sets of Cauchy sequences of rationals (outside of an analysis course). Once you quotient out by this equivalence relation, you forget about this “internal structure” and treat each real number as a primitive object. Similarly, in ℤ5 you think of 2 as a primitive element, not an infinite set of integers.
Some classifications are harder than others
Let’s quickly recap the discussion in the last post.
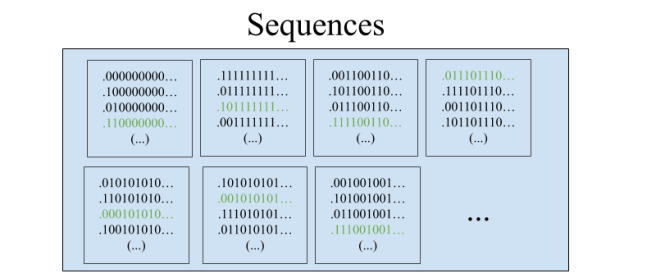
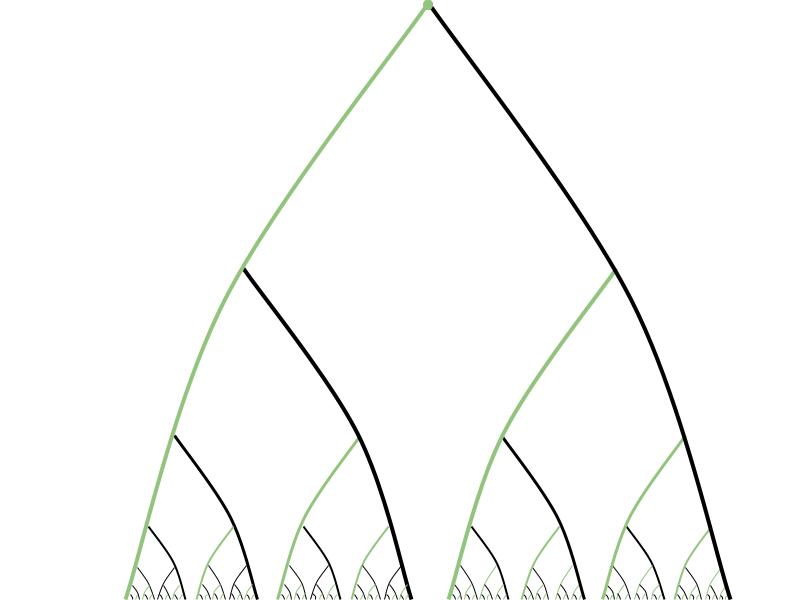
We began with an infinite group of prisoners whose freedom rested on their ability to pick representatives from a particular equivalence relation on Cantor space, 2ℕ. Cantor space can be thought of in many ways. In our case, it’s the space of all ways of assigning black and white hats to the lineup. It’s also the space of all infinite binary sequences, or equivalently all functions from ℕ to {0,1}. And it can be visualized as the infinite paths through the complete infinite binary tree.
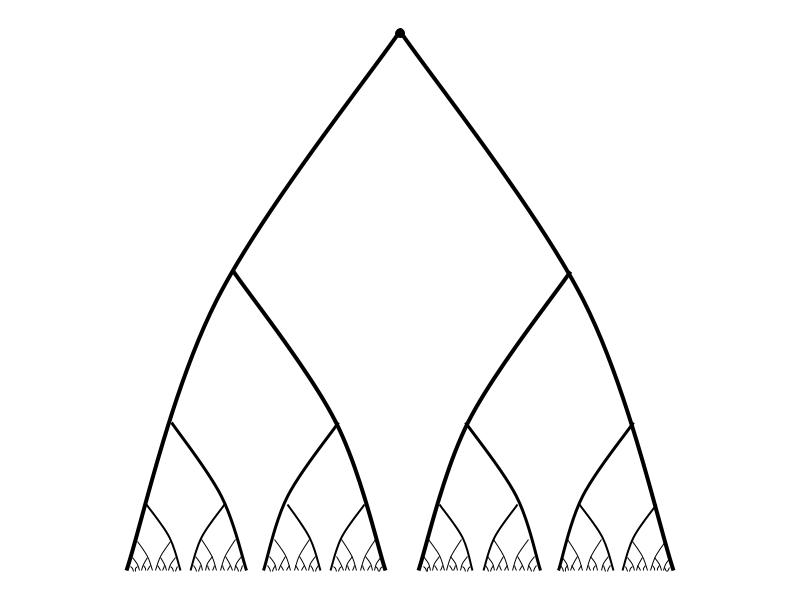
The equivalence relation the prisoners found themselves stuck with was the “eventually agrees” relation, E0, defined by:
x E0 y ⇔ (∃n ∈ ℕ) (∀m > n) (xm = ym)
For instance, here’s what the equivalence class of the all-zeros sequence 000… looks like:
The prisoners had to find some way of agreeing on a choice of representative from each equivalence class. There’s actually a few different ways to formalize this idea: transversals, selectors, and reductions.
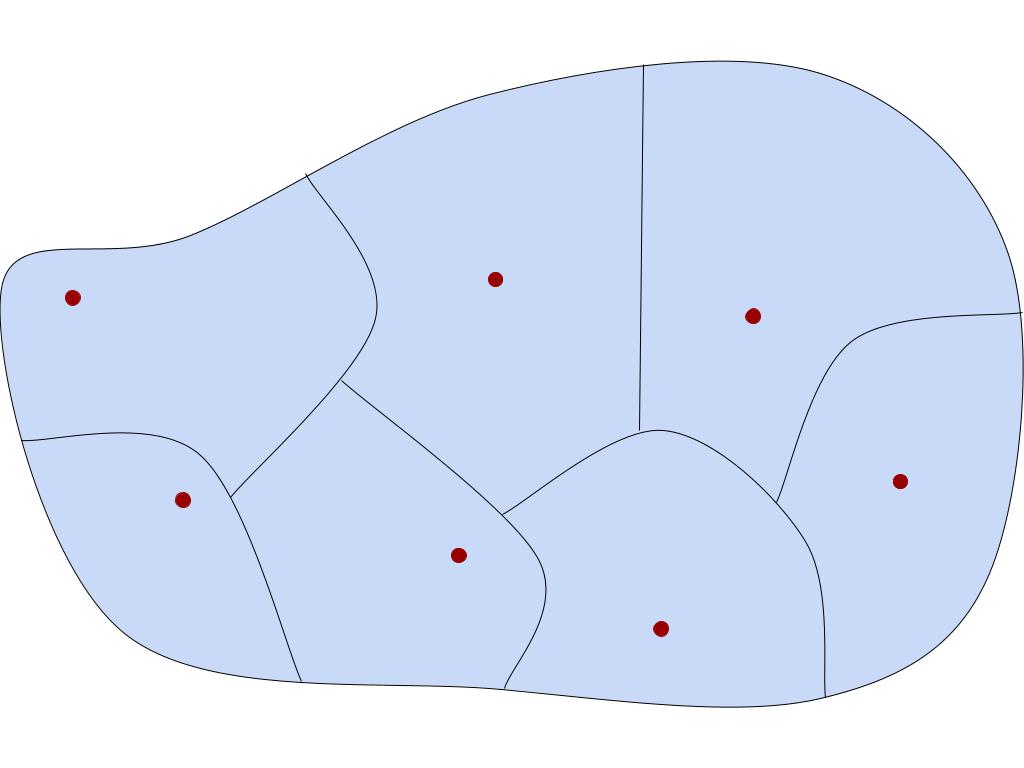
A transversal of an equivalence relation E on X is a subset A ⊆ X which intersects each E-class exactly once.
(∀C ∈ X/E) (|A ∩ C| = 1)
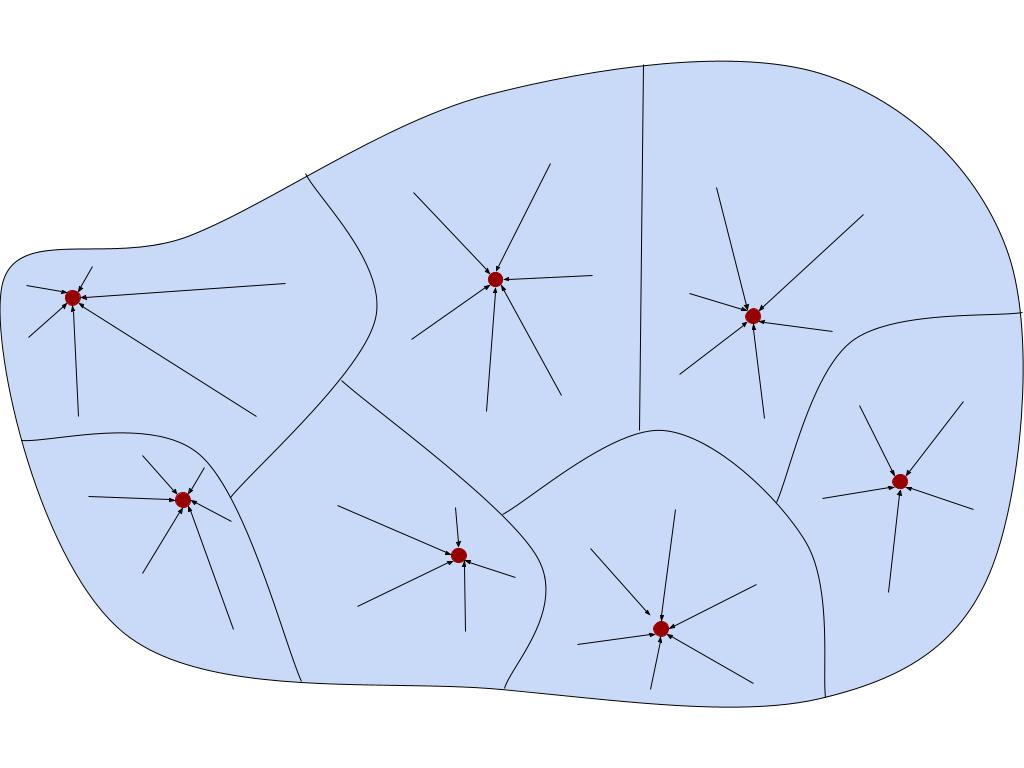
A selector for an equivalence relation E on X is a function f: X → X which takes the elements of an equivalence class C to the representative element for C.
(∀x ∈ X) (f(x) ∈ [x]E) and (∀x,y ∈ X) (xEy ⇒ f(x) = f(y))
And finally (and most importantly) there’s the idea of a reduction. This idea is significantly more general than the previous two, and will play a big role in the upcoming posts. First, the formal definition:
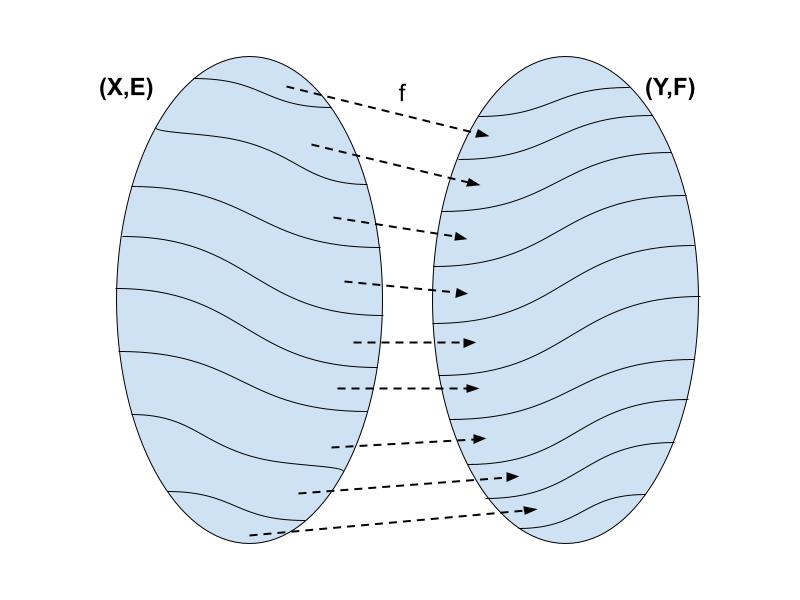
Given two sets X,Y and equivalence relations E (on X) and F (on Y),
a reduction of E to F is a function f: X → Y such that
(∀x, x’ ∈ X) (x E x’ ⟺ f(x) F f(x’))
If such a function exists, we say that E is reducible to F and write E ≤ F.
Informally, reducibility measures the relative complexity of equivalence relations. If E ≤ F, then E is “simpler” or “easier. to compute” than F. For instance, if we want to check if two elements x and x’ are E-related, we can instead check if f(x) and f(x’) are F-related. Thus if we had an oracle for F then we could figure out E (using f).
A special case of reduction is where F is just the identity relation =Y on Y, in which case we have:
xEx’ if and only if f(x) = f(x’)
Now, if we’re allowed to use any function f whatsoever, then this notion of reducibility ends up not being not so interesting. For instance, we can reduce any equivalence relation to equality by choosing Y = X/E and defining f(x) = [x]E. More generally, reducibility with arbitrary functions turns out to just be a matter of comparing the cardinalities of the quotients. Thus we shift our focus from arbitrary functions to definable functions, in the sense of Borel.
In the last post we talked about Borel subsets of a space, not functions. But a function can be identified with its graph and treated as a subset of X × Y. So f: X → Y is Borel if and only if it is Borel as a subset of X × Y. Borel relations are defined similarly.
(Reminder: the Borel sets in a topological space X are just the sets you can construct out of open sets through countable unions, intersections, and complements. Equivalently, they’re the sets definable in countable propositional logic, with atomic propositions interpreted as defining the basic open sets.)
(Notice that we’re taking advantage of the relationship between definability and topology: if X and Y are both topological spaces, then the product X × Y already has a canonical “product topology”, generated by products of open sets in X and Y. So once we know how to interpret the atomic propositions in X and in Y, we can automatically interpret atomic propositions in X × Y.)
We’ve finally arrived at the central concept: Borel reducibility or definable reducibility.
Given two topological spaces X,Y and equivalence relations E (on X) and F (on Y),
a Borel reduction of E to F is a Borel function f: X → Y such that
(∀x, x’ ∈ X) (x E x’ ⟺ f(x) F f(x’))
If such a function exists, we say that E is Borel reducible to F and write E ≤B F.
Classifying classifications
Let me now get to the punchline.
We carve up the mathematical universe by defining equivalence relations on the sets we’re interested in. When these sets are topological spaces, we can compare these equivalence relations through the relationship of Borel reducibility. At the end of the last post, I told you that there was no Borel transversal of E0. By the same token, there is no Borel reduction of E0 to the identity relation on Cantor space. “Eventual equality” is a strictly more complicated notion than “equality”.
This might not sound very surprising. Of course eventual equality is more complicated than equality, it has an extra word in its name! But it turns out that lots of complicated-looking equivalence relations are Borel reducible to the equality relation. Such equivalence relations are called smooth or concretely classifiable. For example, the relationship of “similarity” between square matrices (intuitively, two matrices are similar if they represent the same linear transformation but in different bases) turns out to be smooth.
E is smooth if and only if there’s a Borel reduction E ≤B =ℝ
(Notice that I defined it here in terms of identity on ℝ rather than 2ℕ. Not all identity relations are of equal complexity, but these two are. We’ll see that for many purposes ℝ and 2ℕ are interchangeable.)
The smooth equivalence relations are the simplest ones out there. If E is smooth, then there’s some definable way to assign a different real number to each class. We can begin to draw a picture of the Borel reducibility hierarchy:
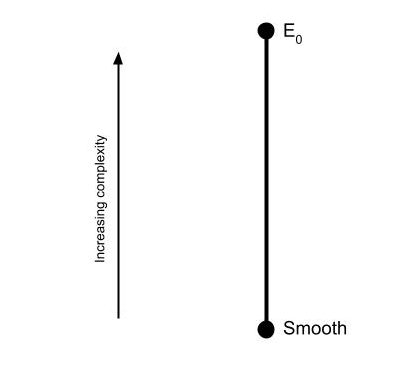
Natural questions immediately arise. Are there any equivalence relations strictly between smooth and E0? (No.) Are there equivalence relations above E0? (Yes, many.) Is there a most complex equivalence relation? (No, for any equivalence relation there’s a strictly harder one.) Are there equivalence relations of incomparable complexity? (Yes, in fact there’s uncountably many such equivalence relations!)
The Borel reducibility hierarchy for equivalence relations is a relatively recent discovery in the history of mathematics. It’s only about twenty years old. As such, there are many open questions about its structure. For instance, at the time of writing it’s unknown whether there’s exactly one class directly above E0. There could be multiple incomparable classes directly above E0, or it could be that for any equivalence relation E above E0, there’s another one strictly in between E0 and E.
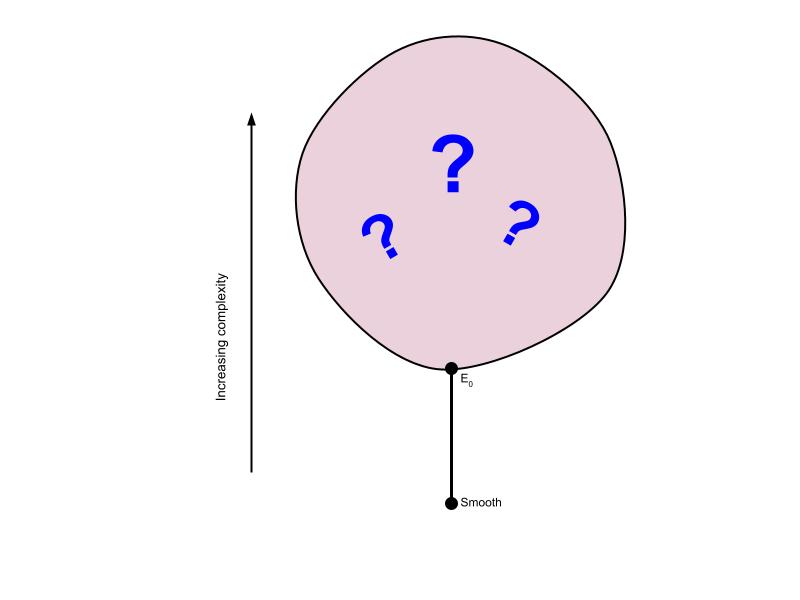
The big balloon represents the unknown territory waiting to be explored. But one thing that is clear at this point is that the internal structure of this balloon is very rich. In upcoming posts I hope to describe some of what we do know about it, and describe some recent attempts to probe its structure using techniques in model theory and infinitary first-order logic.