IQ is an increasingly controversial topic these days. I find that when it comes up, different people seem to be extremely confident in wildly different beliefs about the nature of IQ as a measure of intelligence.
Part of this has to do with education. This paper analyzed the top 29 most used introductory psychology textbooks and “found that 79.3% of textbooks contained inaccurate statements and 79.3% had logical fallacies in their sections about intelligence.” [1]
This is pretty insane, and sounds kinda like something you’d hear from an Alex Jones-style conspiracy theorist. But if you look at what the world’s experts on human intelligence say about public opinion on intelligence, they’re all in agreement: misinformation about IQ is everywhere. It’s gotten to the point where world-famous respected psychologists like Steven Pinker are being blasted as racists in articles in mainstream news outlets for citing basic points of consensus in the scientific literature.
The reasons for this are pretty clear… people are worried about nasty social and political implications of true facts about IQ. There are worthwhile points to be made about morally hazardous beliefs and the possibility that some truths should not be publicly known. At the same time, the quantification and study of human intelligence is absurdly important. The difference between us and the rest of the animal world, the types of possible futures that are open to us as a civilization, the ability to understand the structure of the universe and manipulate it to our ends; these are the types of things that the subject of human intelligence touches on. In short, intelligence is how we accomplish anything as a civilization, and the prospect of missing out on ways to reliably intervene and enhance it because we avoided or covered up research that revealed some inconvenient truths seems really bad to me.
Overall, I lean towards thinking that the misinformation is so great, and the truth so important, that it’s worthwhile to attempt to clear things up. So! The purpose of this post is just to sort through some of the mess and come up with a concise and referenced list of some of the most important things we know about IQ and intelligence.
IQ Basics
- The most replicated finding in all of psychology is that good performance on virtually all cognitively demanding tasks is positively correlated. The name for whatever cognitive faculty causes this correlation is “general intelligence”, or g.
- A definition of intelligence from 52 prominent intelligence researchers: [2]
Intelligence is a very general capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test‑taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings—‘catching on’, ‘making sense’ of things, or ‘figuring out’ what to do. Intelligence, so defined, can be measured, and intelligence tests measure it well.
- IQ tests are among the most reliable and valid of all psychological tests and assessments. [3]
- They are designed to test general intelligence, and not character or personality.
- Modern IQ tests have a standard error of measurement of about 3 points.
- The distribution of IQs in a population nicely fits a Bell curve.
- IQ is defined in such a way as to make the population mean exactly 100, and the standard deviation 15.
- People with high IQs tend to be healthier, wealthier, live longer, and have more successful careers. [4][5][6]
- IQ is highly predictive of educational aptitude and job performance. [7][8][9][10][11]
- Longitudinal studies have shown that IQ “is a causal influence on future achievement measures whereas achievement measures do not substantially influence future IQ scores.” [12]
Average adult combined IQs associated with real-life accomplishments by various tests
| Accomplishment |
IQ |
| MDs, JDs, and PhDs |
125 |
| College Graduates |
115 |
| 1–3 years of college |
104 |
| Clerical and sales workers |
100–105 |
| High school graduates, skilled workers (e.g., electricians, cabinetmakers) |
97 |
| 1–3 years of high school (completed 9–11 years of school) |
94 |
| Semi-skilled workers (e.g. truck drivers, factory workers) |
90–95 |
| Elementary school graduates (completed eighth grade) |
90 |
| Elementary school dropouts (completed 0–7 years of school) |
80–85 |
| Have 50/50 chance of reaching high school |
75 |
(table from Wiki)
(from Gwern)
Nature of g
- IQ scores are very stable across lifetime. [13]
- This doesn’t mean that 30-year-old you is no smarter than 10-year-old you. It means that if you test the IQ of a bunch of children, and then later test them as adults, the rank order will remain roughly the same. A smarter-than-average 10 year old becomes a smarter-than-average 30 year old.
- After your mid-20s, crystallized intelligence plateaus and fluid intelligence starts declining. Obligatory terrifying graph: (source)
/cdn.vox-cdn.com/uploads/chorus_asset/file/6530521/Screen%20Shot%202016-05-23%20at%209.07.16%20AM.png)
- High IQ is correlated with more gray matter in the brain, larger frontal lobes, and a thicker cortex. [14][15]
- “There is a constant cascade of information being processed in the entire brain, but intelligence seems related to an efficient use of relatively few structures, where the more gray matter the better.” [16]
- “Estimates of how much of the total variance in general intelligence can be attributed to genetic influences range from 30 to 80%.” [17]
- Twin studies show the same results; there are substantial genetic influences on human intelligence. [18]
- The genetic component of IQ is highly polygenic, and no specific genes have been robustly associated with human intelligence. The best we’ve found so far is a single gene that accounts for 0.1% of the variance in IQ. [17]
- Many genes have been weakly associated with IQ. “40% of the variation in crystallized-type intelligence and 51% of the variation in fluid-type intelligence between individuals” is accounted for by genetic differences. [19]
- Scientists can predict your IQ by looking only at your genes (not perfectly, but significantly better than random). [19]
- This study analyzed 549,692 base pairs and found a R = .11 mean correlation between their predictions and the actual fluid intelligence of over 3500 unrelated adults. [19]
You might be wondering at this point what all the controversy regarding IQ is about. Why are so many people eager to dismiss IQ as a valid measure of intelligence? Well, we now dive straight into the heart of the controversy: intergroup variation in IQ.
It’s worth noting that, as Scott Alexander puts it: society is fixed, while biology is mutable. This fear we have that if biology factors into the underperformance of some groups, then such difference are intrinsically unalterable, makes little sense. We can do things to modify biology just as we can do things to modify society, and in fact the first is often much easier to do and more effective than the easier.
Anyway, prelude aside, we dive into the controversy.
Group differences in IQ
- Yes, there are racial differences in IQ, both globally and within the United States. This has been studied to death, and is a universal consensus; you won’t find a single paper in a reputable psychology journal denying the numerical differences. [20]
- Within the United States, there is a long-standing 1 SD (15 to 18 point) IQ difference between African Americans and White Americans. [2]
- The tests in which these differences are most pronounced are those that most closely correspond to g, like Raven’s Progressive Matrices. [6] This test also is free of culturally-loaded knowledge, and only requires being able to solve visual pattern-recognition puzzles like these ones:
- Controlling for the way the tests are formulated and administered does not affect this difference. [2]
- IQ scores predict success equally accurately regardless of race or social class. This provides some evidence that the test is not culturally biased as a predictor. [2] [19]
- Internationally, the lowest average IQs are found in sub-Saharan Africa and the highest average IQs are found in East Asia. The variations span a range of three standard deviations (45 IQ points). [21]
- Malawi has an estimated average IQ of 60.
- Singapore and Hong Kong have estimated IQs around 108.

(image from here)
- A large survey published in one of the top psychology journals polled over 250 experts on IQ and international intelligence differences. [21]
- On possible causes of cross-national differences in cognitive ability: “Genes were rated as the most important cause (17%), followed by educational quality (11.44%), health (10.88%), and educational quantity (10.20%).”
- “Around 90% of experts believed that genes had at least some influence on cross-national differences in cognitive ability.”
- Men and women have equal average IQs.
- But: “most IQ tests are constructed so that there are no overall score differences between females and males.” [6]
- They do this by removing items that show significant sex differences. So, for instance, men have a 1 SD (15 point) advantage on visual-spatial tasks over women. Thus mental rotation tests have been removed, in order to reduce the perception of bias. [22]
- Males also do better on proportional and mechanical reasoning and mathematics, while females do better on verbal tests. [22]
- Hormones are thought to play a role in sex differences in cognitive abilities. [23]
- Females that are exposed to male hormones in utero have higher spatiotemporal reasoning scores than females that are not. [24]
- The same thing is seen with men that have higher testosterone levels, and older males given testosterone. [25]
- There is also some evidence of men having a higher IQ variance than women, but this seems to be disputed. If true, it would indicate more men at the very bottom and the very top of the IQ scale (helping to explain sex disparities in high-IQ professions). [26]
IQ Trends
- In the developed world, average IQ has been increasing by 2 to 3 points per decade since 1930. This is called the Flynn effect.
- The average IQ in the US in 1932, as measured by a 1997 IQ test, would be around 80. People with IQ 80 and below correspond to the bottom 9% of the 1997 population. [27]
- Some studies have found that the Flynn effect seems to be waning in the developing world, and beginning in the developing world. [28]
- A large survey of experts found that most attribute the Flynn effect to “better health and nutrition, more and better education and rising standards of living.” [29]
- The Flynn effect is not limited to IQ tests, but is also found in memory tests, object naming, and other commonly used neuropsychological tests. [30]
- Many studies indicate that the black-white IQ gap in the United States is closing. [23]
Can IQ be increased?
- There are not any known interventions to reliably cause long term increases (although decreasing it is easy).
- Essentially, you can do a handful of things to ensure that your child’s IQ is not low (give them access to education, provide them good nutrition, prevent iodine deficiency, etc), but you can’t do much beyond these.
- Educational intervention programs have fairly unanimously failed to show long-term increases in IQ in the developed world. [23]
- The best prekindergarten programs have a substantial short-term effect on IQ, but this effect fades by late elementary school.
Random curiosities
- Several large-scale longitudinal studies have found that children with higher IQ are more likely to have used illegal drugs by middle age. This association is stronger for women than men. [31][32]
- This actually makes some sense, given that IQ is positively correlated with Openness (in the Big Five personality traits breakdown).
- The average intelligence of Marines has been significantly declining since 1980. [33]
- “The US military has minimum enlistment standards at about the IQ 85 level. There have been two experiments with lowering this to 80 but in both cases these men could not master soldiering well enough to justify their costs.” (from Wiki)
- This is fairly terrifying when you consider that 10% of the US population has an IQ of 80 or below; evidently, this enormous segment of humanity has an extremely limited capacity to do useful work for society.
- Researchers used to think that IQ declined significantly starting around age 20. Subsequently this was found to be mostly a product of the Flynn effect: as average IQ increases, the normed IQ value inflates, so a constant IQ looks like it decreases. (from Wiki)
- The popular idea that listening to classical music increases IQ has not been borne out by research. (Wiki)
- There’s evidence that intelligence is part of the explanation for differential health outcomes across socioeconomic class.
- “…Health workers can diagnose and treat incubating problems, such as high blood pressure or diabetes, but only when people seek preventive screening and follow treatment regimens. Many do not. In fact, perhaps a third of all prescription medications are taken in a manner that jeopardizes the patient’s health. Non-adherence to prescribed treatment regimens doubles the risk of death among heart patients (Gallagher, Viscoli, & Horwitz, 1993). For better or worse, people are substantially their own primary health care providers.”
“For instance, one study (Williams et al., 1995) found that, overall, 26% of the outpatients at two urban hospitals were unable to determine from an appointment slip when their next appointment was scheduled, and 42% did not understand directions for taking medicine on an empty stomach. The percentages specifically among outpatients with inadequate
literacy were worse: 40% and 65%, respectively. In comparison, the percentages were 5% and 24% among outpatients with adequate
literacy. In another study (Williams, Baker, Parker, & Nurss, 1998), many insulin-dependent diabetics did not understand fundamental facts for maintaining daily control of their disease: Among those classified as having inadequate literacy, about half did not know the signs of very low or very high blood sugar, and 60% did not know the corrective actions they needed to take if their blood sugar was too low or too high. Among diabetics, intelligence at time of diagnosis correlates significantly (.36) with diabetes knowledge measured 1 year later (Taylor, Frier, et al., 2003).” [34]
- IQ differences might be able to account for a significant portion of global income inequality.
- “… in a conventional Ramsey model, between one-fourth and one-half of income differences across countries can be explained by a single factor: The steady-state effect of large, persistent differences in national average IQ on worker productivity. These differences in cognitive ability – which are well-supported in the psychology literature – are likely to be malleable through better nutrition, better education, and better health care in the world’s poorest countries. A simple calibration exercise in the spirit of Bils and Klenow (AER, 2000) and Castro (Rev. Ec. Dyn., 2005) is conducted. According to the model, a move from the bottom decile of the global IQ distribution to the top decile will cause steady-state living standards to rise by between 75 and 350 percent. I provide evidence that little of IQ-productivity relationship is likely to be due to reverse causality.” [35]
- Exposure to lead hampers cognitive development and lowers IQ. You can calculate the economic boost the US received as a result of the dramatic reduction in children’s exposure to lead since the 1970s and the resulting increase in IQs.
- “The base-case estimate of $213 billion in economic benefit for each cohort is based on conservative assumptions about both the effect of IQ on earnings and the effect of lead on IQ.” [36]
- Yes. $213 billion.
- In a 113-country analysis, IQ has been found to positively affect all main measures of institutional quality.
- “The results show that average IQ positively affects all the measures of institutional quality considered in our study, namely government efficiency, regulatory quality, rule of law, political stability and voice and accountability. The positive effect of intelligence is robust to controlling for other determinants of institutional quality.” [37]
- High IQ people cooperate more in repeated prisoner’s experiments; 5% to 8% more cooperation per 100 point increase in SAT score (7 pt IQ increase). [38][39]
- The second paper also shows more patience and higher savings rates for higher IQ. [39]
- Embryo selection is a possible way to enhance the IQ of future generations, and is already technologically feasible.
- “Biomedical research into human stem cell-derived gametes may enable iterated embryo selection (IES) in vitro, compressing multiple generations of selection into a few years or less.” [40]
| 1 in 2 |
4.2 |
| 1 in 10 |
11.5 |
| 1 in 100 |
18.8 |
| 1 in 1000 |
24.3 |
Sources
There is a ridiculous amount of research out there on IQ, and you can easily reach any conclusion you want by just finding some studies that agree with you. I’ve tried to stick to relying on large meta-analyses, papers of historical significance, large surveys of experts, and summaries by experts of consensus views.
[1] Warne, R. T., Astle, M. C., & Hill, J. C. (2018). What Do Undergraduates Learn About Human Intelligence? An Analysis of Introductory Psychology Textbooks. Archives of Scientific Psychology, 6(1), 32-50.
[2] Gottfredson, L. S. (1997). Mainstream science on intelligence: An editorial with 52 signatories, history and bibliography. Intelligence, 24(1), 13-23.
[3] Colom, R. (2004). Intelligence Assessment. Encyclopedia of Applied Psychology, 2(2), 307–314.
[4] Batty, D. G., Deary, I. J,, Gottfredson, L. S. (2007). Premorbid (early life) IQ and Later Mortality Risk: Systematic Review. Annals of Epidemiology, 17(4), 278–288.
[5] Gottfredson, L. S. (1997). Why g Matters: The Complexity of Everyday Life. Intelligence, 24(1), 79-132.
[6] Neisser, U, et al. (1996). Intelligence: Knowns and Unknowns. American Psychological Association. American Psychologist, 51(2), 77-101.
[7] Deary, I. J., et al. (2007). Intelligence and educational achievement. Intelligence, 35(1), 13-21.
[8] Dumfart, B., & Neubauer, A. C. (2016). Conscientiousness is the most powerful noncognitive predictor of school achievement in adolescents. Journal of Individual Differences, 37(1), 8-15.
[9] Kuncel, N. R., & Hezlett, S. A. (2010). Fact and Fiction in Cognitive Ability Testing for Admissions and Hiring Decisions. Current Directions in Psychological Science, 19(6), 339-345.
[10] Schmidt, F. L., Hunter, J. E. (1998). The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 85 Years of Research Findings. Psychological Bulletin, 124(2), 262-274.
[11] Hunter, J. E., & Hunter, R. F. (1984). Validity and utility of alternative predictors of job performance. Psychological Bulletin, 96(1), 72-98.
[12] Watkins, M. W., Lei, P., Canivez, G. L. (2007). Psychometric intelligence and achievement: A cross-lagged panel analysis. Intelligence, 35(1), 59-68.
[13] Deary, I. J., et al. (2000). The stability of individual differences in mental ability from childhood to old age: follow-up of the 1932 Scottish Mental Survey. Intelligence, 28(1), 49–55.
[14] Frangou, S., Chitins, X., Williams, S. C. R. (2004). Mapping IQ and gray matter density in healthy young people. NeuroImage, 23(3), 800-805.
[16] Narr, K., et al. (2007). Relationships between IQ and Regional Cortical Gray Matter Thickness in Healthy Adults. Cerebral Cortex, 17(9), 2163–2171.
[15] University Of California – Irvine. “Human Intelligence Determined By Volume And Location Of Gray Matter Tissue In Brain.” ScienceDaily, 20 July 2004.
[17] Deary, I. J., Penke, L., Johnson, W. (2010) The neuroscience of human intelligence differences. Nature Reviews Neuroscience, 11(3), 201–211.
[18] Deary, I. J., Johnson, W., Houlihan, L. M. (2009). Genetic foundations of human intelligence. Human Genetics, 126(1), 215-232.
[19] Davies, G., et al. (2011). Genome-wide association studies establish that human intelligence is highly heritable and polygenic. Mol Psychiatry, 16(10), 996–1005.
[20] Rushton, J. P., Jensen, A. R. (2005). Thirty Years of Research on Race Differences in Cognitive Ability. Psychology, Public Policy, 11(2), 235-294.
[21] Rindermann, H., Becker, D., Coyle, T. R. (2016). Survey of Expert Opinion on Intelligence: Causes of International Differences in Cognitive Ability Tests. Frontiers in Psychology, 7.
[22] Ellis, L., et al. (2008). Sex Differences: Summarizing More than a Century of Scientific Research. Psychology Press.
[23] Nisbett, R. E., et al. (2012). Intelligence: New Findings and Theoretical Developments. American Psychologist, 67(2), 129.
[24] Resnick, S. M., et al. (1986). Early hormonal influences on cognitive functioning in congenital adrenal hyperplasia. Developmental Psychology, 22(2), 191-198.
[25] Janowsky, J. S., Oviatt, S. K., Orwoll, E. S. (1994) Testosterone influences spatial cognition in older men. Behavioral Neuroscience, 108(2), 325-332.
[26] Lynn, R., Kanazawa, S. (2011). A longitudinal study of sex differences in intelligence at ages 7, 11 and 16 years. Personality and Individual Differences, 51(3), 321–324.
[27] Neisser, U. (1997). Rising Scores on Intelligence Tests. American Scientist, 85(5), 440-447.
[28] Pietschnig, J., Voracek, M. (2015). One Century of Global IQ Gains: A Formal Meta-Analysis of the Flynn Effect (1909-2013). Perspectives on Psychological Science, 10(3), 282-306.
[29] Rindermann, H., Becker, D., Coyle, T. R. (2017). Survey of expert opinion on intelligence: The Flynn effect and the future of intelligence. Personality and Individual Differences, 106, 242-247.
[30] Trahan, L. H., et al. (2014). The Flynn Effect: A Meta-analysis. Psychological Bulletin, 140(5), 1332-1360.
[31] White, J., Gale, C. R., Batty, D. G. (2012). Intelligence quotient in childhood and the risk of illegal drug use in middle-age: the 1958 National Child Development Survey. Annals of Epidemiology, 22(9), 654-657.
[32] White, J., Batty, D. G. (2011). Intelligence across childhood in relation to illegal drug use in adulthood: 1970 British Cohort Study. Journal of Epidemiology & Community Health, 66(9).
[33] Cancian, M. F., Klein, M. W. (2015). Military Officer Quality in the All-Volunteer Force. National Bureau of Economic Research, WP 21372.
[34] Gottfredson, L.S. (2004). Intelligence: Is it the epidemiologists’ elusive fundamental cause of social class inequalities in health?
. Journal of Personality and Social Psychology, 86(1), 174-199.
[35] Jones, G. (2005). IQ in the Ramsey Model: A Naive Calibration. George Mason University.
[36] Grosse, S. D., et al. (2002). Economic Gains Resulting from the Reduction in Children’s Exposure to Lead in the United States. Environmental Health Perspectives, 110(6), 563-569.
[37] Kalonda-Kanyama, I. & Kodila-Tedika, O. (2012). Quality of Institutions: Does Intelligence Matter?. Working Papers Series in Theoretical and Applied Economics 201206, University of Kansas, Department of Economics.
[38] Jones, G. (2008). Are Smarter Groups More Cooperative? Evidence from Prisoner’s Dilemma Experiments, 1959-2003. Journal of Economic Behavior & Organization 68(3–4), 489-497.
[39] Jones, G. (2011). National IQ and National Productivity: The Hive Mind Across Asia. Asian Development Review, 28(1), 51-71.
[40] Shulman, C. & Bostrom, N. (2014). Embryo Selection for Cognitive Enhancement: Curiosity or Game-changer?. Global Policy 5(1), 85-92.














 . The total amount of product on the market will be given the label
. The total amount of product on the market will be given the label 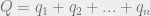 . Since the firms are all selling identical products, it makes sense to assume that the consumer demand function
. Since the firms are all selling identical products, it makes sense to assume that the consumer demand function  will just be a function of the total quantity of the product that is on the market:
will just be a function of the total quantity of the product that is on the market: 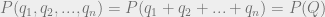 . (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)
. (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)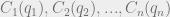 . Now we can figure out the profit of each firm for a given set of output values
. Now we can figure out the profit of each firm for a given set of output values  . This profit is just the amount of money they get by selling the product minus the cost of producing the product:
. This profit is just the amount of money they get by selling the product minus the cost of producing the product:  .
. . This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms!
. This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms! and
and 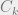 , we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.
, we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.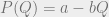 (for some a and b) and
(for some a and b) and  . As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
. As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
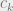 represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.)
represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.) . Rewriting, we get
. Rewriting, we get  . We can’t immediately solve this for
. We can’t immediately solve this for  , because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!
, because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!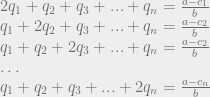



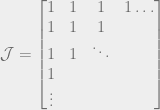



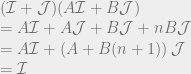


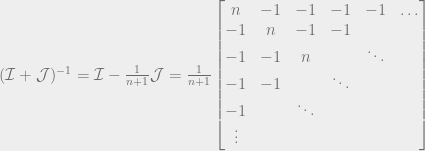
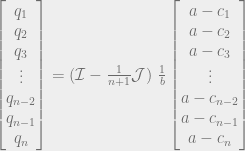
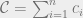
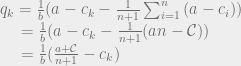
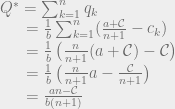
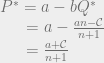



 intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity
intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity  , the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
, the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
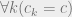

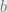 ) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!
) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!





