Op-amps are magical little devices that allow us to employ the laws of electromagnetism for our purposes, giving us the power to do ultimately any computation using physics. To explain this, we need to take three steps: first transistors, then differential amplifiers, and then operational amplifiers. The focus of this post will be on purely analog calculations, as that turns out to be the most natural type of computation you get out of op amps.
1. Transistor
Here’s a transistor:
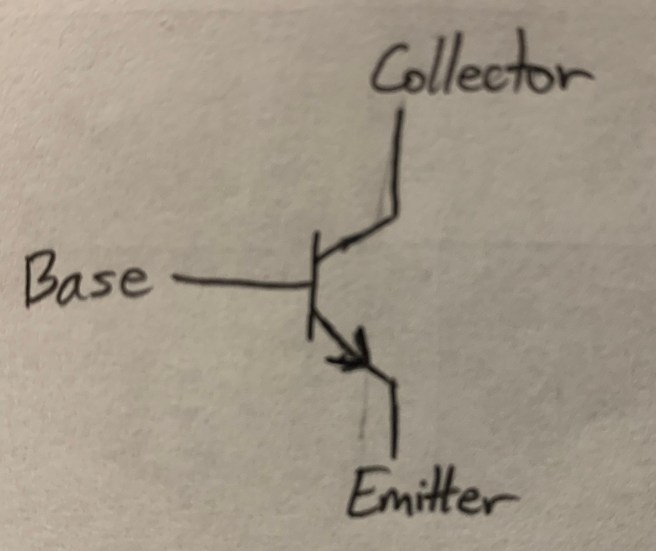
It has three ports, named (as labelled) the base, the collector and the emitter. Intuitively, you can think about the base as being like a dial that sensitively controls the flow of large quantities of current from the collector to the emitter. This is done with only very small trickles of current flowing into the base.
More precisely, a transistor obeys the following rules:
- The transistor is ON if the voltage at the collector is higher than the voltage at the emitter. It is OFF otherwise.
- When the transistor is in the ON state, which is all we’ll be interested in, the following regularities are observed:
- Current flows along only two paths: base-to-emitter and collector-to-emitter. A transistor does not allow current to flow from the emitter to either the collector or the base.
- The current into the collector is proportional to the current into the base, with a constant of proportionality labelled β whose value is determined by the make of the transistor. β is typically quite large, so that the current into the collector is much larger than the current into the base.
- The voltage at the emitter is 0.6V less than the voltage at the base.

Combined, these rules allow us to solve basic transistor circuits. Here’s a basic circuit that amplifies input voltages using a transistor:

Applying the above rules, we derive the following relationship between the input and output voltages:

The +15V port at the top is important for the functioning of the amplifier because of the first rule of transistors, regarding when they are ON and OFF. If we just had it grounded, then the voltage at the collector would be negative (after the voltage drop from the resistor), so the transistor would switch off. Having the voltage start at +15V allows VC to be positive even after the voltage drop at the resistor (although it does set an upper bound on the input currents for which the circuit will still operate).
And the end result is that any change in the input voltage will result in a corresponding change in the output voltage, amplified by a factor of approximately -RC/RE. Why do we call this amplification? Well, because we can choose whatever values of resistance for RC and RE that we want! So we can make RC a thousand times larger than RE, and we have created an amplifier that takes millivolt signals to volt signals. (The amplification tops out at +15V, because a signal larger than that would result in the collector voltage going negative and the transistor turning off.)
Ok, great, now you’re a master of transistor circuits! We move on to Step 2: the differential amplifier.
2. Differential Amplifier
A differential amplifier is a circuit that amplifies the difference between two voltages and suppresses the commonalities. Here’s how to construct a differential amplifier from two transistors:

Let’s solve this circuit explicitly:
Vin = 0.6 + REiE+ Rf (iE+ iE’)
Vin’ = 0.6 + REiE’ + Rf (iE+ iE’)
∆(Vin – Vin’) = RE(iE – iE’) = RE (β+1)(iB – iB’)
∆(Vin + Vin’) = (RE + 2Rf)(iE + iE’) = (RE + 2Rf)(β+1)(iB + iB’)
Vout = 15 – RC iC
Vout’ = 15 – RC iC’
∆(Vout – Vout’) = – RC(iC – iC’) = – RC β (iB– iB’)
∆(Vout + Vout’) = – RC(iC + iC’) = – RC β (iB + iB’)
ADM = Differential Amplification = ∆(Vout – Vout’) / ∆(Vin – Vin’) = -β/(β+1) RC/RE
ACM = “Common Mode” Amplification = ∆(Vout + Vout’) / ∆(Vin + Vin’) = -β/(β+1) RC/(RE + 2Rf)
We can solve this directly for changes in one particular output voltage:
∆Vout = ADM ∆(Vin – Vin‘) + ACM ∆(Vin + Vin‘)
To make a differential amplifier, we require that ADM be large and ACM be small. We can achieve this if Rf >> RC >> RC. Notice that since the amplification is a function of the ratio of our resistors, we can easily make the amplification absolutely enormous.
Here’s one way this might be useful: say that Alice wants to send a signal to Bob over some distance, but there is a source of macroscopic noise along the wire connecting the two. Perhaps the wire happens to pass through a region in which large magnetic disturbances sometimes occur. If the signal is encoded in a time-varying voltage on Alice’s end, then what Bob gets may end up being a very warped version of what Alice sent.
But suppose that instead Alice sends Bob two signals, one with the original message and the other just a static fixed voltage. Now the difference between the two signals represents Alice’s message. And crucially, if these two signals are sent on wires that are right side-by-side, then they will pick up the same noise!
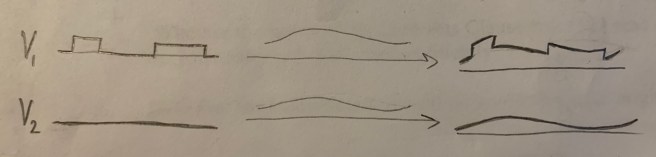
This means that while the original message will be warped, so will the static signal, and by roughly the same amount! Which means that the difference between the two signals will still carry the information of the original message. This allows Alice to communicate with Bob through the noise, so long as Bob takes the two wires on his end and plugs them into a differential amplifier to suppress the common noise factor.
3. Operational Amplifier
To make an operational amplifier, we just need to make some very slight modifications to our differential amplifier. The first is that we’ll make our amplification as large as possible. We can get this by putting multiple stages of differential amplifiers side by side (so if your differential amplifier amplifies by 100, two of them will amplify by 10,000, and three by 1,000,000).
What’ll happen now if we send in two voltages, with Vin very slightly larger than Vin‘? Well, suppose that the difference is on the order of a single millivolt (mV). Then the output voltage will be on the order of 1 mV multiplied by our amplication factor of 1,000,000. This will be around 1000V. So… do we expect to get out an output signal of 1000V? No, clearly not, because our maximum possible voltage at the output is +15V! We can’t create energy from nowhere. Remember that the output voltage Vout is equal to 15V – RCiC, and that the transistor only accepts current traveling from the collector to the emitter, not the other way around. This means that iC cannot be negative, so Vout cannot be larger that +15V. In addition, we know that Vout cannot be smaller than 0V (as this would turn off the transistor via Rule 1 above).
What this all means is that if Vin is even the slightest bit smaller than Vin‘, Vout will “max out”, jumping to the peak voltage of +15V (remember that ADM is negative). And similarly, if Vin is even the slightest bit larger than Vin‘, then Vout will bottom out, dropping to 0V. The incredible sensitivity of the instrument is given to us by the massive amplification factor, so that it will act as a binary measurement of which of the voltages is larger, even if that difference is just barely detectable. Often, the bottom voltage will be set to -15V rather than ground (0V), so that the signal we get out is either +15V (if Vin is smaller than Vin‘) or -15V (if Vin is greater than Vin‘). That way, perfect equality of the inputs will be represented as 0V. That’s the convention we’ll use for the rest of the post. Also, instead of drawing out the whole diagram for this modified differential amplifier, we will use the following simpler image:

Ok, we’re almost to an operational amplifier. The final step is to apply negative feedback!

What we’re doing here is just connecting the output voltage to the Vin‘ input. Let’s think about what this does. Suppose that Vin is larger than Vin‘. Then Vout will quickly become negative, approaching -15V. But as Vout decreases, so does Vin‘! So Vin‘ will decrease, getting closer to Vin. Once it passes Vin, the quantity Vin – Vin‘ suddenly becomes negative, so Vout will change direction, becoming more positive and approaching +15V. So Vin‘ will begin to increase! This will continue until it passes Vin again, at which point Vout will change signs again and Vin‘ will start decreasing. The result of this process will be that no matter what Vin‘ starts out as, it will quickly adjust to match Vin to a degree dictated by the resolution of our amplifier. And we’ve already established that the amplifier can be made to have an extremely high resolution. So this device serves as an extremely precise voltage-matcher!
This device, a super-sensitive differential amplifier with negative feedback, is an example of an operational amplifier. It might not be immediately obvious to you what’s so interesting or powerful about this device. Sure it’s very precise, but all it does is match voltages. How can we leverage this to get actually interesting computational behavior? Well, that’s the most fun part!
4. Let’s Compute!
Let’s start out by seeing how an op-amp can be used to do calculus. Though this might seem like an unusually complicated starting place, doing calculus with op amps is significantly easier and simpler than doing something like multiplication.
As we saw in the last section, if we simply place a wire between Vout and Vin‘ (the input labelled with a negative sign on the diagram), then we get a voltage matcher. We get more interesting behavior if we place other circuit components along this wire. The negative feedback still exists, which means that the circuit will ultimately stabilize to a state in which the two inputs are identical, and where no current is flowing into the op-amp. But now the output voltage will not just be zero.
Let’s take a look at the following op-amp circuit:

Notice that we still have negative feedback, because the V– input is connected to the output, albeit not directly. This means that the two inputs to the op amp must be equal, and since V+ is grounded, the other must be at 0V as well. It also means that no current is flowing into the op amp, as current only flows in while the system is stabilizing.
Those two pieces of information – that the input voltages are equal and that no current flows through the device – are enough to allow us to solve the circuit.
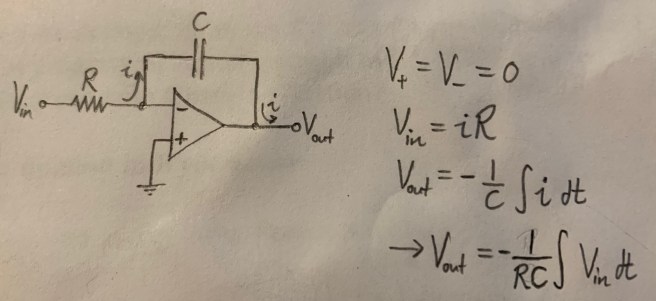
And there we have it, a circuit that takes in a voltage function that changes with time and outputs the integral of this function! A natural question might be “integral from what to what”? The answer is just: the integral from the moment the circuit is connected to the present! As soon as the circuit is connected it begins integrating.
Alright, now let’s just switch the capacitor and resistor in the circuit:

See if you can figure out for yourself what this circuit does!
…
…
Alright, here’s the solution.

We have a differentiator! Feed in some input voltage, and you will get out a precise measurement of the rate of change of this voltage!
I find it pretty amazing that doing integration and differentiation is so simple and natural. Addition is another easy one:
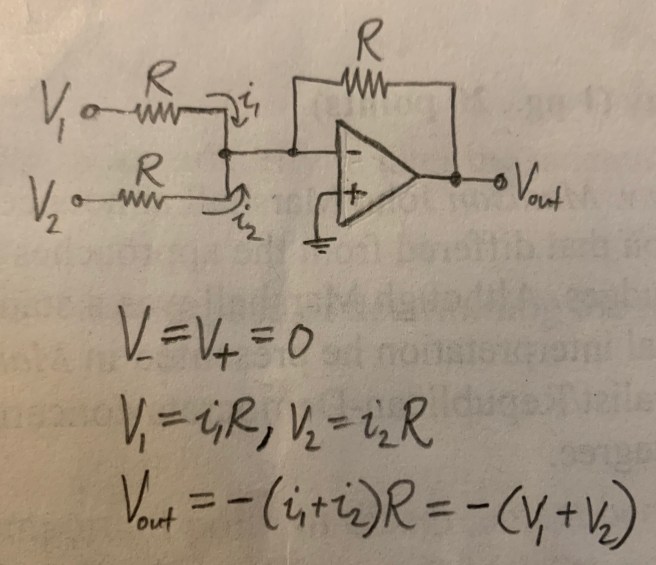
We can use diodes to produce exponential and logarithm calculators. We utilize the ideal diode equation:
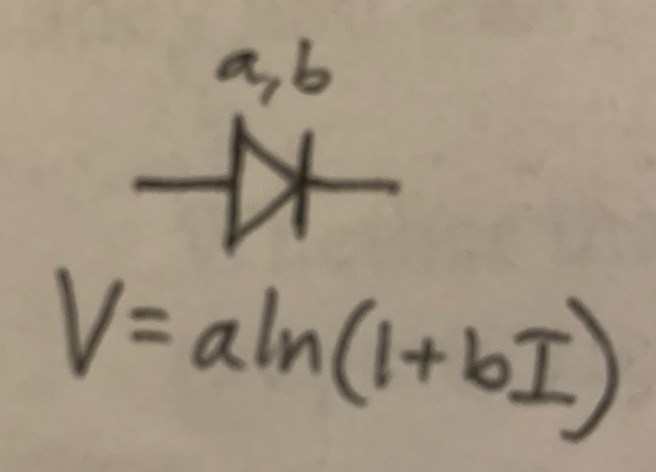
The logarithm can now be used to produce circuits for calculating exponentials and logarithms:
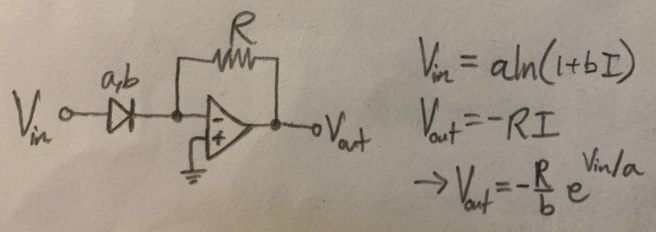
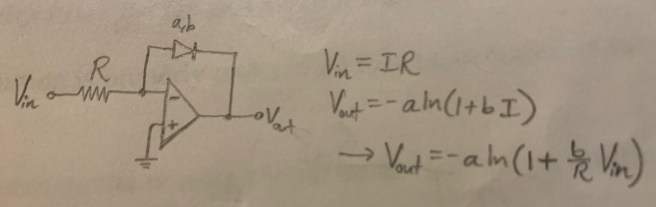
Again, these are all fairly simple-looking circuits. But now let’s look at the simplest way of computing multiplication using an op amp. Schematically, it looks like this:

And here’s the circuit in full detail:
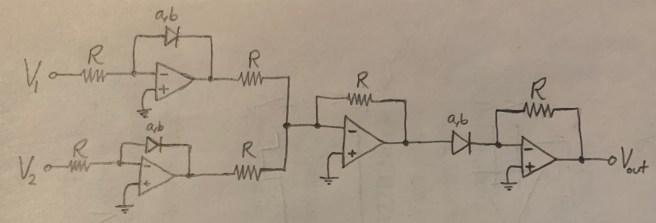
There’s another method besides this one that you can use to do multiplication, but it’s similarly complicated. It’s quite intriguing that multiplication turns out to be such an unnatural thing to get nature to do to voltages, while addition, exponentiation, integration, and the rest are so simple.
What about boolean logic? Well, it turns out that we already have a lot of it. Our addition corresponds to an OR gate if the input voltages are binary signals. We also already have an AND gate, because we have multiplication! And depending on our choice of logic levels (which voltage corresponds to True and which corresponds to False), we can really easily sketch a circuit that does negation:

And of course if we have NOT and we have AND, then we have NAND, and if we have NAND, then we have all the rest of binary logic. We can begin to build flip-flop gates out of the NAND gates to get simple memory cells, and we’re on our way to Turing-completeness!

























 . This number is either rational or irrational. Let’s examine each case.
. This number is either rational or irrational. Let’s examine each case.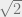 is irrational. So if
is irrational. So if 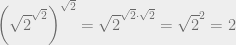
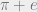 and
and 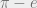 transcendental?
transcendental? and
and  are both transcendental numbers (i.e. they cannot be expressed as the roots of any polynomial with rational coefficients). But are
are both transcendental numbers (i.e. they cannot be expressed as the roots of any polynomial with rational coefficients). But are  would also not be transcendental, which we know is false! So we know that at least one of them has to be true, using a proof that doesn’t guarantee the truth of either of them! Cool, right?
would also not be transcendental, which we know is false! So we know that at least one of them has to be true, using a proof that doesn’t guarantee the truth of either of them! Cool, right?