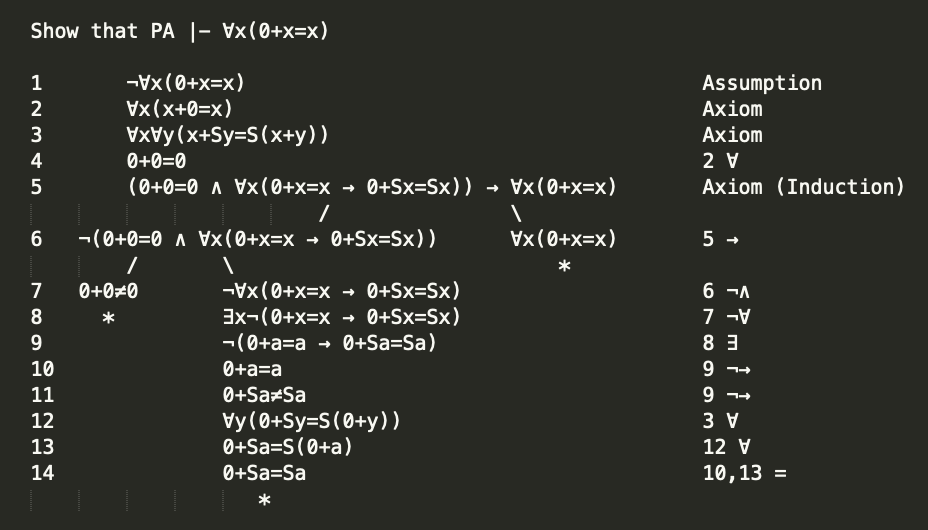
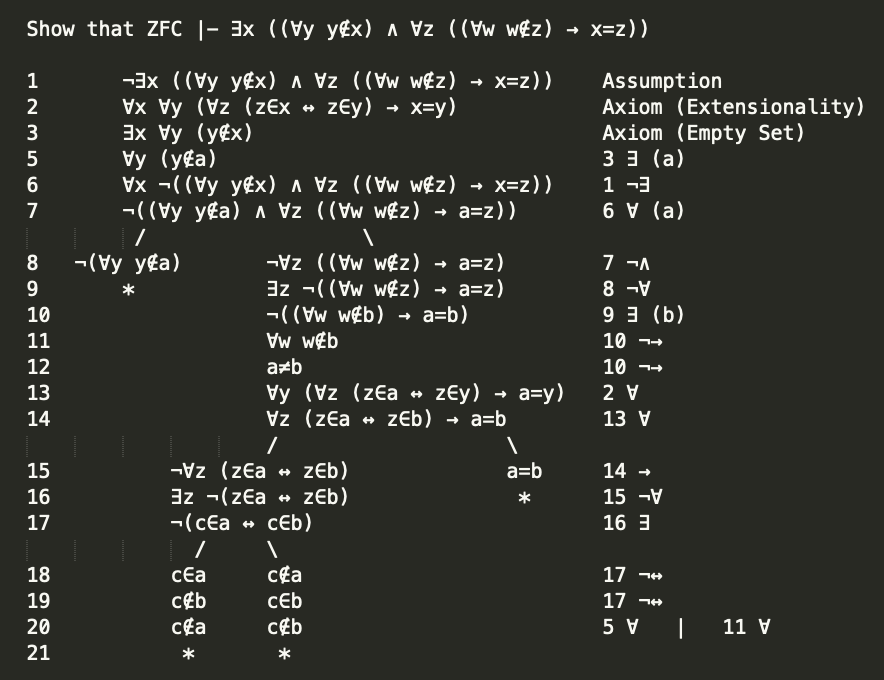
Previous: Infinitely Large Primes
We’ve seen how to use Łoś’s theorem to prove properties of hyperstructures. We’ve also seen how to use it to prove limitations of first-order logic. Today we’re going to see a major meta-logical application of Łoś’s theorem: proving the compactness theorem! In my opinion, this proof is the most elegant proof of first-order compactness out there. We’ll also see a few other meta-logical results relating to ultraproducts. However, if you’re just interested in learning about more properties of the hypernaturals, then you can skip this post without missing out on anything major!
What is compactness?
A logic is compact if any finitely satisfiable set of sentences is satisfiable. If somebody hands you an infinite set of sentences, and you know how to construct a model to satisfy any finite subset of these sentences, then you can conclude that there must be a model that satisfies all those sentences at once. Compactness is interesting because it allows you to prove surprising results (like that true arithmetic has nonstandard models) from very obvious facts (that any finite set of natural numbers has an upper bound). It also lets you prove the completeness theorem, which says that what you can prove from first-order axioms is exactly what logically follows from those axioms.
Countable Theories
First we’ll prove the compactness theorem for countable theories. I’m including it because it’s conceptually simpler than the proof of the general case. However, it’s not necessary for understanding the general proof, so if you just want to see that you can jump ahead to the next section.
Suppose T is a countably infinite theory that’s finitely satisfiable.
T is countable, so choose an enumeration of T’s sentences: T = {φ1, φ2, φ3, …}.
T is finitely satisfiable, so there’s a model that satisfies φ1. Call this model M1.
There’s also a model M2 that satisfies both φ1 and φ2.
And a model M3 that satisfies φ1, φ2, and φ3.
And so on.
Take the ultraproduct of (M1, M2, M3, …) and call it M.
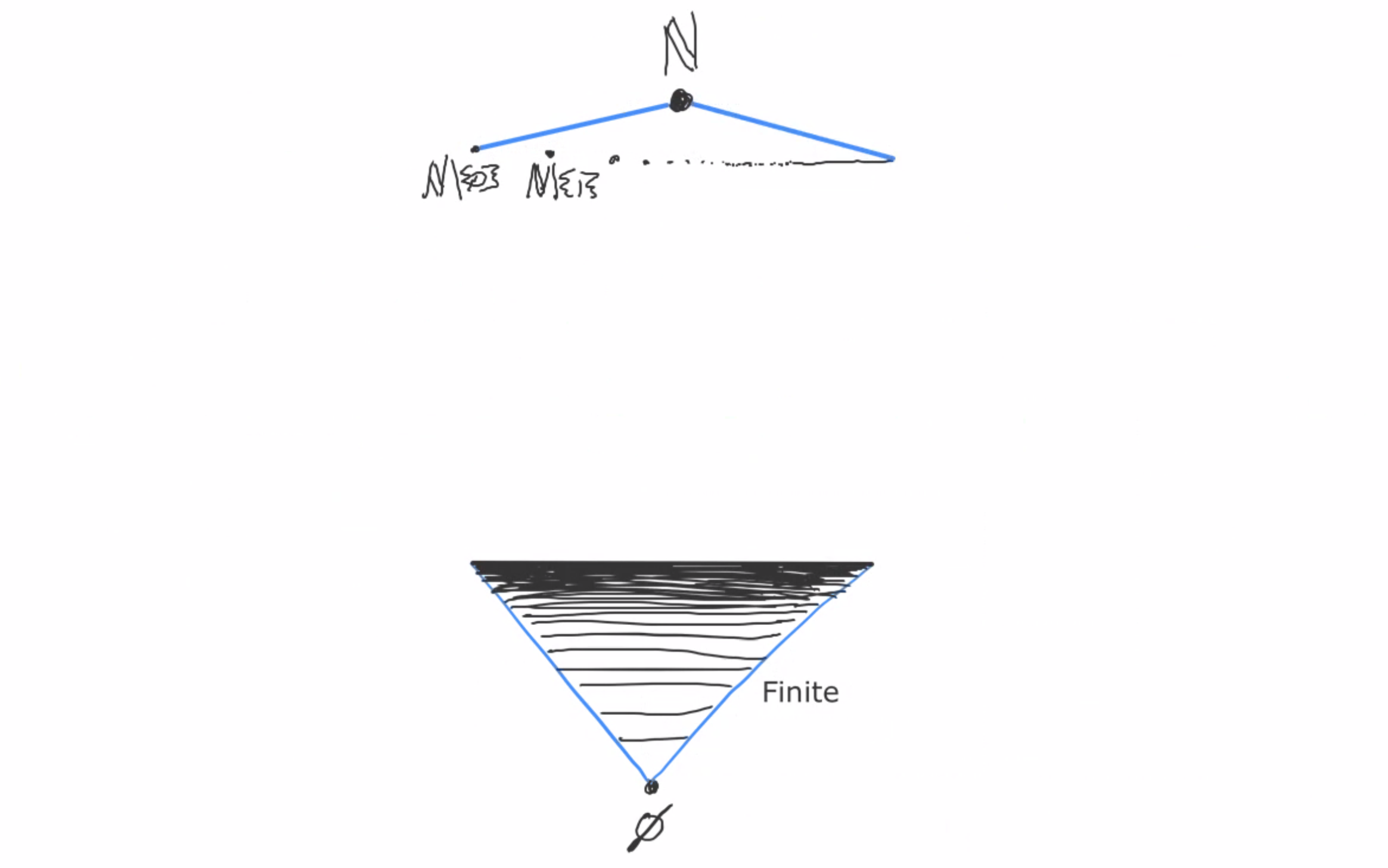
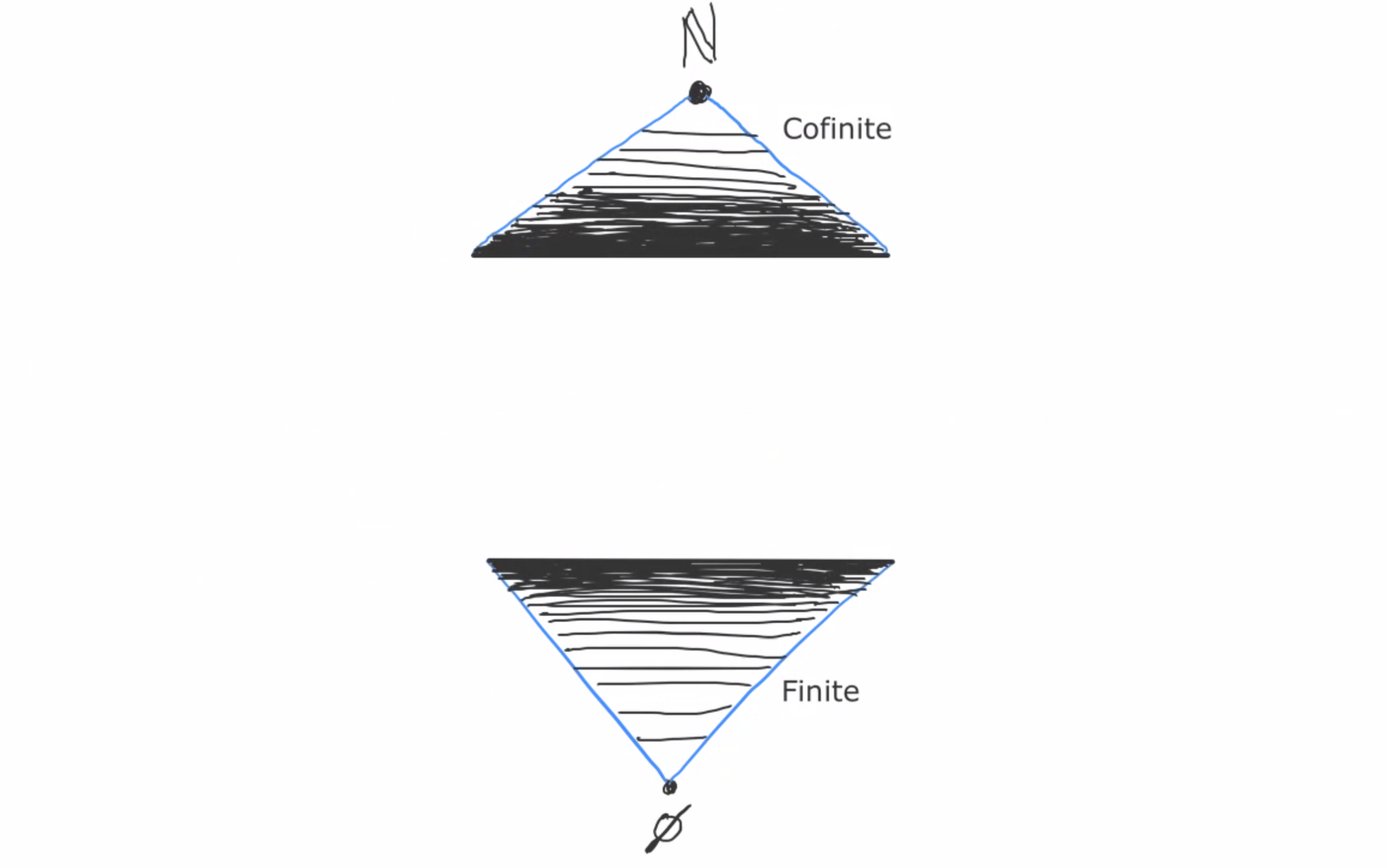
For every n in N, φn is satisfied by all models from Mk on. (For instance, φ4 is satisfied by M4, M5, M6, and so on.)
This is a cofinite set, so (by Los’s theorem) φn is satisfied by M.
But φn was a totally arbitrary sentence inside T. So M satisfies all of T!
So T is satisfiable. But not only do we get this result, we also have an explicit example of a model that satisfies all of T, which we can start analyzing to prove other properties of.
Compactness for any theory
The proof uses a fact that I haven’t proven yet: If X is a set whose every finite subset has nonempty intersection, then there’s some ultrafilter that extends it. Luckily, it’s easily proven. Start by closing X under supersets (notice that every finite subset of X still has nonempty intersection). Then close it under intersection, and you now have a filter that extends X. (Verify that this really is a filter for bonus points!) And in Part 3 of this series we proved that every filter has an ultrafilter extension. So there’s an ultrafilter U that contains X.
Alright, on to the proof.
Let L be any first-order language and S be any set of L-sentences that is finitely satisfiable. We’re going to build an ultraproduct that satisfies S. This requires three ingredients: an index set I, and a set of L-structures (Mi)i∈I indexed by I, and an ultrafilter U on I. We’ll go through these one at a time.
1. The index set I
I will be the set of all finite subsets of S. This is interestingly different from what we’ve seen before. Previously our indices were always natural numbers. But here our indices are sets of sentences in the language of the structure! This means that we’re going to end up looking at models that look like M{φ,ψ,θ}, where φ,ψ, and θ are sentences in S.
2. The component structures (Mi)i∈I
So, our indices are finite subsets of S. And S is finitely satisfiable. So for each index F (each finite subset of S), there’s a model MF that satisfies everything in F. This is how we get our component structures.
For instance, if φ, ψ, and θ are three sentences in S, then {φ,ψ,θ} is an index, and M{φ,ψ,θ} is any structure that satisfies φ∧ψ∧θ. ∅ is also a finite subset of S, so it’s an index and has a corresponding structure M∅, which can be any L-structure whatsoever.
To briefly rehash, the important feature of our choice of component structures is that they have the following property: For any finite subset F of S, MF ⊨ φ for every φ in F.
3. The ultrafilter U on I
The choice of ultrafilter here is really important. Our component structures were carefully chosen so that each structure satisfies the finite set of sentences that is its index. This guarantees us that for any sentence φ in S, the set of component structures whose indices contain φ all satisfy φ. This is the set of component structures whose indices are finite supersets of {φ}.
Remember that we’re ultimately aiming to show that each φ is satisfied by the ultraproduct model. By Łoś’s theorem, it suffices to show that the set of component models that satisfy φ is U-large (is in our chosen ultrafilter). Conclusion: we want to make sure that for any φ in S, the set of all finite supersets of {φ} is U-large.
How do we know that there exists any ultrafilter that for every φ contains the set of all finite supersets of {φ}? We apply the finite intersection property! Denote by SF the set of all finite supersets of F. Take any finite set of singletons {{φ1}, {φ2}, {φ3}, …, {φn}}. Is the intersection of S{φ1}, S{φ2}, S{φ3}, …, S{φn} empty? No: the set {φ1, φ2, φ3, …, φn} is in of all of them! So the set { S{φ} | φ ∈ S } has the finite intersection property, and thus there’s some ultrafilter that extends it. And that’s the ultrafilter we want!
Finalizing things
We’ve now got everything we need to build the structure that satisfies S. Take the ultraproduct Π(MF)F∈I/U. This structure satisfies S. Why?
Consider any φ in S. By Łoś’s theorem, φ is satisfied if a U-large set of the component models satisfy φ. And we know that a U-large set of component models satisfy φ, because φ is satisfied in every model whose index contains φ, i.e. the set of models whose indices are supersets of {φ}. So we’re done!
More implications
The remainder of this post will not be necessary to understand the rest of the series. I want to present a few miscellaneous meta-logical results that relate to ultraproducts that don’t quite fit anywhere else.
First: every finite structure is its own ultrapower. Let’s see why.
Suppose M is a finite structure. Denote by MI/U the ultrapower of M over any arbitrary index set I. First of all, we can easily see that M and MI/U have the same cardinality: if |M| = n for some finite n, then there’s a sentence affirmed by M that says “There are exactly n distinct things”. For instance, if M has exactly two elements, then M ⊨ ∃x ∃y (x≠y ∧ ∀z (z=x ∨ z=y)). Łoś tells us that MI/U also affirms this sentence, so MI/U also has exactly n distinct things.
Furthermore, any finite structure M of size n can be categorically specified up to isomorphism by a single first-order sentence of the form ∃x1∃x2…∃xn (∀x (x = x1 ∨ … ∨ x = xn) ∧ (x1 ≠ x2 ∧ … xn-1 ≠ xn) ∧ ψ(x1, …, xn) ], where ψ specifies the behavior of all relation, function, and constant symbols. Here’s an example for a simple finite structure:
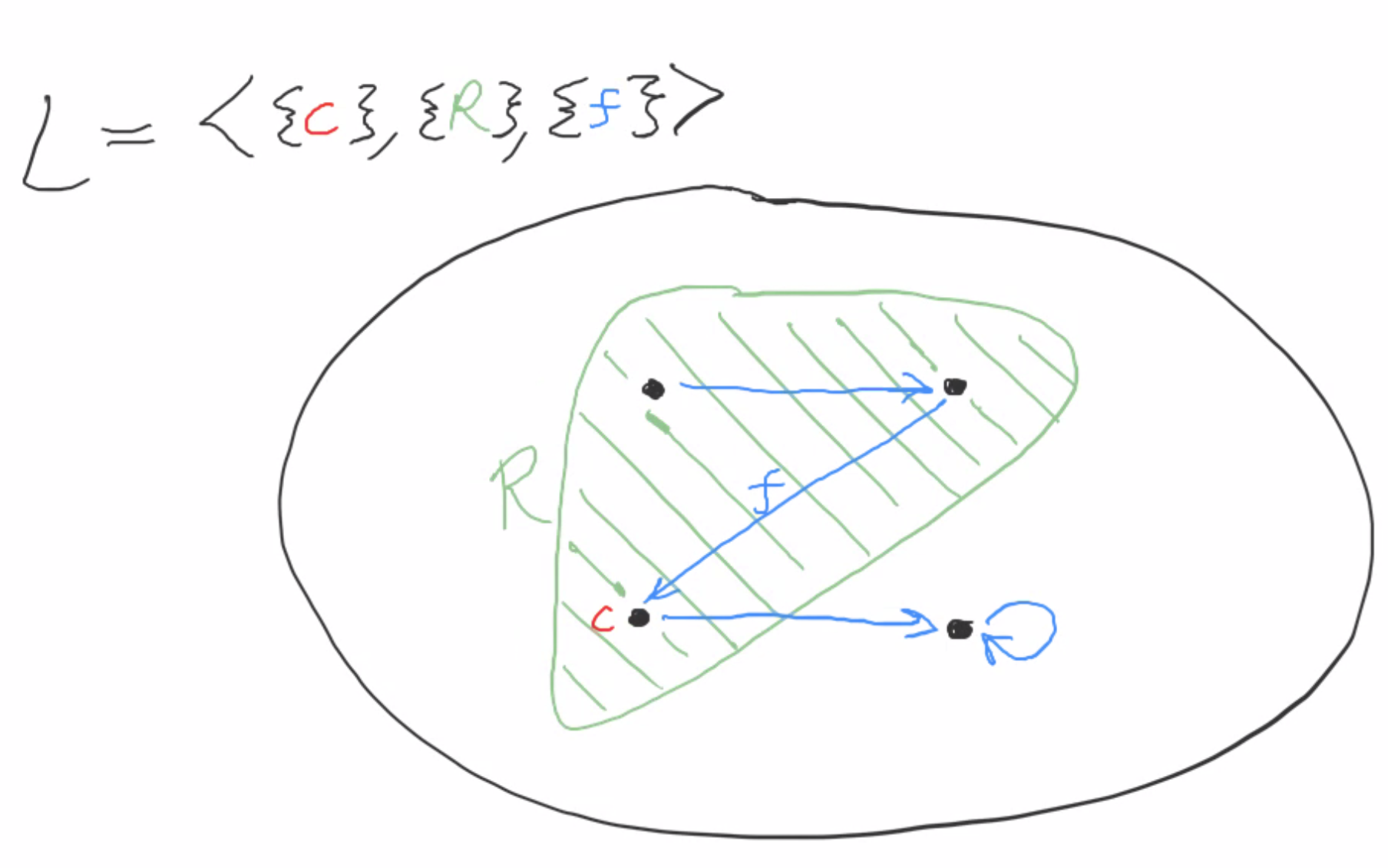
We have four elements, so we use four variables, x1 x2 x3 and x4 to specify the structure.
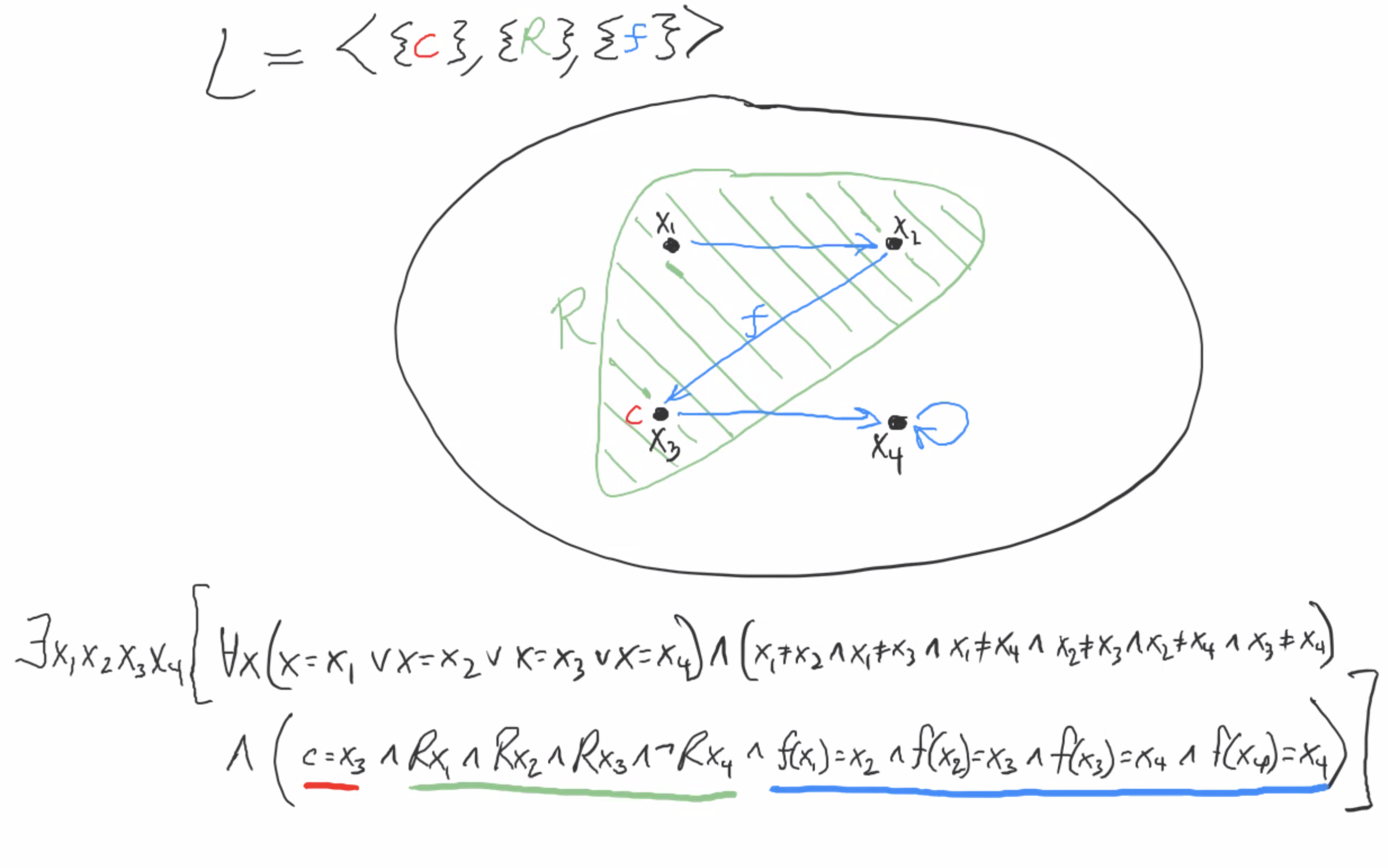
Since M satisfies this sentence, Łoś tells us that MI/U also affirms this sentence, meaning that MI/U and M are isomorphic. So in other words, every finite structure is its own ultrapower (up to isomorphism).
What about infinite structures? The situation is the exact opposite! No infinite structure is its own ultrapower.
Let M be an infinite structure and *M be its ultrapower. Add a constant for every object in M. The ultraproduct construction tells you how constants from M translate to constants in *M: for each constant c, if c refers to m in M, then c refers to [m, m, m, …] in *M.
Now we want to construct a new element of *M by writing a sequence that contains infinitely many elements of M, each appearing only finitely many times. Crucially, here we must assume that the index set is the same size as or smaller than M! If we have too many indices, then we aren’t going to be able to refer to each element in our original model only a finite number of times. So for instance, this argument won’t work for the ultrapower ℕℝ/U.
Now, this new element we’ve constructed is distinct from each constant, because they only agree in finitely many place. The constants covered all of M, but they don’t cover all of *M. So M and *M are not isomorphic!
And some more
These next results relate ultraproducts to compactness and definability.
Fix a first-order language L and consider a class C of L-structures. Say that a set of sentences X is C-satisfiable if there’s a structure in C that satisfies all of X. We say that C is compact if for every set A of L-formulas, finite C-satisfiability implies C-satisfiability. This is a different notion from the compactness discussed in the compactness theorem; the ordinary compactness theorem tells us that for every first-order language L, the class of all L-structures is compact. But it doesn’t tell us anything about other more restricted classes of L-structures.
For instance, let L be the language with an empty signature (no constants, functions or relations). This language is extremely simple: essentially the only contentful sentences you can make are about finite cardinalities. E.g. you can say “there are at least three things” with “∃x ∃y ∃z (x≠y ∧ x≠z ∧ y≠z)” and “there are at most three things” with “∀x ∀y ∀z ∀w (x=y ∨ x=z ∨ x=w ∨ y=z ∨ y=w ∨ z=w)”.
Now let C be the class of all finite L-structures. Is this class compact?
If you said no, good job! For a finite n, let φn be the sentence that says “there are at least n things”, and consider the set of sentences A = {φ1, φ2, φ3, …}. Every finite subset of A is satisfiable by a finite L-structure, but the entire set is clearly not satisfiable by any finite L-structure.
What if we add to C a single countably infinite L-structure M? Then our previous construction no longer works; the entire set A is now satisfied by this new member of C.
Alright, so that’s compactness for classes of structures. The relationship between this and ultraproducts is the following:
Any class of models that’s closed under ultraproducts is also compact.
For any language L and any finite n, consider the class of all L-structures of size n. The ultraproduct of a bunch of size-n L-structures is itself a size-n L-structure, so this class is closed under ultraproducts. And therefore it’s compact!
Now consider our example of the class of all finite structures in the language with empty signature. This was not compact, meaning that it cannot be closed under ultraproducts. This means that the ultraproduct of a bunch of finite structures is not necessarily finite! In particular, suppose that M1 has one element, M2 has two elements, M3 has three elements, and so on. Then the ultraproduct of (M1, M2, M3, …) will be an infinite model. We can also see this by applying Łoś’s theorem to the set of sentences {“There is at least 1 thing.”, “There are at least 2 things.”, “There are at least 3 things.”, …}.
A class C of L-structures is first-order definable if it is the set of all models of some set of L-sentences. First-order definability also relates to ultraproducts, in the following way:
If a class of L-structures is first-order definable, then it’s closed under ultraproducts.
The converse of this is that any class of structures that’s not closed under ultraproducts is not definable.
For any L, the class of finite L-structures is not closed under ultraproducts, so it’s not definable. This tells us that “finiteness” is not first-order definable.
The class of all models of PA is first-order definable, so it’s closed under ultraproducts. This means that even if you take an ultraproduct of infinitely many nonstandard models of PA, you still end up with a model of PA!
Okay, next up we come to the most exciting and powerful property of ultraproducts: countable saturation!