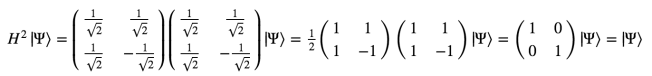A few posts ago, I talked about how quantum mechanics entails the existence of irreducible states – states of particles that in principle cannot be described as the product of their individual components. The classic example of such an entangled state is the two qubit state
![]()
This state describes a system which is in an equal-probability superposition of both particles being |0⟩ and both particles being |1⟩. As it turns out, this state cannot be expressed as the product of two single-qubit states.
A friend of mine asked me a question about this that was good enough to deserve its own post in response. Start by imagining that Alice and Bob each have a coin. They each put their quarter inside a small box with heads facing up. Now they close their respective boxes, and shake them up in the exact same way. This is important! (as well as unrealistic) We suppose that whatever happens to the coin in Alice’s box, also happens to the coin in Bob’s box.
Now we have two boxes, each of which contains a coin, and these coins are guaranteed to be facing the same way. We just don’t know what way they are facing.
Alice and Bob pick up their boxes, being very careful to not disturb the states of their respective coins, and travel to opposite ends of the galaxy. The Milky Way is 100,000 light years across, so any communication between the two now would take a minimum of 100,000 years. But if Alice now opens her box, she instantly knows the state of Bob’s coin!
So while Alice and Bob cannot send messages about the state of their boxes any faster than 100,000 years, they can instantly receive information about each others’ boxes by just observing their own! Is this a contradiction?
No, of course not. While Alice does learn something about Bob’s box, this is not because of any message passed between the two. It is the result of the fact that in the past the configurations of their coins were carefully designed to be identical. So what seemed on its face to be special and interesting turns out to be no paradox at all.
Finally, we get to the question my friend asked. How is this any different from the case of entangled particles in quantum mechanics??
Both systems would be found to be in the states |00⟩ and |11⟩ with equal probability (where |0⟩ is heads and |1⟩ is tails). And both have the property that learning the state of one instantly tells you the state of the other. Indeed, the coins-in-boxes system also has the property of irreducibility that we talked about before! Try as we might, we cannot coherently treat the system of both coins as the product of two independent coins, as doing so will ignore the statistical dependence between the two coins.
(Which, by the way, is exactly the sort of statistical dependence that justifies timeless decision theory and makes it a necessary update to decision theory.)
I love this question. The premise of the question is that we can construct a classical system that behaves in just the same supposedly weird ways that quantum systems behave, and thus make sense of all this mystery. And answering it requires that we get to the root of why quantum mechanics is a fundamentally different description of reality than anything classical.
So! I’ll describe the two primary disanalogies between entangled particles and “entangled” coins.
Epistemic Uncertainty vs Fundamental Indeterminacy
First disanalogy. With the coins, either they are both heads or they are both tails. There is an actual fact in the world about which of these two is true, and the probabilities we reference when we talk about the chance of HH or TT represent epistemic uncertainty. There is a true determinate state of the coins, and probability only arises as a way to deal with our imperfect knowledge.
On the other hand, according to the mainstream interpretation of quantum mechanics, the state of the two particles is fundamentally indeterminate. There isn’t a true fact out there waiting to be discovered about whether the state is |00⟩ or |11⟩. The actual state of the system is this unusual thing called a superposition of |00⟩ and |11⟩. When we observe it to be |00⟩, the state has now actually changed from the superposition to the determinate state.
We can phrase this in terms of counterfactuals: If when we look at the coins, we see that they are HH, then we know that they were HH all along. In particular, we know that if we had observed them a moment later or earlier, we would have gotten H with 100% certainty. Give that we actually observed HH, the probability that we would have observed HH is 100%.
But if we observe the state of the particles to be |00⟩, this does not mean that had we observed it a moment before, we would be guaranteed to get the same answer. Given that we actually observed |00⟩, the probability that we would have observed |00⟩ is still 50%.
(A project for some enterprising reader: see what the truths of these counterfactuals imply for an interpretation of quantum mechanics in terms of Pearl-style causal diagrams. Is it even possible to do?)
Predictive differences
The second difference between the two cases is a straightforward experimental difference. Suppose that Alice and Bob identically prepare thousands of coins as we described before, and also identically prepare thousands of entangled particles. They ensure that the coins are treated exactly the same way, so that they are guaranteed to all be in the same state, and similarly for the entangled pairs.
If they now just observe all of their entangled pairs and coins, they will get similar results – roughly half of the coins will be HH and roughly half of the entangled pairs will be |00⟩. But there are other experiments they could run on the entangled pairs that would give different answers depending on whether we treat the particles as being in superposition or not. I described what these experiments could be in this earlier post – essentially they involve applying an operation that takes qubits in and out of superposition. The conclusion of this is that even if you tried to model the entangled pair as a simple probability distribution similar to the coins, you will get the wrong answer in some experiments.
So we have both a theoretical argument and a practical argument for the difference between these two cases. They key take-away is the following:
According to quantum mechanics an entangled pair is in a state that is fundamentally indeterminate. When we describe it with probabilities, we are not saying “This probabilistic description is an account of my imperfect knowledge of the state of the system”. We’re saying that nature herself is undecided on what we will observe when we look at the state. (Side note: there is actually a way to describe epistemic uncertainty in quantum mechanics. It is called the density matrix, and is distinct from the description of superpositions.)
In addition, the most fundamental and accurate probability description for the state of the two particles is one that cannot be described as the product of two independent particles. This is not the case with the coins! The most fundamental and accurate probability description for the state of the two coins is either 100% HH or 100% TT (whichever turns out to be the case). What this means is that in the quantum case, not only is the state indeterminate, but the two particles are fundamentally interdependent – entangled. There is no independent description of the individual components of the system, there is only the system as a whole.