Which paradigm is stronger? When I say logic here, I’ll be referring to standard formal theories like ZFC and Peano arithmetic. If one uses an expansive enough definition to include computability theory, then logic encompasses computation and wins by default.
If you read this post, you might immediately jump to the conclusion that logic is stronger. After all, we concluded that in first order Peano arithmetic one can unambiguously define not only the decidable sets, but the sets decidable with halting oracles, and those decidable with halting oracles for halting oracles, and so on forever. We saw that the Busy Beaver numbers, while undecidable, are definable by a Π1 sentence. And Peano arithmetic is a relatively weak theory; much more is definable in a theory like ZFC!
On the other hand, remember that there’s a difference between what’s absolutely definable and what’s definable-relative-to-ℕ. A set of numbers is absolutely definable if there’s a sentence that is true of just those numbers in every model of PA. It’s definable-relative-to-ℕ if there’s a sentence that’s true of just those numbers in the standard model of PA (the natural numbers, ℕ). Definable-relative-to-ℕ is an unfair standard for the strength of PA, given that PA, and in general no first order system, is able to categorically define the natural numbers. On the other hand, absolute definability is the standard that meets the criterion of “unambiguous definition”. With an absolute definition, there’s no room for confusion about which mathematical structure is being discussed.
All those highly undecidable sets we discussed earlier were only definable-relative-to-ℕ. In terms of what PA is able to define absolutely, it’s limited to only the finite sets. Compare this to what sets of numbers can be decided by a Turing machine. Every finite set is decidable, plus many infinite sets, including the natural numbers!
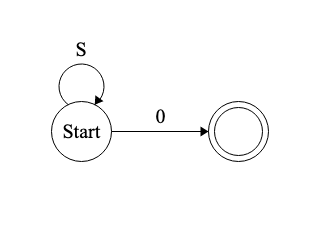
This is the first example of computers winning out over formal logic in their expressive power. While no first order theory (and in general no theory in a logic with a sound and complete proof system) can categorically define the natural numbers, it’s incredibly simple to write a program that defines that set using the language of PA. In regex, it’s just “S*0”. And here’s a Python script that does the job:
def check(s):
if s == '':
return False
elif s == ‘0’:
return True
elif s[0] == ’s’:
return check(s[1:])
else:
return False
We don’t even need a Turing machine for this; we can build a simple finite state machine:
In general, the sets decidable by computer can be much more complicated and interesting than those absolutely definable by a first-order theory. While first-order theories like ZFC have “surrogates” for infinite sets of numbers (ω and its definable subsets), these surrogate sets include nonstandard elements in some models. As a result, ZFC may fail to prove some statements about these sets which hold true of ℕ but fail for nonstandard models. For instance, it may be that the Collatz conjecture is true of the natural numbers but can’t be proven from ZFC. This would be because ZFC’s surrogate for the set of natural numbers (i.e. ω) includes nonstandard elements in some models, and the Collatz conjecture may fail for some such nonstandard elements.
On top of that, by taking just the first Turing jump into uncomputability, computation with a halting oracle, we are able to prove the consistency of ZFC and PA. Since ZFC is recursively axiomatizable, there’s a program that runs forever listing out theorems, such that every theorem is output at some finite point. We can use this to produce a program that looks to see if “0 = 1” is a theorem of ZFC. If ZFC is consistent, then the program will search forever and never find this theorem. But if ZFC is not consistent, then the program will eventually find the theorem “0 = 1” and will terminate at that point. Now we just apply our halting oracle to this program! If ZFC is consistent, then the halting oracle tells us that the program doesn’t halt, in which case we return “True”. If ZFC is not consistent, then the halting oracle tells us that the program does halt, in which case we return “False”. And just like that, we’ve decided the truth value of Con(ZFC)!
The same type of argument applies to Con(PA), and Con(T) for any T that is recursively axiomatizable. If you’re not a big fan of ZFC but have some other favored system for mathematics, then so long as this system’s axioms can be recognized by a computer, its consistency can be determined by a halting oracle.
Some summary remarks.
On the one hand, there’s a very simple explanation for why logic appears over and over again to be weaker than computation: we only choose to study formal theories that are recursively axiomatizable and have computable inference rules. Of course we can’t do better than a computer using a logical theory that can be built into a computer! If on the other hand, we chose true arithmetic, the set of all first-order sentences of PA that are true of ℕ, to be our de jure theory of mathematics, then the theorems of mathematics could not be recursively enumerated by any Turing machine, or indeed any oracle machine below 0(ω). So perhaps there’s nothing too mysterious here after all.
On the other hand, there is something very philosophically interesting about truths of mathematics that cannot be proven just using mathematics, but could be proven if it happened that our universe gave us access to an oracle for the halting problem. If a priori reasoning is thought to be captured by a formal system like ZFC, then it’s remarkable that there are facts about the a priori (like Con(ZFC)) that cannot possibly be established by a priori reasoning. Any consistency proof cannot be provided by a consistent system itself, and going outside to a stronger system whose consistency is more in doubt doesn’t help at all. The only possible way to learn the truth value of such statements is contingent; we can learn it if the universe contains some physical manifestation of a halting oracle!
Previously I talked about the arithmetic hierarchy for sets, and how it relates to the decidability of sets. There’s also a parallel notion of the arithmetic hierarchy for sentences of Peano arithmetic, and it relates to the difficulty of deciding the truth value of those sentences.
Truth value here and everywhere else in this post refers to truth value in the standard model of arithmetic.Truth value in the sense of “being true in all models of PA” is a much simpler matter; PA is recursively axiomatizable and first order logic is sound and complete, so any sentence that’s true in all models of PA can be eventually proven by a program that enumerates all the theorems of PA. So if a sentence is true in all models of PA, then there’s an algorithm that will tell you that in a finite amount of time (though it will run forever on an input that’s false in some models).
Not so for truth in the standard model! As we’ll see, whether a sentence evaluates to true in the standard model of arithmetic turns out to be much more difficult to determine in general. Only for the simplest sentences can you decide their truth value using an ordinary Turing machine. And the set of all sentences is in some sense infinitely uncomputable (you’ll see in a bit in what sense exactly this is).
What we’ll discuss is a way to convert sentences of Peano arithmetic to computer programs. Before diving into that, though, one note of caution is necessary: the arithmetic hierarchy for sentences is sometimes talked about purely syntactically (just by looking at the sentence as a string of symbols) and other times is talked about semantically (by looking at logically equivalent sentences). Here I will be primarily interested in the entirely-syntactic version of the arithmetic hierarchy. If you’ve only been introduced to the semantic version of the hierarchy, what you see here might differ a bit from what you recognize.
Let’s begin!
The simplest types of sentences have no quantifiers at all. For instance…
0 = 0 2 ⋅ 2 < 7 (2 + 2 = 4) → (2 ⋅ 2 = 4)
Each of these sentences can be translated into a program quite easily, since +, ⋅, =, and < are computable. We can translate the → in the third sentence by converting it into a conjunction:
In each of these examples, the bounded quantifier could in principle be expanded out, leaving us with a finite quantifier-free sentence. This should suggest to us that adding bounded quantifiers doesn’t actually increase the computational difficulty.
We can translate sentences with bounded quantifiers into programs by converting each bounded quantifier to a for loop. The translation slightly differently depending on whether the quantifier is universal or existential:
def Aupto(n, phi):
for x in range(n):
if not phi(x):
return False
return True
def Elessthan(n, phi):
for x in range(n):
if phi(x):
return True
return False
Note that the second input needs to be a function; reflecting that it’s a sentence with free variables. Now we can quite easily translate each of the examples, using lambda notation to more conveniently define the necessary functions
## ∀x<10 (x + 0 = x)
Aupto(10, lambda x: x + 0 == x)
## ∃x<100 (x + x = x)
Elessthan(100, lambda x: x + x == x)
## ∀x<5 ∃y<7 ((x > 1) → (x*y = 12))
Aupto(5, lambda x: Elessthan(7, lambda y: not (x > 1 and x * y != 12)))
## ∃x<5 ∀y<x ∀z<y (y⋅z ≠ x)
Elessthan(5, lambda x: Aupto(x, lambda y: Aupto(y, lambda z: y * z != x)))
Each of these programs, when run, determines whether or not the sentence is true. Hopefully it’s clear how we can translate any sentence with bounded quantifiers into a program of this form. And when we run the program, it will determine the truth value of the sentence in a finite amount of time.
So far, we’ve only talked about the simplest kinds of sentences, with no unbounded quantifiers. There are two names that both refer to this class: Π0 and Σ0. So now you know how to write a program that determines the truth value of any Σ0/Π0 sentence!
We now move up a level in the hierarchy, by adding unbounded quantifiers. These quantifiers must all appear out front and be the same type of quantifier (all universal or all existential).
Σ1 sentences: ∃x1 ∃x2 … ∃xk Phi(x1, x2, …, xk), where Phi is Π0. Π1 sentences: ∀x1 ∀x2 … ∀xk Phi(x1, x2, …, xk), where Phi is Σ0.
We can translate unbounded quantifiers as while loops:
def A(phi):
x = 0
while True:
if not phi(x):
return False
x += 1
def E(phi):
x = 0
while True:
if phi(x):
return True
x += 1
There’s a radical change here from the bounded case, which is that these functions are no longer guaranteed to terminate. A(Φ) never returns True, and E(Φ) never returns False. This reflects the nature of unbounded quantifiers. An unbounded universal quantifier is claiming something to be true of all numbers, and thus there are infinitely many cases to be checked. Of course, the moment you find a case that fails, you can return False. But if the universally quantified statement is true of all numbers, then the function will have to keep searching through the numbers forever, hoping to find a counterexample. With an unbounded existential quantifier, all one needs to do is find a single example where the statement is true and then return True. But if there is no such example (i.e. if the statement is always false), then the program will have to search forever.
I encourage you to think about these functions for a few minutes until you’re satisfied that not only do they capture the unbounded universal and existential quantifiers, but that there’s no better way to define them.
Now we can quite easily translate our example sentences as programs:
## ∃x ∃y (x⋅x = y)
E(lambda x: E(lambda y: x * x == y))
## ∃x (x⋅x = 5)
E(lambda x: x * x == 5)
## ∃x ∀y < x (x+y > x⋅y)
E(lambda x: Aupto(x, lambda y: x + y > x * y))
## ∀x (x + 0 = x)
A(lambda x: x + 0 == x)
## ∀x ∀y (x + y < 10)
A(lambda x: A(lambda y: x + y < 10))
## ∀x ∃y < 10 (y⋅y + y = x)
A(lambda x: Elessthan(10, y * y + y == x))
The first is a true Σ1 sentence, so it terminates and returns True. The second is a false Σ1 sentence, so it runs forever. See if you can figure out if the third ever halts, and then run the program for yourself to see!
The fourth is a true Π1 sentence, which means that it will never halt (it will keep looking for a counterexample and failing to find one forever). The fifth is a false Π1 sentence, so it does halt at the first moment it finds a value of x and y whose sum is 10. And figure out the sixth for yourself!
The next level of the hierarchy involves alternating quantifiers.
Σ2 sentences: ∃x1 ∃x2 … ∃xk Φ(x1, x2, …, xk), where Φ is Π1. Π2 sentences: ∀x1 ∀x2 … ∀xk Φ(x1, x2, …, xk), where Φ is Σ1.
So now we’re allowed sentences with a block of one type of unbounded quantifier followed by a block of the other type of unbounded quantifier, and ending with a Σ0 sentence. You might guess that the Python functions we’ve defined already are strong enough to handle this case (and indeed, all higher levels of the hierarchy), and you’re right. At least, partially. Try running some examples of Σ2 or Π2 sentences and see what happens. For example:
## ∀x ∃y (x > y)
A(lambda x: E(lambda y: x > y))
It runs forever! If we were to look into the structure of this program, we’d see that A(Φ) only halts if it finds a counterexample to Φ, and E(Φ) only halts if it finds an example of Φ. In other words A(E(Φ)) only halts if A finds out that E(Φ) is false; but E(Φ) never halts if it’s false! The two programs’ goals are diametrically opposed, and as such, brought together like this they never halt on any input.
The same goes for a sentence like ∃x ∀y (x > y): for this program to halt, it would require that ∀y (x > y) is found to be true for some value of x, But ∀y (x > y) will never be found true, because universally quantified sentences can only be found false! This has nothing to do with the (x > y) being quantified over, it’s entirely about the structure of the quantifiers.
No Turing machine can decide the truth values of Σ2 and Π2 sentences. There’s a caveat here, related to the semantic version of the arithmetic hierarchy. It’s often possible to take a Π2 sentence like ∀x ∃y (y + y = x) and convert it to a logically equivalent but Π1 sentence like ∀x ∃y<x (y + y = x). This translation works, because y + y = x is only going to be true if y is less than or equal to x. Now we have a false Π1 sentence rather than a false Π2 sentence, and as such we can find a counterexample and halt.
We can talk about a sentence’s essential level on the arithmetic hierarchy, which is the lowest level of the logically equivalent sentence. It’s important to note here that “logically equivalent sentence” is a cross-model notion: A and B are logically equivalent if and only if they have the same truth values in every model of PA, not just the standard model. The soundness and completeness of first order logic, and the recursive nature of the axioms of PA, tells us that the set of sentences that are logically equivalent to a given sentence of PA is recursively enumerable. So we can generate these sentences by searching for PA proofs of equivalence and keeping track of the lowest level of the arithmetic hierarchy attained so far.
Even when we do this, we will still find sentences that have no logical equivalents below Σ2 or Π2. These sentences are essentially uncomputable; not just uncomputable in virtue of their form, but truly uncomputable in all of their logical equivalents. However, while they are uncomputable, they would become computable if we had a stronger Turing machine. Let’s take another look at the last example:
## ∀x ∃y (x > y)
A(lambda x: E(lambda y: x > y))
Recall that the problem was that A(E(Φ)) only halts if E(Φ) returns False, and E(Φ) can only return True. But if we had a TM equipped with an oracle for the truth value of E(Φ) sentences, then maybe we could evaluate A(E(Φ))!
Let’s think about that for a minute more. What would an oracle for the truth value of Σ1 sentences be like? One thing that would work is if we could run E(Φ) “to infinity” and see if it ever finds an example, and if not, then return False. So perhaps an infinite-time Turing machine would do the trick. Another way would be if we could simply ask whether E(Φ) ever halts! If it does, then ∃y (x > y) must be true, and if not, then it must be false.
So a halting oracle suffices to decide the truth values of Σ1 sentences! Same for Π1 sentences: we just ask if A(Φ) ever halts and return False if so, and True otherwise.
If we run the above program on a Turing machine equipped with a halting oracle, what will we get? Now we can evaluate the inner existential quantifier for any given value of x. So in particular, for x = 0, we will find that Ey (x > y) is false. We’ve found a counterexample, so our program will terminate and return False.
On the other hand, if our sentence was true, then we would be faced with the familiar feature of universal quantifiers: we’d run forever looking for a counterexample and never find one. So to determine that this sentence is true, we’d need an oracle for the halting problem for this new more powerful Turing machine!
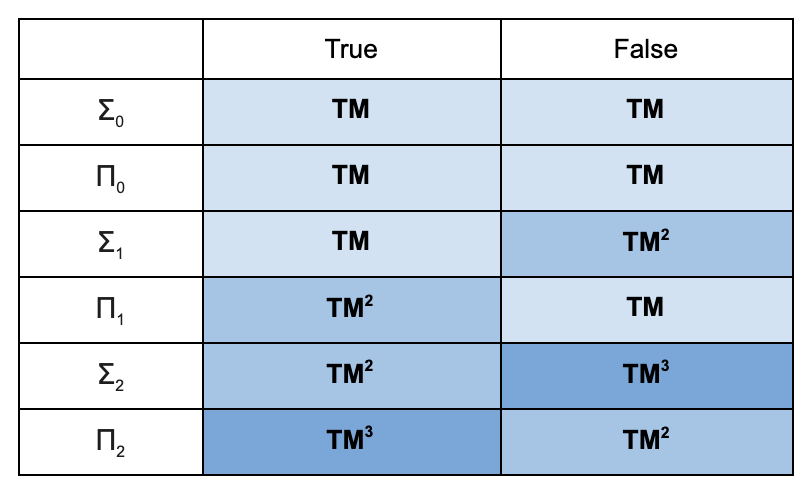
Here’s a summary of what we have so far:
TM = Ordinary Turing Machine TM2 = TM + oracle for TM TM3 = TM + oracle for TM2
The table shows what type of machine suffices to decide the truth value of a sentence, depending on where on the arithmetic hierarchy the sentence falls and whether the sentence is true or false.
We’re now ready to generalize. In general, Σn sentences start with a block of existential quantifiers, and then alternate between blocks of existential and universal quantifiers n – 1 times before ending in a Σ0 sentence. Πn sentences start with a block of universal quantifiers, alternates quantifiers n – 1 times, and then ends in a Σ0 sentence. And as you move up the arithmetic hierarchy, it requires more and more powerful halting oracles to decide whether sentences are true:
If we define Σω to be the union of all the Σ classes in the hierarchy, and Πω the union of the Π classes, then deciding the truth value of Σω ⋃ Πω (the set of all arithmetic sentences) would require a TMω – a Turing machine with an oracle for TM, TM2, TM3, and so on. Thus the theory of true arithmetic (the set of all first-order sentences that are true of ℕ), is not only undecidable, it’s undecidable with a TM2, TM3, and TMn for every n ∈ ℕ. At every level of the arithmetic hierarchy, we get new sentences that are essentially on that level (not just sentences that are superficially on that level in light of their syntactic form, but sentences which, in their simplest possible logically equivalent form, lie on that level).
This gives some sense of just how hard math is. Just understanding the first-order truths of arithmetic requires an infinity of halting oracles, each more powerful than the last. And that says nothing about the second-order truths of arithmetic! That would require even stronger Turing machines than TMω – Turing machines that have halting oracles for TMω, and then TMs with oracles for that, and so on to unimaginable heights (just how high we must go is not currently known).
The Busy Beaver numbers are an undecidable set; if they were decidable, we could figure out BB(n) for each n, enabling us to decide the halting problem. They are also not recursively enumerable, but for a trickier reason. Recursive enumerability would not allow you to figure out BB(n) (as it just gives us the ability to list out the BB numbers in some order, not necessarily in increasing order). But since the sequence is strictly increasing, recursive enumerability would enable us to put an upper bound on BB(n), which is just as good for the purposes of solving the halting problem. Simply enumerate the BB numbers in whatever order your algorithm allows, and once you’ve listed n of them, you know that the largest of those n is at least as big as the BB(n) (after all, it’s a BB number that’s larger than n-1 other BB numbers).
So the Busy Beaver numbers are also not recursively enumerable. But curiously, they’re Turing equivalent to the halting problem, and the halting problem is recursively enumerable. So what gives?
The answer is that the Busy Beaver numbers are co-recursively enumerable. This means that there is an algorithm that takes in a number N and returns False if N is not a Busy Beaver number, and runs forever otherwise. Here’s how that algorithm works:
First, we use the fact that BB(N) is always greater than N. This allows us to say that if N is a Busy Beaver number, then it’s the running time of a Turing machine with at most N states. There are finitely many such Turing machines, so we just run them all in parallel. We wait for N steps, and then see if any machines halt at N steps.
If no machines halt at N steps, then we return False. If some set of machines {M1, M2, …, Mk} halt at N steps, then we continue waiting. If N is not a Busy Beaver number, then for each of these machines, there must be another machine of the same size that halts later. So if N is not a Busy Beaver number, then for each Mi there will be a machine Mi‘ such that Mi‘ has the same number of states as Mi and that halts after some number of steps Ni‘ > N. Once this happens, we rule out Mi as a candidate for the Busy Beaver champion. Eventually, every single candidate machine is ruled out, and we can return False.
On the other hand, if N is a Busy Beaver number, then there will be some candidate machine M such that no matter how long we wait, we never find another machine with the same number of states that halts after it. In this case, we’ll keep waiting forever and never get to return True.
It’s pretty cool to think that for any number that isn’t a Busy Beaver number, we can in principle eventually rule it out. If a civilization ran this algorithm to find the first N busy beaver numbers, they would over time rule out more and more candidates, and after a finite amount of time, they would have the complete list of the first N numbers. Of course, the nature of co-recursive enumerability is that they would never know for sure if they had reached that point; they would forever be waiting to see if one of the numbers on their list would be invalidated and replaced by a much larger number. But in the limit of infinite time, this process converges perfectly to truth.
✯✯✯
Define H to be the set of numbers that encode Turing machines that halt on the empty input, and B to be the set of Busy Beaver numbers. H and B are Turing equivalent. The proof of this is two-part:
H is decidable with an oracle for B
We are given as input a Turing machine M (encoded as some natural number) and asked whether it will halt. We use our oracle for B to find the value of BB(n), where n is the number of states that M has, and run M for BB(n) steps. If M doesn’t halt at this point, then we know that it will never halt and we return False. And if it has already halted, we return True.
2. B is decidable with an oracle for H
We are given as input a number N and asked whether it’s a Busy Beaver number. We collect all Turing machines with at most N states, and apply H to determine which of these halt. We throw out all the non-halting Turing machines and run all the rest. We then run all the remaining Turing machines until each one has halted, noting the number of steps that each runs for and how many states it had. At the end we check if N was the running time of any of the Turing machines, and if so, if there are any other Turing machines with the same number of states that halted later. If so, then we return False, and otherwise we return True.
So H and B have the same Turing degree. And yet B is co-recursively enumerable and H is recursively enumerable (given a Turing machine M, just run it and return True if it ever halts). This is actually not so strange; the difference between recursive enumerability and co-recursive enumerability is not a difference in “difficulty to decide”, it’s just a difference between whether what’s decided is the True instances or the False instances.
As a very simple example of the same phenomenon, consider the set of all halting Turing machines H and the set of all non-halting Turing machines Hc. H is recursively enumerable and Hc is co-recursively enumerable. And obviously given an oracle for either one can also decide the other. More generally, for any set X, consider Xc = {n : n ∉ X}. X and Xc are Turing equivalent, and if X is recursively enumerable then Xc is co-recursively enumerable. What’s more, if X is Σn then Xc is Πn.
In this post you’ll learn about a deep connection between sentences of first order arithmetic and degrees of uncomputability. You’ll learn how to look at a logical sentence and determine the degree of uncomputability of the set of numbers that it defines. And you’ll learn much of the content of and intuitive justification for Post’s theorem, which is perhaps the most important result in computability theory.
The arithmetic hierarchy is a classification system for sets of natural numbers. It relates sentences of Peano arithmetic to degrees of uncomputability. There’s a level of the hierarchy for each natural number, and on each level there are three classes: Σn, Πn, and Δn. Where on the hierarchy a set of naturals lies indicates the complexity of the formulas that define it. Here’s how that works:
Σ0 = Π0 = Δ0
On the zeroth level are all the sets that are definable by a sentence in the language of first-order Peano arithmetic that has no unbounded quantifiers. Examples:
x = 0 (x = 0) ∨ (x = 3) ∨ (x = 200) ∃y < 200 (x = y) ∀y < x ∀z < y (y⋅z = x → z = 1) ∃y < x (x = y + y)
The first two examples have no quantifiers at all. The first, x = 0, is true of exactly one natural number (namely, 0), so the set that it defines is just {0}. The second is true of three natural numbers (0, 3, and 200), so the set it defines is {0, 3, 200}. Thus both {0} and {0, 3, 200} are on the zeroth level of the hierarchy. It should be clear that just by stringing together a long enough disjunction of sentences, we can define any finite set of natural numbers. So every finite set of natural numbers is on the zeroth level of the hierarchy.
The third example has a quantifier in it, but it’s a bounded quantifier. In that sentence, y only ranges over 200 different natural numbers. In some sense, this sentence could be expanded out and written as a long disjunction of the form (x = 0) ∨ (x = 1) ∨ … ∨ (x = 199). It should be easy to see that the set this defines is {0, 1, 2, … 199}.
The fourth example is a little more interesting, for two reasons. First of all, the quantifiers are now bound by variables, not numbers. This is okay, because no matter what value of x we’re looking at, we’re only checking finitely many values of y, and for each value of y, we only check finitely many values of z. Secondly, this formula can be translated as “x is a prime number.” This tells us that the set of primes {2, 3, 5, 7, 11, …} is on the zeroth level of the hierarchy, our first infinite set!
The fifth example also gives us an infinite set; work out which set this is for yourself before moving on!
Notice that each of the sets we’ve discussed so far can be decided by a Turing machine. For each set on the zeroth level, the defining sentence can be written without any quantifiers, involving just the basic arithmetic operations of Peano arithmetic (+, ⋅, and <), each of which is computable. So for instance, we can write an algorithm that decides prime membership for x by looking at the sentence defining the set of primes:
∀y < x ∀z < y (y⋅z = x → z = 1)
for y in range(x):
for z in range(y):
if (y⋅z == x) and (z != 1):
return False
return True
Another example:
(x = 0) ∨ (x = 3) ∨ (x = 200)
if (x = 0) or (x = 3) or (x = 200):
return True
else:
return False
Every sentence with only bounded quantifiers can be converted in a similar way to an algorithm that decides membership in the set it defines. We just translate bounded quantifiers as for loops! Thus every set on the zeroth level is decidable. It turns out that every decidable set is also on the zeroth level. We can run the process backwards and, given an algorithm deciding membership in the set, convert it into a sentence of first-order Peano arithmetic with only bounded quantifiers.
On the zeroth level, the three classes Σ0, Π0, and Δ0 are all equal. So every decidable set can be said to be in each of Σ0, Π0, and Δ0. The reason for the three different names will become clear when we move on to the next level of the hierarchy.
Σ1, Π1, Δ1
Entering into the first level, we’re now allowed to use unbounded quantifiers in our definitions of the set. But not just any pattern of unbounded quantifiers, they must all be the same type of quantifier, and must all appear as a block at the beginning of the sentence. For Σ1 sets, the quantifiers up front must all be existential. For example:
∃y (y2 + y + 1 = x) ∃y ∃z (y is prime ∧ z is prime ∧ x = y + z ∧ x is even)
The first defines the infinite set {1, 3, 7, 13, 21, 31, …}, and the second defines the set of all even numbers that can be written as the sum of two primes (whether this includes every even number is unknown!). The shorthand I’ve used in the second sentence is permitted, because we know from the previous section that the sentences “x is prime” and “x is even” can be written without unbounded quantifiers.
It so happens that each of these sets can also be defined by formulas on the zeroth level as well. One easy way to see how is that we can just bound each quantifier by x and everything is fine. But are there any Σ1 sets that aren’t also Σ0?
Yes, there are! Every decidable set is in Σ0, so these examples won’t be as simple. To write them out, I’ll have to use some shorthand that I haven’t really justified:
∃y (the Turing machine encoded by x halts in y steps) ∃y (y Gödel-codes a proof from PA of the sentence Gödel-coded by x)
Both of these rely on the notion of numbers encoding other objects. In the first we encode Turing machines as numbers, and in the second we encode sentences of Peano arithmetic as numbers using Gödel numbering. In general, any finite object whatsoever can be encoded as a natural number, and properties of that object can be discussed as properties of numbers.
Let’s take a close look at the first sentence. The set defined by this sentence is the set of numbers that encode Turing machines that halt. (For readability, in the future I’ll just say “the set of Turing machines such that …” rather than “the set of natural numbers that encode Turing machines with the property …”.) This set is undecidable, by the standard proof of the undecidability of the halting problem. This tells us that the set cannot be defined without any quantifiers!
The second sentence defines the set of natural numbers that encode theorems of PA. Why is this set not decidable? Suppose that it were. Then we could ask “is 0=1 a theorem of PA?” and, assuming the consistency of PA, after a finite amount of time get back the answer “No.” This would allow us to prove the consistency of PA, and crucially, the Turing machine that we use to decide this set could be coded as a number and used by PA to prove the same thing! Then PA would prove its own consistency, making it inconsistent and contradicting our assumption. On the other hand, if PA is inconsistent, then this set actually is decidable, because everything is provable from the axioms of PA and the set of all sentences can be decided! So this is only a good example of “Σ1 but not Σ0” if you have faith in the consistency of PA.
The Σ0 sets were the decidable sets, so what are the Σ1 sets? They are the recursively enumerable sets (also called semi-decidable). These are the sets for which an algorithm exists that takes in an input N and returns True if N is in the set, and runs forever otherwise. And just like before, we can use the sentences of PA to construct such an algorithm! Let’s look at the first example:
∃y (y2 + y + 1 = x)
y = 0
while True:
if y**2 + y + 1 == x:
return True
y += 1
For each unbounded quantifier, we introduce a variable and a while loop that each step increases its value by 1. This program runs until it finds a “yes” answer, and if no such answer exists, it runs forever.
Another example:
∃y (the Turing machine encoded by x halts in y steps)
y = 0
while True:
if TM(x) halts in y steps:
return True
y += 1
I made up some notation here on the fly; TM(x) is a function that when fed a natural number returns the Turing machine it encodes. So what this program does is run TM(x) for increasing lengths of time, returning True if TM(x) ever halts. If TM(x) never halts, then the program runs forever. So this program semi-decides the halting problem.
Moving on to Π1 sets! Σ1 sets were those defined by sentences that started with a block of existential quantifiers, and Π1 sets are defined by sentences that start with a block of unbounded universal quantifiers. For example:
∀y ∀z (x = y⋅z → (y = 1 ∨ x = 1)) ∀y > x ∃z < y (x⋅z = y)
The first example is hopefully clear enough. It defines the set of prime numbers in a similar way to before. The second is meant to be slightly deceiving. That first quantifier might look bounded, until you notice that the variable it supposedly binds ranges over infinitely many values. On the other hand, the second quantifier is genuinely bounded, as for any given y it only ranges over finitely many values. See if you can identify the set it defines.
Both of these sets are in fact also in Σ0. Like with Σ1 sets, it’s difficult to find simple examples of Π1 sets that aren’t also Σ0. Here’s a cheap example:
∀y (the Turing machine encoded by x doesn’t halt in y steps)
This defines the set of non-halting Turing machines. If we were to translate this into a program, it would look something like:
y = 0
while True:
if TM(x) halts in y steps:
return False
y += 1
The difference between this and the earlier example is that this program can only successfully determine that natural numbers aren’t in the set, not that they are in the set. So we can only decide the “no” cases rather than the “yes” cases. Sets like this are called co-recursively enumerable.
So far we have that Σ0 = Π0 = Δ0 = {decidable sets of naturals}, Σ1 = {recursively enumerable sets of naturals}, and Π1 = {co-recursively enumerable sets of naturals}. To finish off level one of the hierarchy, we need to discuss Δ1.
A set is Δ1 if it is both Σ1 and Π1. It can be defined by either type of sentence. In other words, if it is both recursively enumerable (can decide the True instances) and co-recursively enumerable (can decide the False instances). Thus a set is Δ1 if and only if it’s decidable! So every Δ1 set is also a Δ0 set.
A diagram might help at this point to see what we’ve learned:
(“Recursive” is another term for “decidable”)
Σ2, Π2, Δ2
We now enter the second level of the hierarchy. Having exhausted the recursively enumerable, co-RE, and decidable sets, we know that the new sets we encounter can no longer be semi-decided by any algorithms. We’ve thus entered a new realm of uncomputability.
A set is Σ2 if it can be defined by a sentence with a block of ∃s, then a block of ∀s, and finally a Σ0 sentence (free of unbounded quantifiers. Start with some simple examples:
As with any examples you can write as simply as that, the sets these define are also Σ0. So what about sentences that define genuinely new sets that we haven’t seen before? Here’s one:
∃y ∀z (TM(x) doesn’t halt on input y after z steps)
This defines the set of Turing machines that compute partial functions (i.e. functions that run forever on some inputs).
Something funny happens when you start trying to translate this sentence into a program. We can start by translating the existential quantifier up front:
y = 0
while True:
if ∀z (TM(x) doesn't halt on input y after z steps):
return True
y += 1
Now let’s see what it would look like to expand the universal quantifier:
z = 0
while True:
if TM(x) halts on input y after z steps:
return False
z += 1
There’s a problem here. The first program only halts if the second one returns True. But the second one never returns “True”; it’s Π1, co-recursively enumerable! We’ve mixed a recursively enumerable program with a co-recursively enumerable one, and as a result the program we wrote never halts on any input!
This is what happens when we go above the first level of the hierarchy. We’ve entered the realm of true uncomputability.
On the other hand, suppose that we had access to an oracle for the halting problem. In other words, suppose that we are allowed to make use of a function Halts(M, i) that decides for any Turing machine M and any input i, whether M halts on i. Now we could write the following program:
y = 0
while True:
if not Halts(TM(x), i):
return True
y += 1
And just like that, we have a working program! Well, not quite. This program halts so long as its input x is actually in the set of numbers that encode TMs that compute partial functions. If x isn’t in that set, then the program runs forever. This is the equivalent of recursive enumerability, but for programs with access to an oracle for the halting problem!
This is what characterizes Σ2 sets: they are recursively enumerable using a Turing machine with an oracle for the halting problem.
Perhaps predictably, Π2 sets are those that are co-recursively enumerable using a Turing machine with an oracle for the halting problem. Equivalently, these are sets that are definable with a sentence that has a block of ∀s, then a block of ∃s, and finally a Σ0 sentence. An example of such a set is the set of Turing machines that compute total functions. Another is the set of Busy Beaver numbers.
And just like on level one of the hierarchy, the Δ2 sets are those that are both Σ2 and Π2. Such sets are both recursively enumerable and co-recursively enumerable with the help of an oracle for the halting problem. In other words, they are decidable using an oracle for the halting problem. (Notice that again, Δ2 sets are “easier to decide” than Σ2 and Π2 sets.)
The Busy Beaver numbers are an example of a Δ2 set. After all, if one had access to an oracle for the halting problem, they could compute the value of the nth Busy Beaver number. Simply list out all the n-state Turing machines, use your oracle to see which halt, and run all of those that do. Once they’ve all stopped, record the number of steps taken by the longest-running. With the ability to compute the nth Busy Beaver number, we do the following:
n = 1
while True:
if x == BB(n):
return True
n += 1
This returns True for all inputs that are Busy Beaver numbers, but runs forever on those that aren’t. We can fix this with bounded quantifiers: since the Busy Beaver numbers are a strictly increasing sequence, once we’ve reached an n such that x < BB(n), we can return False. This gives us an algorithm that decides the set of Busy Beaver numbers!
In fact, the Busy Beaver numbers are even better than Δ2; they’re Π1, co-recursively enumerable! But that’s a tale for another time.
Σn, Πn, Δn
Perhaps you’re now beginning to see the pattern.
Σ3 sets are those that can be defined by a sentence that has a block of ∃s, then a block of ∀s, then a block of ∃s, and finally a Σ0 sentence. We could more concisely say that Σ3 sets are those that can be defined by a sentence that has a block of ∃s and then a Π2 sentence.
Π3 sets are those definable by a sentence that starts with a block of ∀s, then alternates twice between groups of quantifiers before ending in a sentence with only bound quantifiers.
And Δ3 sets are those that are Σ3 and Π3. If you’ve picked up the pattern, you might guess that the Δ3 sets are exactly those that are decidable with an oracle for the halting problem for Turing machines that have an oracle for the halting problem. The Σ3 sets are those that are recursively enumerable with such an oracle, and the Π3 sets are co-RE with the oracle.
And so on for every natural number.
Σn sets are definable by a sentence that looks like ∃x1 ∃x2 … ∃xk φ(x, x1, x2, …, xk), where φ is Πn-1. Πn sets are definable by a sentence that looks like ∀x1 ∀x2 … ∀xk φ(x, x1, x2, …, xk), where φ is Σn-1. And Δn sets are both Σn and Πn.
At each level of the hierarchy, we introduce new oracle Turing machines with more powerful oracles. We’ll call the Turing machines encountered on the nth level TMns.
Σn sets are recursively enumerable with an oracle for the halting problem for TMns. Πn sets are co-recursively enumerable with an oracle for the halting problem for TMns. Δn sets are decidable with an oracle for the halting problem for TMns.
One might reasonably wonder if at some stage we exhaust all the sets of natural numbers. Or do we keep finding higher and higher levels of uncomputability?
Yes, we do! For each n, Σn is a proper subset of Σn+1 and Πn is a proper subset of Πn+1. One easy argument to see why this must be the case is that there are an uncountable infinity of sets of naturals, and only countably many sets of naturals in each level of the hierarchy. (This is because each level of the hierarchy is equivalent to the sets that are computable/recursively enumerable/co-RE using a TM with a particular oracle, and each TM only computes countably many things.)
This tells us that the hierarchy doesn’t collapse at any finite stage. Each step up, we find new sets that are even harder to decide than all those we’ve encountered so far. But (and now prepare yourself for some wildness) we can make the same cardinality argument about the finite stages of the hierarchy to tell us that even these don’t exhaust all the sets. There are only countably many finite stages of the hierarchy, and each stage contains only countably many sets of naturals!
What this means is that even if we combined all the finite stages of the hierarchy to form one massive set of sets of naturals decidable with any number of oracles for halting problems for earlier levels, we would still have not made a dent in the set of all sets of naturals. To break free of the arithmetic hierarchy and talk about these even more uncomputable levels, we need to move on to talk about the set of Turing degrees, the structure of which is incredibly complex and beautiful.
A concept: a book that starts by assuming the understanding of the reader and using concepts freely, and as you go on it introduces a simple formal procedure for defining words. As you proceed, more and more words are defined in terms of the basic formal procedure, so that halfway through, half of the words being used are formally defined, and by the end the entire thing is formally defined. Once you’re read through the whole book, you can start it over and read from the beginning with no problem.
I just finished a set theory textbook that felt kind of like that. It started with the extremely sparse language of ZFC: first-order logic with a single non-logical symbol, ∈. So the alphabet of the formal language consisted of the following symbols: ∈ ( ) ∧ ∨ ¬ → ↔ ∀ ∃ x ‘. It could have even started with a sparser formal language if it was optimizing for alphabet economy: ∈ ( ∧ ¬ ∀ x ‘ would suffice. As time passed and you got through more of the book, more and more things were defined in terms of the alphabet of ZFC: subsets, ordered pairs, functions from one set to another, transitivity, partial orders, finiteness, natural numbers, order types, induction, recursion, countability, real numbers, and limits. By the last chapter it was breathtaking to read a sentence filled with complex concepts and realize that every single one of these concepts was ultimately grounded in this super simple formal language we started with, with a finitistic sound and complete system of rules for how to use each one.
But could it be possible to really fully define ALL the terms used by the end of the book? And even if it were, could the book be written in such a way as to allow an alien that begins understanding nothing of your language to read it and, by the end, understand everything in the book? Even worse, what if the alien not only understands nothing of your language, but starts understanding nothing of the concepts involved? This might be a nonsensical notion; an alien that can read a book and do any level of sophisticated reasoning but doesn’t understand concepts like “and” and “or“.
One way that language is learned is by “pointing”: somebody asks me what a tree is, so I point to some examples of trees and some examples of non-trees, clarifying which is and which is not. It would be helpful if in this book we could point to simple concepts by means of interactive programs. So, for instance, an e-book where an alien reading the book encounters some exceedingly simple programs that they can experiment with, putting in inputs and seeing what results. So for instance, we might have a program that takes as input either 00, 01, 10, or 11, and outputs the ∧ operation applied to the two input digits. Nothing else would be allowed as inputs, so after playing with the program for a little bit you learn everything that it can do.
One feature of such a book would be that it would probably use nothing above first-order logical concepts. The reason is that the semantics of second-order logic cannot be captured by any sound and complete proof system, meaning that there’s no finitistic set of rules one could explain to an alien so that they know how to use the concepts involved correctly. Worse, the set of second-order tautologies is not even recursively enumerable (worse than the set of first-order tautologies, which is merely undecidable), so no amount of pointing-to-programs would suffice. First-order ZFC can define a lot, but can it define enough to write a book on what it can define?
The axiom of foundation says that every non-empty set must contain an element that it is disjoint with. One implication of this is that no set can contain itself. (Why? Suppose ∃x (x ∈ x). Then you can pair x with itself to form {x}. {x} is non-empty, so it must contain an element that it’s disjoint with. But its only element is x, and that element is not disjoint with {x}. In particular, they both have as an element x.)
Another implication of foundation is that there can be no infinite descending sequence of sets. A sequence of sets is a function f whose domain is ω. For each k ∈ ω we write f(k) as fk. Suppose that f is a function with the property that for each n ∈ ω, fn+1 ∈ fn. Then by the axiom of replacement, there would exist the set {f0, f1, f2, …}. Each element of this set contains the following element, so none of the elements are disjoint with the entire set. So the sequence we started with could not exist.
This allows us to prove a pretty powerful and surprising result about set theory. The result: For any sentence Φ, if Φ holds of at least one set, then there must exist a set X such that Φ(X) holds, but Φ doesn’t hold for any element of X.
Formally:
(∃A Φ(A)) → ∃X (Φ(X) ∧ ∀Y ∈ X (¬Φ(Y))).
Suppose this was false. Then Φ would be satisfied by at least one set, and every set that satisfied Φ would contain an element that satisfied Φ. We can use this to build an infinite descending sequence of sets. Take any set that satisfies Φ and call it X0. Since X0 satisfies Φ, it must contain at least one element that satisfies Φ. Define X1 to be any such element. X1 satisfies Φ as well, so it must contain at least one element that satisfies Φ, which we’ll call X2. And so on forever. Since no set can contain itself, Xn+1 is always distinct from Xn. We can use recursion and then replacement to construct the set {X0, X1, X2, …}, which is an infinite descending sequence of sets. Contradiction!
This peculiar principle turns out to be useful to prove some big results, and the proofs are always a little funny and enjoyable to me. I’m not aware of any name for it, so I’ll call it the “far-from-the-tree” principle: for any property that holds of at least one set, there’s a set that has that property, none of whose elements have the property. I’ll now show two big results that are proven by this principle.
Everything’s in the Cumulative Hierarchy
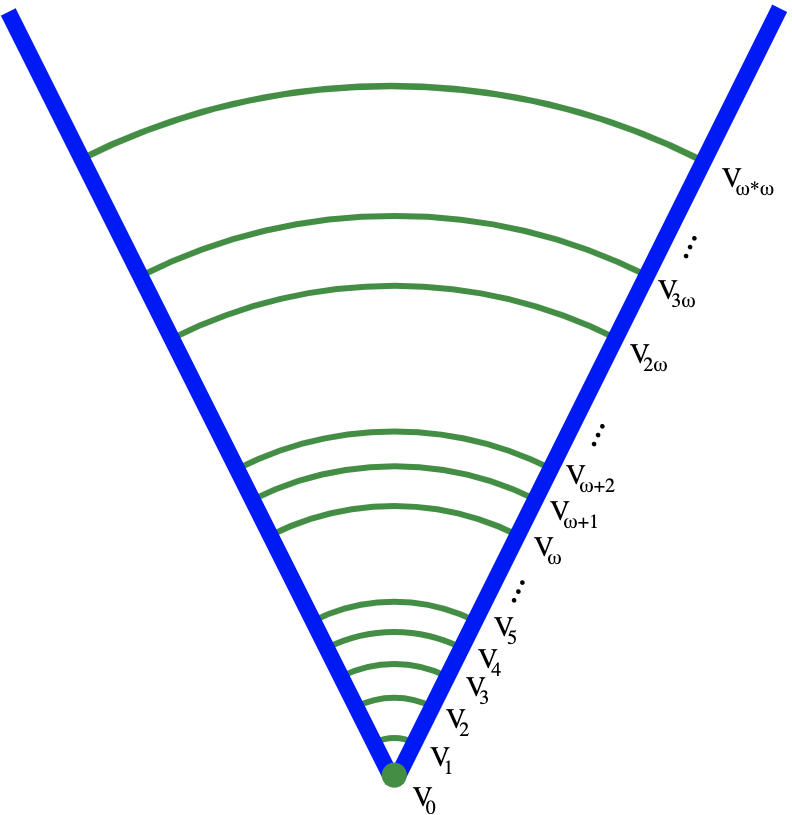
The cumulative hierarchy is constructed recursively as follows:
V0 = ∅ Vα+1 = 𝒫(Vα), for each ordinal α Vλ = U{Vβ : β < λ}, for each limit ordinal λ
One can prove that Vα is transitive for each ordinal α (in other words, that every element of Vα is also a subset of Vα). Also, due to the nature of the power-set operation, for any two ordinals α < β, Vα ⊆ Vβ.
Now, the reason the cumulative hierarchy is interesting is that we can prove that every set is on some level of the hierarchy. We do so with the far-from-the-tree principle:
Suppose that there was a set X that wasn’t on the hierarchy. This means that ∀α, X ∉ Vα. We use the far-from-tree principle with the property of “not being on the hierarchy” to conclude that there must be a set Y such that Y is not on the hierarchy, but every element of Y is on the hierarchy. So for each element y ∈ Y there’s some ordinal αy such that y ∈ Vαy. Take the highest such ordinal, and now we have a level of the hierarchy that every element of Y is on. Now just go up by one level! Since every element of Y was in the previous level, the set consisting of each of those elements (i.e. Y) is in the power set of that level. So Y actually is on the hierarchy! Contradiction.
This shows that any set you choose shows up on some level of the cumulative hierarchy. Incidentally, the rank of a set is defined as the first level that the set appears on, and one can prove that for each ordinal α, rank(α) = α.
∈-Induction
∈-induction is a really strong principle of induction, because it is induction over all sets, not just the natural numbers or the ordinals. The principle of ∈-induction is the following:
Suppose that for every set X, if Φ(x) holds for every x ∈ X, then Φ(X) holds. Then Φ holds of every set.
Suppose that this principle was false. Then it’s true that for every set X, if Φ(x) holds for every x ∈ X, then Φ(X) holds, but false that Φ holds of every set. So there’s some set Y such that ¬Φ(Y). We use the far-from-the-tree principle with the property “¬Φ”. This tells us that there’s some set Z such that ¬Φ(Z), but Φ(z) for every z in Z. But we already said that if Φ(z) for every z in Z, then Φ(Z)! Contradiction.
I hope you like these applications as much as I do. They feel to me like very strong and surprising results, especially given how simply they can be proved.
In discussions of first-order logic and set theory, one often hears about nonstandard natural numbers and their unusual properties. But rarely do you hear about nonstandard integers, nonstandard rationals, or nonstandard reals. This post will be devoted to the ways in which these other number systems pick up unintended interpretations in first-order logic, and in particular first-order ZFC.
Nonstandard ℕ
Nonstandard interpretations of the natural numbers are the most well-known, so I won’t spend much time on them. In ZFC, the set of natural numbers is called ω, and is defined to be the intersection of all inductive sets. An inductive set is one that includes zero and is closed under successorship (if n is in the set, then so is S(n)).
This definition feels so right when you think about it for a little while that it’s hard to see how it could go wrong. How could there be anything OTHER than the standard natural numbers in the intersection of all inductive sets?
Well, one can prove from the compactness of first order logic that there must be such nonstandard numbers, and the proof is so simple and pretty that it’s probably already appeared on this blog six or seven times. Add to ZFC a constant K and the axioms “K ∈ ω”, “K > 0”, “K > 1”, “K > 2”, and so on for all the standard naturals (this is a decidable set of sentences). Every finite subset of this new theory has a model, so by compactness the theory as a whole also has a model. This model is nonstandard by construction, and is also a model of ZFC by monotonicity (removing axioms never removes models).
So how do nonstandard naturals appear in the intersection of all inductive sets? The key term to focus on is the “all” in “all inductive sets”. While ZFC guarantees the existence of an inductive set (by the axiom of infinity) and every definable subset of this set (by comprehension/separation), it does not actually guarantee the existence of ALL subsets of this set. (This is actually a general feature of first-order theories, that they are able to guarantee the existence of all definable subsets of a set, but not all subsets.) There are models where the inductive set given to us by the axiom of infinity is enormous (uncountably large), and all of its subsets contain (in addition to the standard naturals) infinitely descending membership chains of sets, each of which contains every standard natural. In these models, omega is not just the standard naturals, but also includes these infinite elements, these numbers with infinitely many predecessors. And the proof from compactness shows us that we can’t eliminate these nonstandard natural numbers.
Nonstandard ℤ
The usual way of defining the integers in ZFC is as equivalence classes of pairs of natural numbers. In particular, we define the equivalence relation ~ on ω×ω as follows: (a, b) ~ (c, d) if and only if a + d = b + c. Two ordered pairs of naturals are equivalent under this relation so long as their difference is the same. So (1, 0) is in the same class as (2, 1), which is in the same class as (15, 14).
The idea here is that the integer represented by the equivalence class of (a, b) is supposed to be what we think of as a – b. So the integer 2 is the equivalence class {(2, 0), (3, 1), (4, 2), (5, 3), …}. And the integer -2 is the equivalence class {(0, 2), (1, 3), (2, 4), (3, 5), …}. For shorthand, we’ll write the equivalence class of (a, b) as [a, b]. Thus for each positive integer n, we can write n = [n, 0], and for each negative integer n, n = [0, n].
Addition and multiplication can be defined on the integers in terms of addition and multiplication on ω.
Check to make sure that this makes sense in light of our interpretation of [a, b] as a – b. We can also define new operations on the integers that didn’t apply to the naturals, like negation.
-[a, b] = [b, a]
And we can define an order on the integers as follows:
[a, b] < [c, d] if and only if a + d < b + c
Check to make sure that this makes sense.
Now, the integers are built out of ω, so it makes sense that the nonstandard interpretations of ω carry over to nonstandard interpretations of ℤ. But there are in fact two ways in which integers can be nonstandard.
(1) The natural number 0 refers to the same object (the empty set) in every model of ZFC. But the set of natural numbers ω refers to different objects in different models, as we saw a moment ago. In this sense, ω is not categorically defined, while 0 is. But since integers are infinite sets of pairs of elements of ω, individual integers aren’t categorically defined either!
For instance, the integer 0 is the set {(n, m) ∈ ω×ω | n = m}. The number of elements in this set is the same as the number of elements of ω. So the integer 0 has as many elements as ω! This means that in a nonstandard model of ω that has nonstandard numbers like K, 0 will also contain nonstandard ordered pairs like (K, K) and (K+1, K+1).
(2) Consider the nonstandard element of ω that we’re calling K, which is larger than every standard natural number. There’s an integer [K, 0], which is the equivalence class of the ordered pair (K, 0). [K, 0] > [1, 0], because K + 0 > 0 + 1. And [K, 0] > [55, 0], because K + 0 > 0 + 55. And so on for every finite integer. Just like ω, there are models in which ℤ has integers larger than all the standard integers.
But unlike ω, in nonstandard models ℤ also has nonstandard integers less than all standard integers. Consider -[K, 0] = [0, K]. Again, you can prove that this integer is less than the integer 0, the integer -55, and so on for every standard integer you can think of.
From now on I’ll write the integer [n, 0] as n and the integer [0, n] as -n.
Nonstandard ℚ
Just as the integers were equivalence classes of pairs of naturals, the rationals are equivalence classes of pairs of integers. We define a new equivalence relation (which I’ll use the same symbol for) as follows:
For integers a, b, c, and d, (a, b) ~ (c, d) if and only if a⋅d = b⋅c.
This equates any two pairs of integers that have the same ratio. So (1, 2) ~ (2, 4) ~ (15, 30), and (-33, 17) ~ (66, -34) ~ (-99, 51). The equivalence classes of this relationship are the rational numbers. Like before, we’ll write [a, b] to represent the equivalence class that (a, b) belongs to. You can think of [a, b] as representing the rational number a/b.
Defining addition, multiplication, subtraction, and division on the rationals is pretty easy:
And the order is similarly easy to define in terms of the order on integers:
[a, b] < [c, d] if and only if a⋅d < b⋅c
Once we’ve moved to ℤ, there’s an explosion of nonstandard elements. For instance, we still have nonstandard rationals larger than every ordinary rational (like [K, 1]). But now we also have rationals like [1, K]. This rational is smaller than every ordinary positive rational [1, 10], [1, 100], [1, 1000], and so on. And it is greater than the rational number 0! So in other words we now have infinitesimal rational numbers!
What’s more, we can construct a rational like [K+1, K]. This guy is infinitesimally larger than the rational number 1. So is [K+1, K⋅2], but this one is even closer to 1 than the previous. And we also have [K+1, K2], which is even closer!
The nonstandard rational number line is crowded with these infinitesimal and infinite elements. The ordinary rationals are usually thought to be dense, but we’ve just seen that there are nonstandard rationals that are “too close together” to fit any standard rationals in. However, between any two nonstandard rationals K and K’, there’s another nonstandard rational (K + K’) / 2.
If you’ve heard of the hyperreals, you might be wondering if any of the nonstandard rationals have the same structure. The simple reason why they don’t is that the hyperreals are complete – there are no gaps – whereas the rationals are not. For instance, ZFC can prove that there is no rational [a, b] such that [a, b] ⋅ [a, b] = 2, but there is a hyperreal with that property. To get completion of the number line, we have to move on to the next step, the reals.
Nonstandard ℝ
The construction of the reals from the rationals is slightly different from the previous constructions. Instead of considering ordered pairs of rationals, we’ll consider sets of rationals. In particular, we’ll look at nonempty sets of rationals that are closed downwards (if n is in the set and m < n, then m is in the set also), and have no greatest element, but don’t include all rationals.
Each real number is one of these subsets, and ℝ is the set of all such subsets. So for instance, the real number √2 is the set {x ∈ ℚ : x2 < 2}. The order on the reals is simple to describe:
x ≤ y if and only if x ⊆ y
Addition is also easily defined:
x + y = {r + s : (r ∈ x) ∧ (s ∈ y)}
Multiplication of reals has a messier definition, but it’s nothing too crazy. And importantly, ZFC can prove that ℝ has the following feature: any non-empty subset of ℝ which is bounded above has a least upper bound.
Now, in nonstandard models, there are real numbers like K, 1/K, 1 + 1/K2 and so on. But now there’s also real numbers like √K, 2K, log(K), and any other function you can define on the reals, applied to infinite reals and infinitesimals. So in one sense, the nonstandard models have many more reals than the “ordinary reals” we learn about in calculus.
But the way we constructed the reals as subsets of the rationals opened up a new type of nonstandard phenomena, in which there end up being many fewer reals that we expect there to be. Remember that we identified reals with subsets of the rationals, and that earlier we said that there is in general no way to guarantee the existence of all subsets of an infinite set. The same applies here; when we say that ℝ = {A ⊆ ℚ | A is a Dedekind cut}, we are actually only guaranteeing the existence of those reals that can be definable as Dedekind cuts. So for instance, ZFC can prove the existence of √2 as a real number, because ZFC can define the Dedekind cut {x ∈ ℚ : x2 < 2}. Same with most real numbers you’re probably familiar with, like π and e. But considering that there are only countably many definitions in ZFC, and uncountably many reals, there must be uncountably many reals that are undefinable! These undefinable reals cannot be proven to exist, and thus there are models in which they don’t exist.
In fact, the set ℝ is the first of the sets we’ve discussed that not only has nonstandard interpretations in which it’s too large, but also nonstandard interpretations in which it’s too small. There are models of ZFC where ℝ has only countably many items! There’s a subtlety here, which is that ZFC can prove that |ℝ| > |ω|. How is this possible if there are models where ℝ is countable?
It’s possible because these models, which are missing many real numbers, are ALSO missing lots of functions, in particular the functions that would put ℝ and ω in bijective correspondence! So even though ℝ is “in reality” countable in these models, the model itself doesn’t know that, because it’s missing the functions that prove its countability.
In the game of Nim, you start with piles of various (whole number) heights. Each step, a player chooses one pile and shrinks it by some non-zero amount. Once a pile’s height has been shrunk to zero, it can no longer be selected by a player for shrinking. The winner of the game is the one that takes the last pile to zero.
Here’s a sample game of Nim:
Starting state 3, 2 After Frank’s move 2, 2 After Marie’s move 2, 1 After Frank’s move 0, 1 After Marie’s move 0, 0
Marie takes the last pile to zero, so she is the winner. Frank’s second-to last move was a big mistake; by reducing the first pile from 2 to 0, he left the only remaining pile free to be taken by Marie. In a game of Nim, you should never leave only one pile remaining at the end of your turn. If Frank had instead shrunk the first pile from 2 to 1, then the state of the piles would be (1, 1). Marie would be forced to shrink one of the two piles to zero, leaving Frank to take the final pile and win.
The strategy of Nim with two piles is extremely simple: in your turn you should always even out the two piles if possible. This is only possible if the heights are different at the start of your turn. See if you can figure out why this strategy guarantees a win!
Transfinite Nim is a version of Nim where the piles are allowed to take infinite ordinal values. So for instance, a game might have the following starting position:
Starting state ω2 + ω, ω1 + ε0
If Marie is moving first, then can she guarantee a win? What move should she make?
It turns out that the strategy for two-pile Transfinite Nim is exactly the same as for two-pile Finite Nim. Marie has a guaranteed win, because the two piles are different values. Each move she’ll just even the piles out. So for her first move, she should do the following:
Starting state ω2 + ω, ω1 + ε0 After Marie’s move ω2 + ω, ω2 + ω
No matter what Frank does next, Marie can just “copy” that move on the other pile, guaranteeing that Marie always has a move as long as Frank does. This proves that Marie must have the last move, and therefore win.
One important feature of Transfinite Nim is that even though we’re dealing with infinitely large piles, every game can only last finitely long. In other words, Frank has no strategy for delaying his loss infinitely long, and thus forcing a sort of “stalemate by exhaustion.” This is because the ordinals are well-ordered, and any decreasing sequence of well-ordered items must terminate. (Why? Just consider the definition of a well-ordered set: every subset has a least element. If the game were to continue infinitely long, each step decreasing the state but never terminating, then the sequence of states would be a subset of the ordinals which has no least element!)
Although the strategy of Transfinite Nim is in one sense no more interesting than Finite Nim, the game does have some interesting features that it inherits from the ordinals. For instance, there are sets of ordinal numbers such that the ordering between them is uncomputable. For such sets, the ability to compute the winning strategy is called into question.
For instance, the set of all countable ordinals is uncomputable. The quick proof is that there are uncountably many countable ordinals – otherwise in ZFC the set of countable ordinals would itself be a countable ordinal and would thus contain itself – and any Turing machine can only compare countably many things. However, there are also uncomputable ordinals that are countable! If α is a countable ordinal, then we can find some bijection (not necessarily order-preserving) between α and ω, meaning that we can meaningfully ask if a Turing machine can compare any two of α’s elements (each represented by some natural number). And for an uncomputable countable ordinal, we know that no Turing machine can successfully compute its order type.
The smallest uncomputable ordinal (which, in ZFC, is exactly the set of all computable ordinals) is called the Church Kleene ordinal and written ω1CK. Imagine the starting state of the game is two different ordinals that are both larger than ω1CK. If you’re moving first, then you have to determine which of the two ordinals is larger, in order to even them out. But this is not in general possible! So even if you go first and the two piles are different sizes, you might not be able to guarantee a win.
Suppose Marie is allowed uncomputable strategies, and Frank is only allowed computable strategies. Suppose further that the starting state involves two countable ordinals A and B, both larger than the Church-Kleene, and that the ordinals are expressed in some standard notation (so that you can’t write the same ordinal two different ways). There are a few cases.
Case 1: A = B, Marie goes first. Marie decreases one of the two ordinals. Despite not being able to compute the order on the ordinals, Frank can just mimic her move. This will continue until Frank wins.
Case 2: A = B, Frank goes first. Frank decreases one of the two ordinals, and Marie mimics. Marie eventually wins.
Case 3: A ≠ B, Marie goes first. Marie can tell which of the ordinals is larger, and decreases that one to even out the two piles. Marie wins.
Case 4: A ≠ B, Frank goes first. Frank can’t tell which of the ordinals is larger and can’t try to even them out, as doing so might result in an invalid move (trying to increase the smaller pile to the height of the larger one). So Frank does some random move, after which Marie is able to even out the two piles. Marie wins.
There’s a subtlety in Case 4, which is that Frank could gamble by guessing that B is the bigger ordinal and then decreasing it to A. If he has no other information, then half the time he’ll end up successfully evening them out, in which case he continues to win the game. But the other half of the time he’ll have made an invalid move. If we assume that players cannot run strategies that have some chance of choosing invalid moves (for instance, if each player has to be able to prove that their move is valid in advance), then Frank’s gamble would not be allowed and he would go on to lose.
Finally, here’s a starting state for a game of Transfinite Nim:
ω1, ℶ1
ω1 is the first uncountable ordinal, and ℶ1 is the first ordinal with continuum cardinality. Frank goes first. Does he have a winning strategy?
The answer to this question depends on whether ω1 = ℶ1, or in other words the Continuum Hypothesis! If the two are equal, then Frank can’t win, because he’s starting with two even piles. And if ω1 < ℶ1, then Marie can’t win, because Frank can decrease the ℶ1 pile to ω1.
If we suppose that the players must be able to prove a move’s validity in ZFC before playing that move, then the first player couldn’t decrease the ℶ1 pile to ω1. The first player still has to do something, and whatever he does will change the state to two ordinals that are comparable by ZFC. What about larger starting ordinals whose size comparison is independent of ZFC, like ω15 and ℶ15? If the new state after the first player’s move move also involves two ordinals whose size comparison is independent of ZFC, then the second player will also be unable to even them out. This continues until one of them eventually decreases a pile to an ordinal whose size is comparable by ZFC to the other pile. So the winner will depend on who knows more pairs of ordinals less than the starting values with values that ZFC can’t compare. In fact, each player wants to force the other player to make the values ZFC-comparable, so they’ll be able to even the piles out on their turn.
What if our players are allowed to use different proof systems from each other? Then adjudication of whether a move is valid requires that we fix some meta-theoretic proof system as our judge. For instance, suppose our meta-theory is ZFC + V=L (in which case ω1 does equal ℶ1). In this case, if a player is using a theory from which they can prove that ω1 < ℶ1, they might end up making a move that we judge as invalid, even though in their view it’s perfectly valid. Presumably then each player has to reason within their own theory about what is valid according to the judge’s meta-theory. But perhaps these judgements will be fallible! If so, then the victor may end up depending on who has a better theory of the judge’s meta-theory!