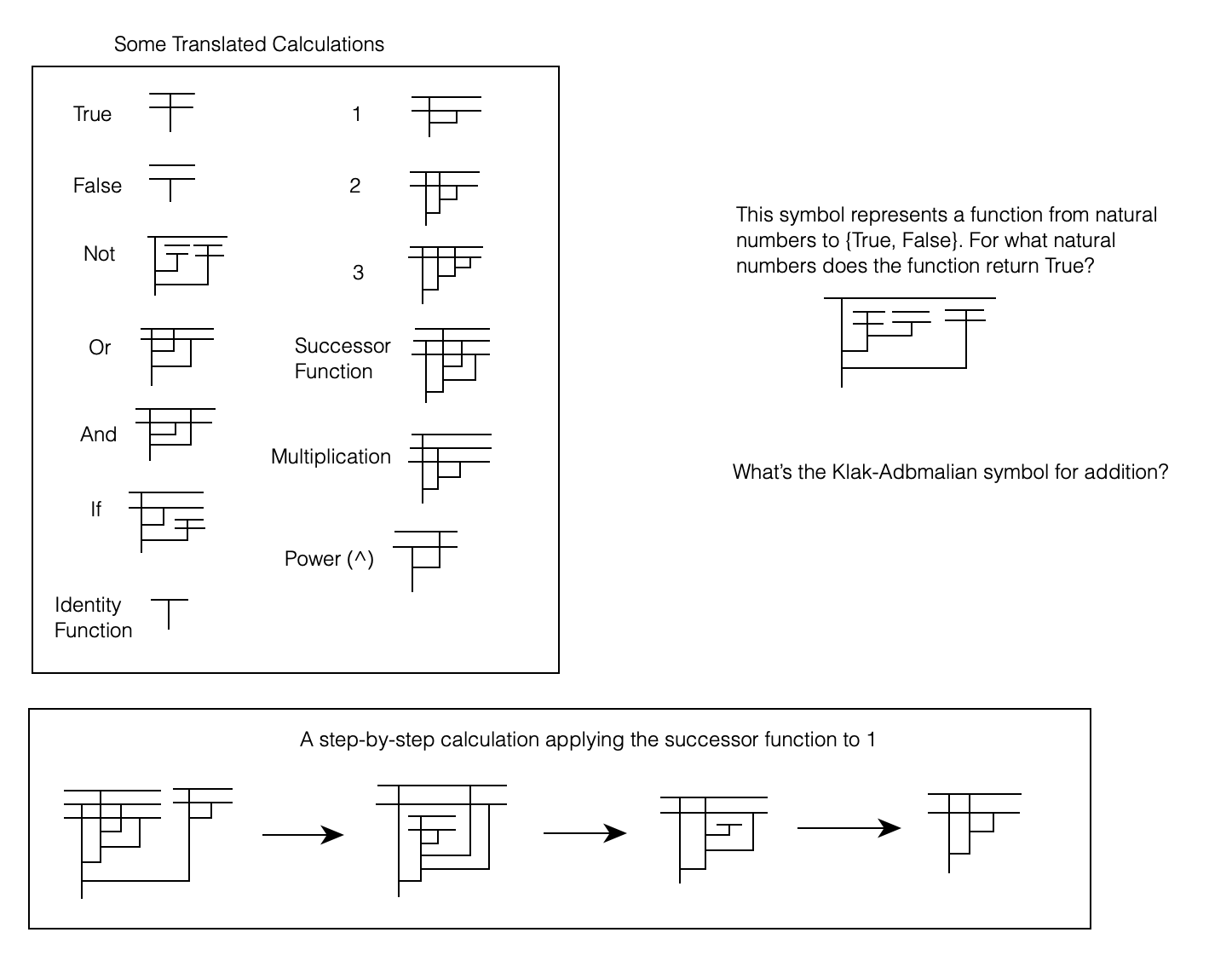
A while back, I wrote a several-part introduction to mathematical logic. I wrote this when I was first wading into the subject and noticed that a lot of the stuff I was learning was not easy to find online in a concise beginner-level essay. Since then, I’ve learned an enormous amount more and become a lot more comfortable with the basics of the field. Looking back on my introduction series, I’m pretty happy with it. There’s nothing in there that’s incorrect. But I do notice that when I read it over, I wish that I had framed certain things slightly differently. In particular, one of the distinctions that I think is absolutely central to mathematical logic – the distinction between syntax, semantics, and proof – is muddled a bit in the write-up, and proof is bundled in with syntax in a way that I’m not totally satisfied with.
Given that, and given that this series is for whatever reason now one of the most popular reads on my blog, I want to provide a brief update post. I sort of did this a week or so ago, with this post, which linked to the slides for a presentation I gave for a discussion group. But I want to do it for REAL now, as an actual post of its own. And honestly, I also just love this subject and am happy for any excuse to write about it more.
So, let me begin by laying out what seems to me to be the primary trichotomy that you’ll see pop up over and over again in logic: syntax, semantics, and proof. One at a time, then.
Syntax
The syntax of a logic is a detailing of the allowed symbols of a language and the conditions for their grammatical use. It’s a set of characters, along with a function that defines the grammar of the language by taking in (finite, in most logics) strings of these characters and returning true or false. This function is usually inductively defined. So for instance in propositional logic we have some set of characters designated to be our propositional variables (we’ll denote them p, q, r, …), and another set of characters designated to be our logical symbols (∧, ∨, ¬, →, and parentheses). We inductively define our grammar function G as follows: Every propositional variable is grammatical. If X and Y are grammatical strings, then so are (¬X), (X ∧ Y), (X ∨ Y), and (X → Y). And no other string is grammatical. This definition is what allows us to say that (p ∧ (¬(q ∨ r))) is grammatical but (p ∧ (¬(q ∨ ¬))) is not. The grammar for propositional logic is especially nice and simple, and first-order logic is only mildly more complicated. The important thing is that the syntax for these logics as well as higher order logics is algorithmically checkable; it’s possible to write a simple program that verifies whether any given input string counts as grammatical or not.
Semantics
The semantics of a logic is a system for assigning some sort of meaning to the grammatical strings of the language. There are different types of meanings that might be assigned, but the primary one for classical logic is truth and falsity. For propositional logic, our semantics is a set of truth functions, which are functions that take in grammatical strings and return either true or false (you’ve encountered these before if you’ve seen truth tables; each row in a truth table corresponds to a particular truth function). Not just any such function will do; these functions will have to satisfy certain constraints, such as that whatever a truth function assigns to a string X, it must assign the opposite value to the string (¬X), and that (A ∧ B) is assigned true if and only if both A and B are assigned true. These constraints on our functions are really what endow our strings with meaning; they induce a sort of structure on the truth values of strings that lines up with our intended interpretation of them.
For propositional logic, we give an inductive definition for our collection of valid truth functions. We construct a truth function by first doing any assignment of truth values to the propositional variables (p, q, r, and so on), and then defining what the function does to the rest of the strings in terms of these truth values. So for any strings X and Y, the truth function assigns true to (¬X) if and only if it assigns false to X. It assigns true to (X ∧ Y) if and only if it assigns true to X and true to Y. And so on. By our construction of the grammar of propositional logic, we’ve guaranteed that our function is defined on all grammatical strings. Of course, there are many such truth functions (one for every way of assigning truth values to the propositional variables) – and this collection of truth functions is what defines our semantics for propositional logic.
First order logic is again more complicated than propositional logic in its semantics, but not hugely so. When talking about the semantics of first-order logic, we call its truth functions models (or structures), and each model comes with a universe of objects that the quantifiers of the logic range over. An important difference between the semantics of propositional logic and the semantics of first order logic is that in the former, we can construct an algorithm that directly searches through the possible truth functions. In the latter, getting a similar sort of direct access to the models is much more difficult. Consider, for instance, that some models will have universes with infinitely many elements, meaning that to verify the truth of a universally quantified statement requires verifying it for infinitely many elements.
Last thing I need to say about semantics before moving on to proof: there is the all-important concept of semantic entailment. A set of sentences (call it A) is said to semantically entail another sentence (call it X), if every truth function that assigns everything in A true also assigns X true. When this is the case, we write: A ⊨ X.
Examples
{(p ∧ q)} ⊨ p
{(p ∨ q), (¬q)} ⊨ p
{p, (p→q), (q→r)} ⊨ r
Proof
Notice that we defined our semantics using complicated words like “functions” and “inductive definition”. More troubling, perhaps, we seem to have engaged in a little bit of circularity when we said in our definition of the semantics that (A ∧ B) is assigned true only when A and B are both assigned true. Suppose that some pesky philosopher were to come up to us and ask us what we meant by “only when A and B are both assigned true”. What would we have to say? We couldn’t refer to our formal definition of the semantics of ∧ to ground our meaning; as this definition uses the concept of “and” in it explicitly! The circularity is even more embarrassingly vivid when in first order logic we’re asked to define the semantics of “∀”, and we say “∀x φ(x) is true whenever φ(x) is true of every object in our model”. In other words, there’s a certain sense in which our semantics is a little hand-wavy and non-rigorous. It relies on the reader already having an understanding of mathematical concepts that are usually much more advanced than the ones being defined, and indeed implicitly relies on the reader’s understanding of the ones being defined in the first place!
With this criticism of semantics fresh in our heads, we might want to ask for a purely mechanical system that would take in some starting strings and churn out new strings that follow from them according to the semantics. Such a system wouldn’t rely on the user’s understanding of any higher-order concepts; instead a mere understanding of the concept of string manipulations would suffice. That is, we want to rigorously define such a procedure so that the results of the procedure mirror the structure that we know the semantics has, but without relying on any high-level concepts or circularity. We can instead just point to the mechanical process by which strings of these symbols are manipulated and be content with that. A proof system is just such a mechanical system.
There are multiple styles of proof systems, varying primarily with respect to how many inference rules and axioms they have. On the side of many axioms and few inference rules we have Hilbert-style systems. And on the side of many inference rules and few (sometimes zero) axioms we have Gentzen-style natural deduction systems. But hold on, what are these “axioms” and “inference rules” I’m suddenly bringing up? Axioms are simply strings that can be used in a proof at any time whatsoever. Inference rules are functions that take in some set of strings and produce new ones. A proof is just an ordered list of strings, where each is either an axiom or a result of applying some inference rule to earlier strings.
For propositional logic, one common proof system involves just three axioms and one inference rule. The three: X → (Y → X), (X → (Y → Z)) → ((X → Y) → (X → Z)), and ((¬Y) → (¬X)) → (X → Y). The inference rule is the famous modus ponens, which takes the form of a function that takes as input X and X → Y, and produces as output Y.
(The discerning amongst you might notice that the “three axioms” are actually three infinite axiom schemas; for each you can populate X, Y, and Z with any three grammatical strings you like and you get a valid instance of the axioms. The even more discerning might notice that these axioms only involve the → and ¬ symbols, but we seem to be missing ∧ and ∨. That’s correct; we neglect them for economy of our proof system and are allowed to do so because all sentences with ∧ and ∨ can be translated into sentences using just → and ¬. To expand our proof system to deal with ∧ and ∨, we simply add a few more axioms to incorporate these translations.)
Soundness and Completeness
I’ve said that the purpose of a proof system is to mimic the semantics of a logic. I will now say more precisely what this mimicry amounts to.
There is a close cousin to the semantic-entailment relation (⊨). This is known as the syntactic entailment relation, and is written ⊢. We say that a set of sentences A syntactically entails a sentence X if there exists some proof that uses the sentences in A as assumptions and concludes with the sentence X. So A ⊢ X can be thought of as “X can be proven, provided that we assume A.”
To say that a proof system for a logic mimics the semantics of the logic is to say that the syntactic entailments and semantic entailments line up perfectly. This has two components:
Soundness: If A ⊢ X, then A ⊨ X.
Completeness: If A ⊨ X, then A ⊢ X.
There’s one other feature of a proof system that’s totally essential if it’s to do the job we want it to do; namely, that it should be actually computable. We should be able to write an algorithm that verifies whether any given sequence of strings counts as a valid proof according to the proof system. This is known as effective enumerability.
To have a sound, complete, and effectively enumerable proof system for a logic is to know that our semantics is on solid ground; that we’re not just waving our hands around and saying things that cannot be cashed out in any concrete way, but that in fact everything we are saying can be grounded in some algorithm. There’s a general philosophy in play here, something like “if I can compute it then it’s real.” We can rest a lot more comfortably if we know that our logic is computable in this sense; that our deductive reasoning can be reduced to a set of clear and precise rules that fully capture its structure.
Perhaps predictably, our next question is whether we really do have a sound, complete, and effectively enumerable proof system for a logic. It turns out that the answer depends on which logic is being discussed. This is already perhaps a little disconcerting; we might have hoped that every logic of any use can be nailed down concretely with a proof system. But alas, it’s not the case.
With that said, there do exist sound, complete, and effectively enumerable proof systems for propositional logic. Maybe that’s not so exciting, since propositional logic is pretty limited in terms of what sort of math you can do with it. But it turns out that sound complete and effective proof systems ALSO exist for first-order logic! And first-order logic is where we form theories like Peano arithmetic (for natural number arithmetic) and ZFC (for set theory).
In other words, there’s a logic within which one can talk about things like numbers and sets, and the semantics of this logic can be made precise with a proof system. That’s great news! Math is on sound grounds, right? Well…
You might be skeptical right now, the phrase “incompleteness theorems” bubbling into your mind, and you’re right to be. While we can form languages in first order logic whose sentences look to be describing natural numbers (in PA) or sets (in ZFC), it turns out that none of these languages have the expressive power to actually pin down these structures uniquely. Said more carefully, there is no first-order collection of sentences which has as a unique model the natural numbers. There’s a theorem called the Löwenheim-Skolem Theorem, which is one of the most shocking results in the field of mathematical logic. It says that if a first-order theory has any infinite model, then it has infinite models of every cardinality. So if we want to describe the natural numbers, we have to also be simultaneously describing structures of every cardinality. At this point, this is getting into well-covered territory for this blog, so I’ll just direct you to these posts for more detail about how this works: here, here, and here.
So, in first order logic you have a proof system that perfectly mirrors your semantics but no theory whose semantics line up with the natural numbers. There are many ways we can strengthen our semantics to give us the strength to talk about the natural numbers categorically, the most popular of which is second-order logic. In second order logic, we are allowed to quantify not only over objects in our universe, but over sets of objects as well. This turns out to be a really big deal. In second-order logic, we can actually write down a set of sentences that uniquely pick out the natural numbers as their only model. But guess what? Second-order logic has no sound and complete proof system!
This is a pattern that holds very generally. Either we have a logic with the expressive power to talk categorically about the natural numbers, in which case we have no sound and complete proof system, OR we have a logic with a sound and complete proof system, in which case we lack the ability to talk categorically about the natural numbers. No matter how we go, we end up at a loss as to how to ground the semantics of ℕ in an algorithmic procedure. And as a result, we also end up unable to have any algorithmic procedure that enumerates all the truths about natural numbers. This is what has become known as the incompleteness phenomenon.
I’ll stop there for now! Here’s a brief summary of the main concepts I’ve discussed. A logic defined by its syntax, semantics, and proof system. The syntax details the allowed symbols of the language and which combinations are grammatical. The semantics details the possible truth assignments to these sentences, consistent with our intended interpretation of the symbols. And the proof system provides a mechanical procedure for deriving new strings from old strings. A set of strings X semantically entails a string Y if every truth assignment that satisfies all the strings in X also satisfies Y. A set of strings X syntactically entails Y if there’s some proof of Y from the assumptions of X. A proof system is said to be sound and complete if its syntactic entailment relation perfectly mirrors the semantic entailment relation. And it’s said to be effectively enumerable if there’s an algorithm for determining whether a given sequence of strings counts as a proof or not. First-order logic has a sound, complete, and effectively enumerable proof system. But it lacks the expressive power to talk categorically about the natural numbers. No set of sentences in a first-order language has the natural numbers as a unique model. Second-order logic has the expressive power to talk categorically about the natural numbers, but it has no sound and complete proof system. In general, no logic has both (1) a sound, complete, and effectively enumerable proof system, and (2) theories that are categorical for the natural numbers.