In front of you is a coin. You don’t know the bias of this coin, but you have some prior probability distribution over possible biases (between 0: always tails, and 1: always heads). This distribution has some statistical properties that characterize it, such as a standard deviation and a mean. And from this prior distribution, you can predict the outcome of the next coin toss.
Now the coin is flipped and lands heads. What is your prediction for the outcome of the next toss?
This is a dead simple example of a case where there is a correct answer to how to reason inductively. It is as correct as any deductive proof, and derives a precise and unambiguous result:
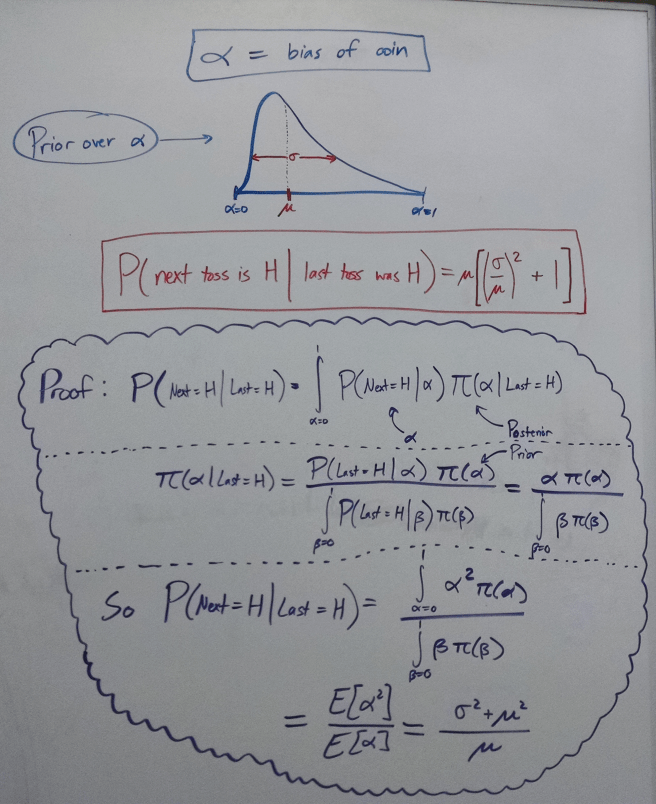
This is a law of rational thought, just as rules of logic are laws of rational thought. It’s interesting to me how the understanding of the structure of inductive reasoning begins to erode the apparent boundary between purely logical a priori reasoning and supposedly a posteriori inductive reasoning.
Anyway, here’s one simple conclusion that we can draw from the above image: After the coin lands heads, it should be more likely that the coin will land heads next time. After all, the initial credence was µ, and the final credence is µ multiplied by a value that is necessarily greater than 1.
You probably didn’t need to see an equation to guess that for each toss that lands H, future tosses landing H become more likely. But it’s nice to see the fundamental justification behind this intuition.
We can also examine some special cases. For instance, consider a uniform prior distribution (corresponding to maximum initial uncertainty about the coin bias). For this distribution (π = 1), µ = 1/2 and σ = 1/3. Thus, we arrive at the conclusion that after getting one heads, your credence in the next toss landing heads should be 13/18 (72%, up from 50%).
We can get a sense of the insufficiency of point estimates using this example. Two prior distributions with the same average value will respond very differently to evidence, and thus the final point estimate of the chance of H will differ. But what is interesting is that while the mean is insufficient, just the mean and standard deviation suffice for inferring the value of the next point estimate.
In general, the dynamics are controlled by the term σ/µ. As σ/µ goes to zero (which corresponds to a tiny standard deviation, or a very confident prior), our update goes to zero as well. And as σ/µ gets large (either by a weak prior or a low initial credence in the coin being H-biased), the observation of H causes a greater update.
How large can this term possibly get? Obviously, the updated point estimate should asymptote towards 1, but this is not obvious from the form of the equation we have (it looks like σ/µ can get arbitrarily large, forcing our final point estimate to infinity). What we need to do is optimize the updated point estimate, while taking into account the constraints implied by the relationship between σ and µ.
