One of my favorite bits of mathematics is the Collatz conjecture. It’s so simple that you can explain it to any grade schooler, and yet is so mysterious that Paul Erdös declared “Mathematics may not be ready for such problems.”
Here’s the conjecture:
Take any natural number N. If this number is even, divide it by two. If on the other hand N is odd, we multiply it by three and add 1. So N becomes N/2 if N is even, and 3N+1 if N is odd. Now, repeat this process for the resulting number! If even, divide by two. If odd, multiply by three and add one. And then repeat with the new number, and keep on chugging away.
The conjecture is that you will always eventually get to 1 (regardless of the initial value of N!)
That’s it! It’s that simple. Here are some examples:
Say we start with N=2. Since 2 is even, we divide by 2 and get 1. And that’s that, we’re done!
What if we start with N=3? Now, since 3 is even, we must multiply by three and add 1. So 3 becomes 10. 10 is even, so we divide by 2 to get 5. And 5 is odd, so we multiply by three and add one to get 16. And lo and behold, 16 goes to 8, which goes to 4, which goes to 2, and then back down to 1!
Here’s a table of the first few “Collatz sequences”:

A few comments:
First, if you look closely, you’ll notice that there’s a lot of repetition in that list. For instance, look at the chain that starts at 9. It ends up at 7 after just three steps. And then the whole rest of the chain is identical to the one two above it! And starting at 10, one step takes us to 5, the chain of which we had already calculated.
This hints that any method for calculating the Collatz sequences of numbers could likely benefit from dynamic programming: using the work you’ve previously done to make your future tasks quicker. Think about it, by calculating the chains of just the numbers 3 through 10, we’ve also managed in the process to figure out the exact chains for 11, 13, 14, 16, 17, 20, and more numbers up to 52!
Second comment: Notice that these chains look really weird. They jump up and down unpredictably, and their lengths are all over the place. Here’s what the “9” chain looks like as it jumps up and down:

And, to take an even more dramatic example, here’s what the chain starting with 27 looks like:

That takes 111 steps to stop! And in the process, it rises as high as 9,232!
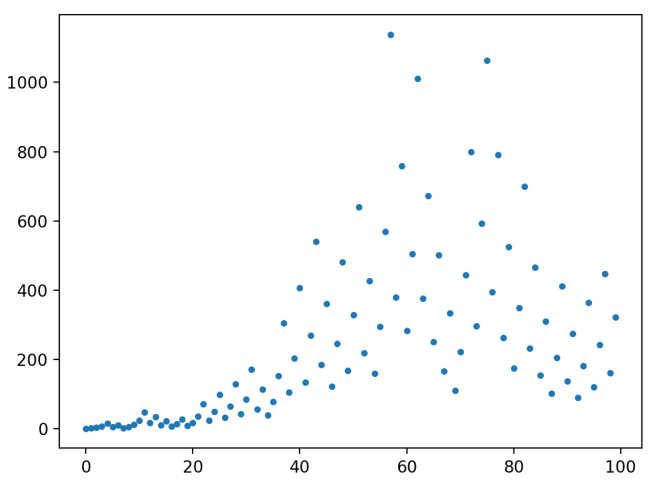
Based on this example, you might be thinking that these chains are in general going to increase faster than their starting value. But don’t be deceived: I cherry-picked 27 because I knew that it would generate an interesting long chain. In fact, the lengths of the chains are in general remarkably small relative to their starting value. Here’s a plot of the first 100 chain lengths:
Though the values are growing, and some of them are up in the 100s, most of them are in the sub-40 range.
If you’re like me, though, you might notice some very curious patterns in this graph. What’s going on with those clusters of three or two that keep showing up right beside each other? And why do we seem to have these two distinct “regions” of chain lengths? Let’s look to see if these patterns persist as we plot the chain lengths for higher values, this time up to 1000:
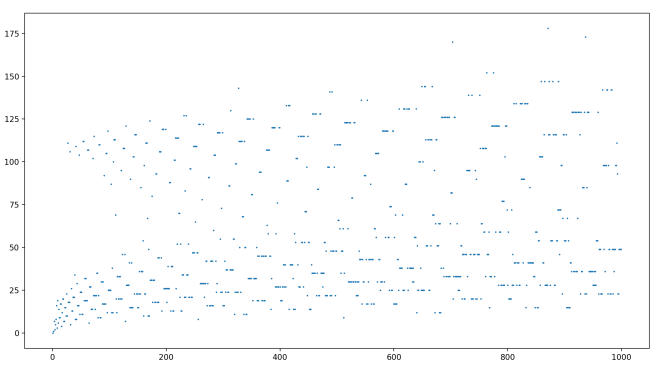
Interesting! So it appears like the “two regions” kind of blend together, but this pattern of strings of nearby numbers with similar chain lengths stays the same! This is extremely mysterious to me. Many of the time the specific paths the numbers take on their way to zero are quite different, so why should we see them having the same length?
Well, part of the answer might be that in fact, the paths taken by nearby numbers are sometimes actually not too different at all. For instance, 500 and 501 both take 110 steps to get to 1, but their chains become identical after just four steps. Let’s look closely at these steps:
500 becomes 250 becomes 125 becomes 376
501 becomes 1504 becomes 752 becomes 376
Let’s look in general at what happens to N and N+1 if they follow this exact sequence of moves:
N becomes N/2 becomes N/4 becomes 3N/4 + 1
N+1 becomes 3(N+1) + 1 becomes (3(N+1) + 1)/2 becomes (3(N+1) + 1)/4
But hold on: (3(N+1) + 1)/4 just is 3N/4 + 1! So in fact, we should expect that whenever we do these sequences of moves, N and N+1 will have the same chain length. And when does this happens? Well, N had to be divisible by 4 but not 8. And 3N + 4 had to be divisible by 4. This specific set of conditions is true for about 1/8 of all numbers, so this already tells us that at least 1/8 of neighboring numbers have the same length!
And this was only looking at chains that became identical after three steps! We could go further and look at other possible sequences of moves that would make our chains become identical quickly, and in the process get a better understanding of the structure of the graph.
By the way, want to see how this graph behaves for even larger starting values? Here ya go! N up to 10,000:
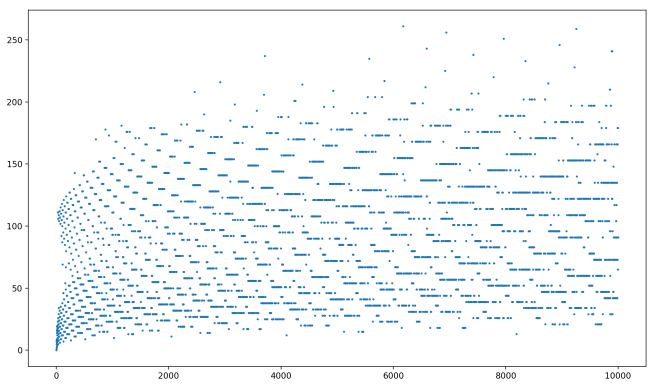
Our N has 10-tupled, but our chain lengths have barely increased at all! Same for N up to 100,000:
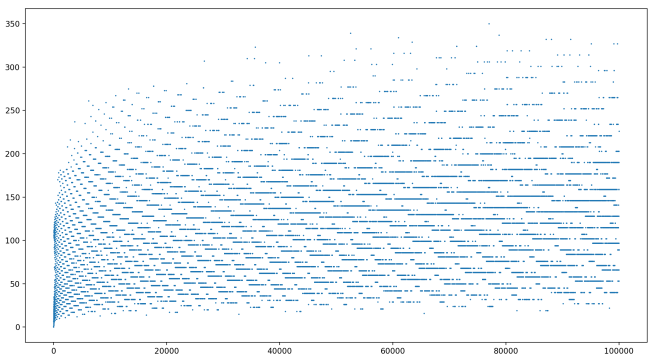
Same story! Increasing our N by a factor of 10 seems to really only increase our chain lengths by adding about 100! This indicates that the relationship between starting value and chain length might be logarithmic (a multiplicative increase in starting value corresponding to an additive increase in chain length). Let’s look at a semilog plot of the same range of starting values:
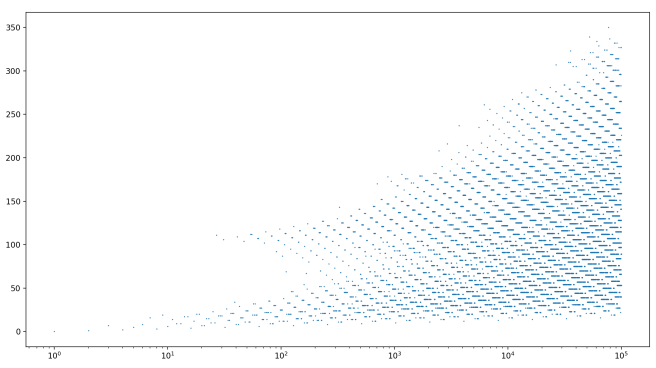
Wow! This exposes a whole new level of structure in the chain lengths. Look at all those parallel lines of clusters! And also look at how nicely linearly the chain lengths appear to grow with the exponent of the x-axis! This is a bit mind-blowing to me that the chain length of N seems to be so naturally related to log(N).
Extending this graph to 100 times more values of N:
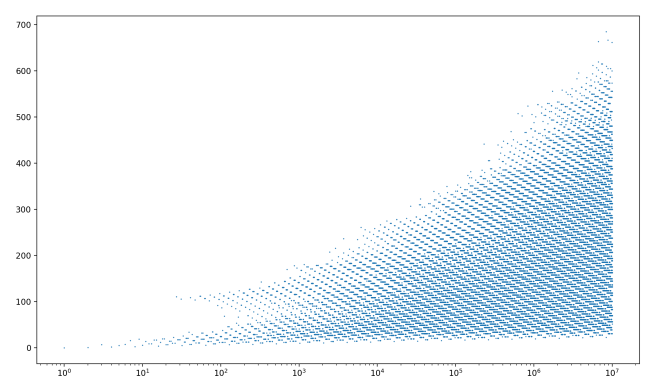
We can really clearly see how linear everything remains! Another feature that pops out here is the little “ledges” that occasionally jut out to the left in the graph. These tend to appear whenever we find an N whose chain length is dramatically larger than the previous numbers, and it then carries along some of its larger neighbors.
This might raise the question: how often do we actually see new record chain lengths? I mean, clearly we’re going to get larger and larger chain lengths forever, off to infinity, but how often do these record-breaking chains appear?
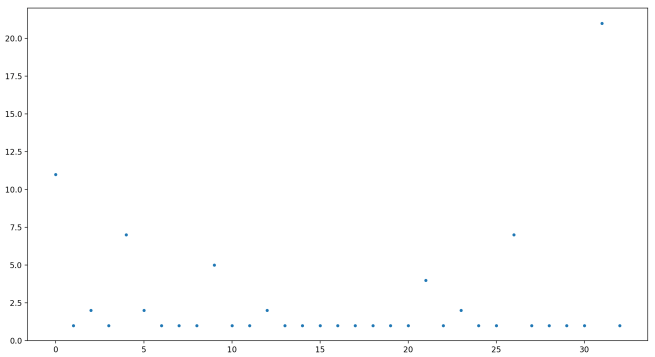
Surprisingly rarely! Let’s define a record-breaking Collatz chain as a Collatz chain such that all the Collatz chains with smaller starting values are shorter in length. Let’s look at where these record-breakers appear for N up to 100,000:
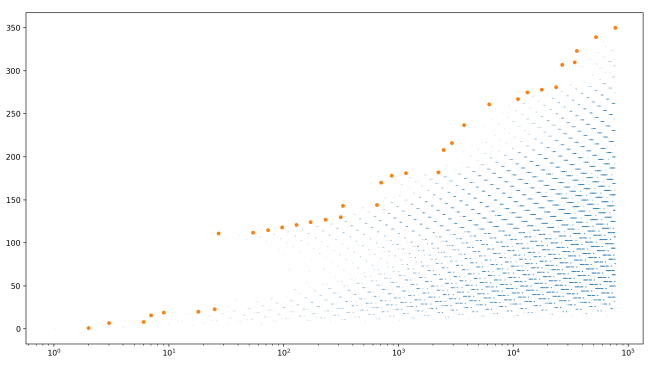
They look pretty evenly spaced! But remember, the x-axis is growing exponentially. So in fact, they get exponentially farther apart.
By the way, look at that weird straight line that appears about midway between 101 and 102. The exact values of these record breakers are:
54: 112
73: 115
97: 118
129: 121
171: 124
241: 127
313: 130
That’s right, the record increases by exactly 3, six times in a row! This might be a fluke, or maybe there’s something deeper going on.
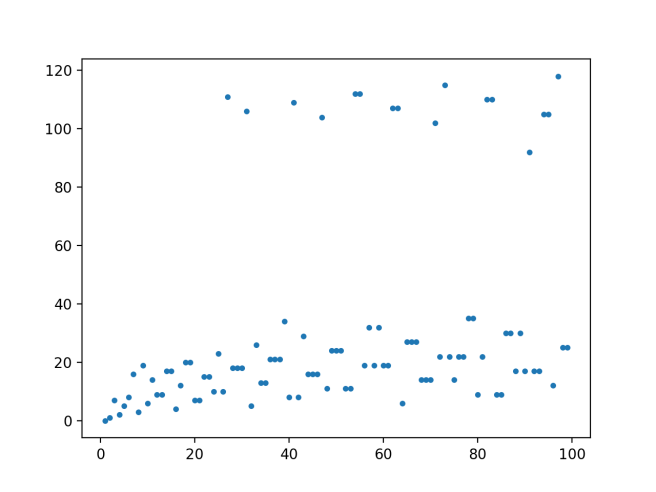
Also, I’m sure you’re curious about that one record-breaker that jumps way above the previous record-breakers. It turns out that you’ve already seen it: it’s 27!
27 is unique in just how much it exceeds all the previous records, going from 23 to 111 (increasing the record by 89). As you can see in the graph, no other record-breaker beats its previous records by nearly as much, even though we’re looking all the way up to 100,000. Perhaps this is just a fluke caused by the early records being especially low? This seems supported by the fact that if we look all the way up to 10 million, we still see that nothing beats 27.
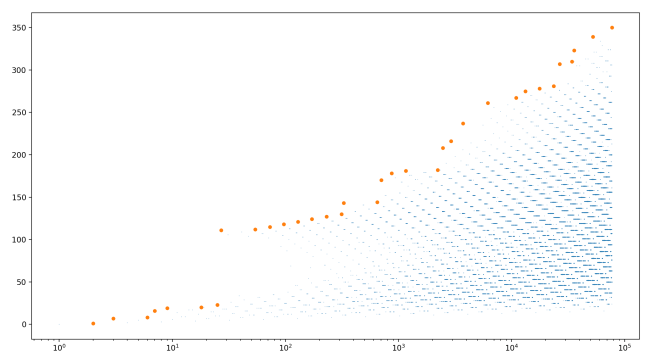
Define a record-breaking record-breaker as a record-breaker that beats the previous record by a greater amount than all previous record breakers. Now, 27 is clearly a record-breaking record-breaker. There is also one before it, namely 3, which beats the previous record by 6. (7 is a record-tying record-breaker, as it also beats the previous record by 6.)
We might have a postulate in mind: 3 and 27 are the only record-breaking record-breakers. Can we prove this?
Well, it turns out that we can’t. Because the postulate is not true! Let’s extend our graph by another factor of 10, going up to 100 million. (By the way, the dynamic programming I mentioned earlier is absolutely essential at this point for any of this to be possible.)
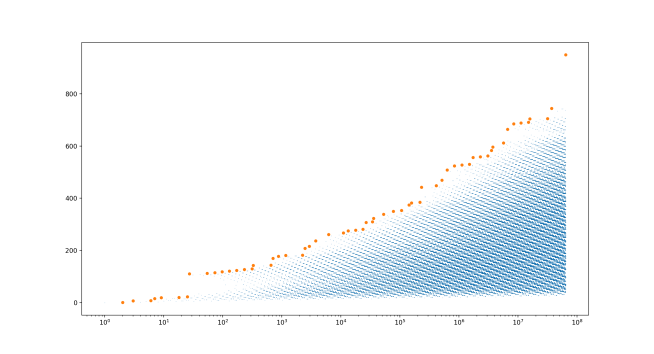
Now we can see that in fact there is another record-breaking record-breaker, all the way over to the right side of the graph! It turns out to be 63,728,127, and it beats the previous record by 205! So 27 is apparently not the largest one. A new question that naturally arises, a question to which I have no answer, is: are there infinitely many record-breaking record-breakers? Or does the sequence end at some point? I conjecture that yes, there are infinitely many such overachievers.
I have two more things to geek out about before I finish up. First of all, take a look at the actual values of the record-breakers up to 10000:
2: 1
3: 7
6: 8
7: 16
9: 19
18: 20
25: 23
27: 111
54: 112
73: 115
97: 118
129: 121
171: 124
231: 127
313: 130
327: 143
649: 144
703: 170
871: 178
1161: 181
2223: 182
2463: 208
2919: 216
3711: 237
6171: 261
10971: 267
13255: 275
17647: 278
23529: 281
26623: 307
34239: 310
35655: 323
52527: 339
77031: 350
If you skim this list over, you’ll notice that these record-breakers appear to all be odd. But there are in fact four exceptions in this list that appear near its beginning: 2, 6, 18, and 54. And after these four, the even record-breakers appear to disappear. This sort of makes sense; if the first thing you do with your number is make it larger, this will in general result in a longer chain. But are there any more even record breakers larger than 54?
As it turns out, yes there are! But the next even record breaker doesn’t appear until we get into the tens of millions. It is 31,466,382. This is pretty baffling! Try showing your friends the sequence [2, 6, 18, 54, 31466382] and see if they can figure out what comes next! (It turns out that the next number is 127,456,254, which is exactly twice the previous record breaker!)
And now one final observation. There seem to be disproportionately many record-breakers whose chain lengths differ by only 1 or 3. For the heck of it, let’s define shiftless record-breakers as any record breakers who only beat the previous record by 3, and lazy record-breakers as any record-breakers who beat the previous record by 1.
One simple way this might happen is if the previous record breaker is N, and there are no new record breakers up to 2N. Then 2N will be the new record breaker, since its first step will be dividing by 2, and then it will take the rest of Ns chain for itself. So its chain length will be one larger than the chain length of N. (By the way, it turns out that our large even record breaker is in fact an example of a lazy record breaker.)
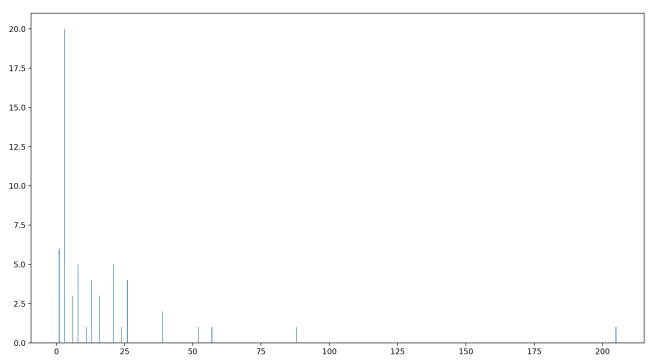
Are there really disproportionately many lazy and shiftless record breakers? Let’s look at the amount that each record breaker beat its previous record breaker by. This sequence looks like:
6, 1, 8, 3, 1, 3, 88, 1, 3, 3, 3, 3, 3, 3, 13, 1, 26, 8, 3, 1, 26, 8, 21, 24, 6, 8, 3, 3, 26, 3, 13, 16, 11, 3, 21, 8, 3, 57, 6, 21, 39, 16, 3, 3, 26, 3, 3, 21, 13, 16, 52, 21, 3, 3, 13, 1, 39, 205
This is another really mind-blowing observation for me! It looks like the differences between record breakers always seem to take on only very specific values, like 1, 3, 6, 8, and 11. Is there ever a difference of 2? or 5? I have no idea, and I’d love to know! I’ve leave you with this histogram showing how often each difference appears in all record-breakers up to 100 million: