(This will be the first in a short series of posts describing how various commonly used statistical methods are approximate versions of frequentist, Bayesian, and Akaike-ian inference)
Suppose that we have some data D = { (x₁, y₁), (x₂, y₂), … , (xɴ, yɴ) }, and a candidate function y = f(x).
Frequentist inference involves the assessment of the likelihood of the data given this candidate function: P(D | f).
Since D is composed of N independent data points, we can assess the probability of each data point separately, and multiply them all together.
P(D | f) = P(x₁, y₁ | f) P(x₂, y₂ | f) … P(xɴ, yɴ | f)
So now we just need to answer the question: What is P(x, y | f)?
f predicts that for the value x, the most likely y-value is f(x).
The other possible y-values will be normally distributed around f(x).
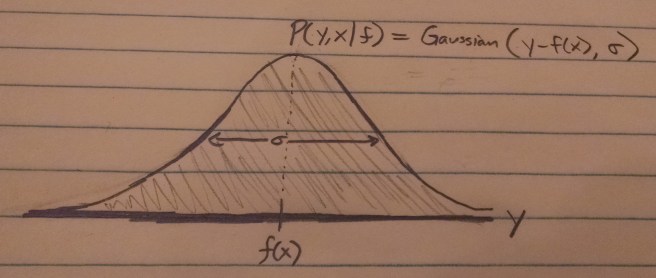
The equation for this distribution is a Gaussian:
P(x, y | f) = exp[ -(y – f(x))² / 2σ² ] / √(2πσ²)
Now that we know how to find P(x, y | f), we can easily calculate P(D | F)!
P(D | f) = exp[ -(y – f(x))² / 2σ² ] /√(2πσ²) ・ exp[ -(y – f(x))² / 2σ² ] / √(2πσ²) … exp[ -(y – f(x))² / 2σ² ] / √(2πσ²)
= exp[ -(y – f(x))² / 2σ² ] ・ exp[ -(y – f(x))² / 2σ² ] … exp[ -(y – f(x))² / 2σ² ] / (2πσ²)N/2
Products are messy and logarithms are monotonic, so log(P(D | f)) is easier to work with: it turns the product into a sum.
log P(D | f) = log( exp[ -(y₁ – f(x₁))² / 2σ² ] … exp[ -(yɴ – f(xɴ))² / 2σ² ] / (2πσ²)N/2 )
= log( exp[ -(y₁ – f(x₁))² / 2σ² ] ) + … log( exp[ -(yɴ – f(xɴ))² / 2σ² ] ) – N/2 log(2πσ²)
= -(y₁ – f(x₁))² / 2σ² ) + -(yɴ – f(xɴ))² / 2σ² ) – N/2 log(2πσ²)
= -1/2σ² [ (y₁ – f(x₁))² + … +(yɴ – f(xɴ))² ] – N/2 log(2πσ²)
Now notice that the sum of squares just naturally pops out!
SOS = (y₁ – f(x₁))² + … + (yɴ – f(xɴ))²
log P(D | f) = -SOS/2σ² – N/2 log(2πσ²)
Frequentist inference chooses f to maximize P(D | f). We can now immediately see why this is equivalent to minimizing SOS!
argmax{ P(D | f) }
= argmax{ log P(D | f) }
= argmax{ – SOS/2σ² – N/2 log(2πσ²) }
= argmin{ SOS/2σ² + N/2 log(2πσ²) }
= argmin{ SOS/2σ² }
= argmin{ SOS }
Next, we’ll go Bayesian…

2 thoughts on “Why minimizing sum of squares is equivalent to frequentist inference”