Previous: Simpson’s paradox
In the last post, we saw how statistical reasoning can go awry in Simpson’s paradox, and how causal reasoning can rescue us. In this post, we’ll be generalizing the idea behind the paradox and producing arbitrarily complex versions of it.
The main idea behind Simpson’s paradox is that conditioning on an extra variable can sometimes reverse dependencies.
In our example in the last post, we saw that one treatment for kidney stones worked better than another, until we conditioned on the kidney stone’s size. Upon conditioning, the sign of the dependence between treatment and recovery changed, so that the first treatment now looked like it was less effective than the other.
We explained this as a result of a spurious correlation, which we represented with ‘paths of dependence’ like so:

But we can do better than just one reversal! With our understanding of causal models, we are able to generate new reversals by introducing appropriate new variables to condition upon.
Our toy model for this will be a population of sick people, some given a drug and some not (D), and some who recover and some who do not (R). If there are no spurious correlations between D and R, then our diagram is simply:

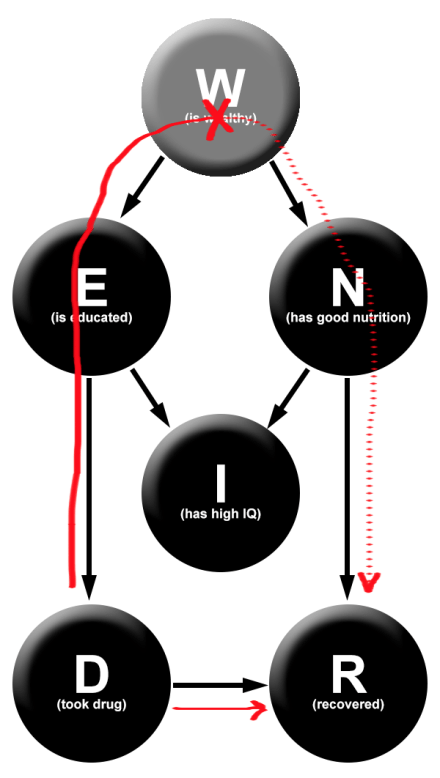
Now suppose that we introduce a spurious correlation, wealth (W). Wealthy people are more likely to get the drug (let’s say that this occurs through a causal intermediary of education level E), and are more likely to recover (we’ll suppose that this occurs through a casual intermediary of nutrition level of diet N).
Now we have the following diagram:

Where there was only previously one path of dependency between D and R, there is now a second. This means that if we observe W, we break the spurious dependency between D and R, and retain the true causal dependence.


This allows us one possible Simpson’s paradox: by conditioning upon W, we can change the direction of the dependence between D and R.
But we can do better! Suppose that your education level causally influences your nutrition. This means that we now have three paths of dependency between D and R. This allows us to cause two reversals in dependency: first by conditioning on W and second by conditioning on N.



And we can keep going! Suppose that education does not cause nutrition, but both education and nutrition causally impact IQ. Now we have three possible reversals. First we condition on W, blocking the top path. Next we condition on I, creating a dependence between E and N (via explaining away). And finally, we condition on N, blocking the path we just opened. Now, to discern the true causal relationship between the drug and recovery, we have two choices: condition on W, or condition on all three W, I, and N.



As might be becoming clear, we can do this arbitrarily many times. For example, here’s a five-step iterated Simpson paradox set-up:

The direction of dependence switches when you condition on, in this order: A, X, B’, X’, C’. You can trace out the different paths to see how this happens.
Part of the reason that I wanted to talk about the iterated Simpson’s paradox is to show off the power of causal modeling. Imagine that somebody hands you data that indicates that a drug is helpful in the whole population, harmful when you split the population up by wealth levels, helpful when you split it into wealth-IQ classes, and harmful when you split it into wealth-IQ-education classes.
How would you interpret this data? Causal modeling allows you to answer such questions by simply drawing a few diagrams!
Next we’ll move into one of the most significant parts of causal modeling – causal decision theory.
Previous: Simpson’s paradox
Next: Causal decision theory

4 thoughts on “Iterated Simpson’s Paradox”