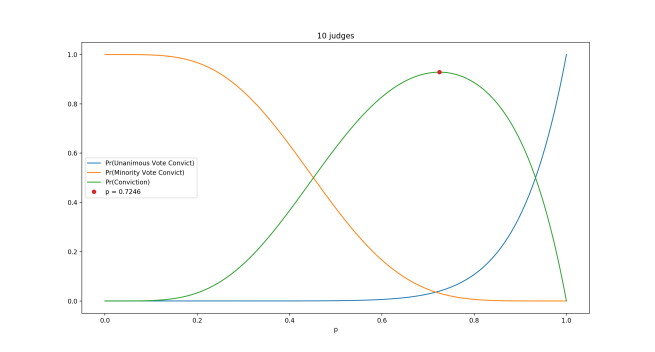
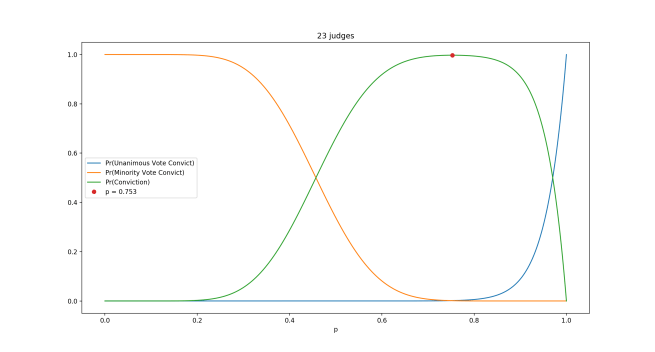
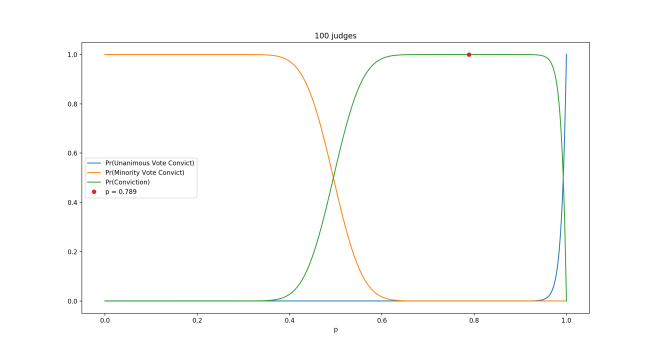
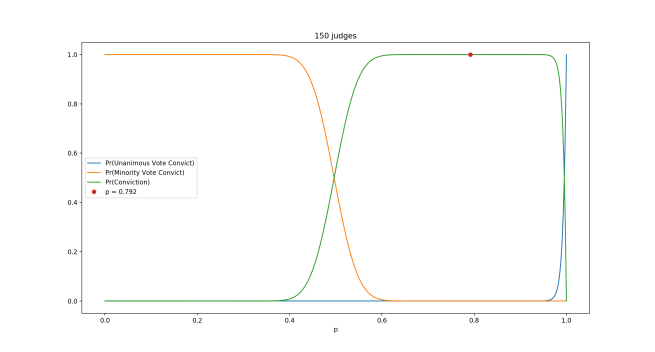
The Toolkit
- The Group Axioms
- Closure: ∀a,b ∈ G, a•b ∈ G
- Associativity: ∀a,b,c ∈ G, (a•b)•c = a•(b•c)
- Identity: ∃e ∈ G s.t. ∀a ∈ G, e•a = a•e = a
- Inverses: ∀a ∈ G, ∃a’ ∈ G s.t. a’•a = e
- Cancellation Rule
(a•b = a•c) ⇒ (b = c)
- Order Doesn’t Matter
You can write a Cayley table with the elements in any order that’s convenient.
- Sudoku Principle
Each row and column in the Cayley table for a group G contains every element in G exactly once.
- Lagrange’s Theorem
H ≤ G ⇒ |G| is divisible by |H|
- Elements Generate Subgroups
∀g ∈ G, <g> = {gk for all integer k} ≤ G.
(|<g>| = n) ⇒ (gn = e).
- Cauchy’s Theorem
(|G| = pk for prime p) ⇒ (∃g ∈ G s.t. gp = e)
- Classification of Finite Abelian Groups
Every finite abelian group is isomorphic to Zn or direct products of Zn
- Orbit-Stabilizer Theorem
|orb(x)||stab(x)| = |G|
- Partition Equation
∑|orb(x)| = |X|. The sum is taken over one representative for each orbit.
- Center is a Normal Subgroup
Z(G), the center of G, is a normal subgroup. So G/Z is a group.
- Class Equation
|G| = |Z| + ∑|Cl(x)|, where all terms divide |G| and each |Cl(x)| is neither 1 nor |G|. The sum is taken over non-central representatives of conjugacy classes.
- G/Z is Cyclic Implies G is Abelian
G/Z is cyclic ⇒ G is abelian
- Size of Product of Subgroups
|AB| = |A| |B| / |A ∩ B|
- Sylow’s First Theorem
If |G| = pnk for prime p and k not divisible by p, then G has a subgroup of size pn.
- Sylow’s Third Theorem
If |G| = pnk for prime p and k not divisible by p, then the number of subgroups of size pn must be 1 mod p, and must divide k.
Exercises
Example 1: Solving the group of size 3
Suppose |G| = 3. By the Identity Axiom (1.3), G has an identity element e. Call the other two elements a and b. So G = {e, a, b}. Let’s write out the Cayley table for the group:
By the Cancellation Rule (2), a•a ≠ a. By Lagrange’s Theorem (5), a•a ≠ e, as then the set {e, a} would be a subgroup of size 2, which doesn’t divide 3. Therefore by Closure (1.1), a•a = b.
We can fill out the rest of the Cayley table by the Sudoku principle (4).
|
e |
a |
b |
| e |
e |
a |
b |
| a |
a |
b |
e |
| b |
b |
e |
a |
Example 2: Solving the group of size 5
|
e |
a |
b |
c |
d |
| e |
e |
a |
b |
c |
d |
| a |
a |
|
|
|
|
| b |
b |
|
|
|
|
| c |
c |
|
|
|
|
| d |
d |
|
|
|
|
If a•a = e, then {e,a} would be a subgroup of size 2. By Lagrange’s theorem, then, a•a ≠ e. Also, by the Sudoku principle, a•a ≠ a. Thus we can choose the order of the rows/columns such that a•a = b (3).
|
e |
a |
b |
c |
d |
| e |
e |
a |
b |
c |
d |
| a |
a |
b |
|
|
|
| b |
b |
|
|
|
|
| c |
c |
|
|
|
|
| d |
d |
|
|
|
|
Now look at a•b = a•(a•a) = a3. If a3 = e, then <a> would be a subgroup of size 3 (by 6). 3 doesn’t divide 5, so a•b ≠ e (Lagrange’s theorem again). By the Sudoku principle, a•b also isn’t a or b. So we can arrange the Cayley table so that a•b = c. Since a•b = a3 = b•a, b•a = c as well.
|
e |
a |
b |
c |
d |
| e |
e |
a |
b |
c |
d |
| a |
a |
b |
c |
|
|
| b |
b |
c |
|
|
|
| c |
c |
|
|
|
|
| d |
d |
|
|
|
|
Now we can use the Sudoku principle to fill out the rest!
|
e |
a |
b |
c |
d |
| e |
e |
a |
b |
c |
d |
| a |
a |
b |
c |
d |
e |
| b |
b |
c |
d |
e |
a |
| c |
c |
d |
e |
a |
b |
| d |
d |
e |
a |
b |
c |
Example 3: Solving all groups of prime order
Suppose |G| = p, where p is some prime number. By Lagrange’s theorem every subgroup of G has either size 1 (the trivial subgroup {e}) or size p (G itself). Since the set generated by any element is a subgroup, any element g in G must have the property that |<g>| = 1 or p.
Choose g to be a non-identity element. <g> includes e and g, so |<g>| ≥ 2. So |<g>| = p. So <g> = G. So G is a cyclic group (generated by one of its elements). This fully specifies every entry in the Cayley table (gn•gm = gn+m), so there is only one group of size p up to isomorphism.
Example 4: Solving size 6 groups
Suppose |G| = 6.
By Cauchy’s theorem (7), there exists at least one element of order 2 and at least one element of order 3. Name the order-2 element a and the order-3 b. Fill in the Cayley table accordingly:
|
e |
a |
b |
? |
? |
? |
| e |
e |
a |
b |
|
|
|
| a |
a |
e |
|
|
|
|
| b |
b |
|
|
|
|
|
| ? |
|
|
|
|
|
|
| ? |
|
|
|
|
|
|
| ? |
|
|
|
|
|
|
Suppose b2 = a. Then (b2)2 = a2 = e, so b is order 4. But b is order 3. So b2 ≠ a. Also, b2 ≠ e for the same reason, and ≠ b by the Cancellation Rule . So b2 is something new, which we’ll put in our next column:
|
e |
a |
b |
b2 |
? |
? |
| e |
e |
a |
b |
b2 |
|
|
| a |
a |
e |
|
|
|
|
| b |
b |
|
b2 |
|
|
|
| b2 |
b2 |
|
|
|
|
|
| ? |
|
|
|
|
|
|
| ? |
|
|
|
|
|
|
b3 = e, so we can fill out b • b2 and b2 • b, as well as b2 • b2 = b3 • b = b
|
e |
a |
b |
b2 |
? |
? |
| e |
e |
a |
b |
b2 |
|
|
| a |
a |
e |
|
|
|
|
| b |
b |
|
b2 |
e |
|
|
| b2 |
b2 |
|
e |
b |
|
|
| ? |
|
|
|
|
|
|
| ? |
|
|
|
|
|
|
By the Sudoku principle, we can clearly see that a • b is none of e, a, b, or b2. So whatever it is, we’ll put it in the next column as “ab”:
|
e |
a |
b |
b2 |
ab |
? |
| e |
e |
a |
b |
b2 |
ab |
|
| a |
a |
e |
ab |
|
|
|
| b |
b |
|
b2 |
e |
|
|
| b2 |
b2 |
|
e |
b |
|
|
| ab |
ab |
|
|
|
|
|
| ? |
|
|
|
|
|
|
Looking at a•b2, we can again see that it is none of the elements we’ve identified so far. So whatever it is, we’ll put it in the next column as “ab2”.
|
e |
a |
b |
b2 |
ab |
ab2 |
| e |
e |
a |
b |
b2 |
ab |
ab2 |
| a |
a |
e |
ab |
ab2 |
|
|
| b |
b |
|
b2 |
e |
|
|
| b2 |
b2 |
|
e |
b |
|
|
| ab |
ab |
|
|
|
|
|
| ab2 |
ab2 |
|
|
|
|
|
Associativity (1.2) allows us to use the algebraic rules a2 = e and b3 = e to fill in a few more spots (like a•ab = a2b = b).
|
e |
a |
b |
b2 |
ab |
ab2 |
| e |
e |
a |
b |
b2 |
ab |
ab2 |
| a |
a |
e |
ab |
ab2 |
b |
b2 |
| b |
b |
|
b2 |
e |
|
|
| b2 |
b2 |
|
e |
b |
|
|
| ab |
ab |
|
ab2 |
a |
|
|
| ab2 |
ab2 |
|
a |
ab |
|
|
Now everything else in the table is determined by a single choice: should we assign b•a to ab, or to ab2? Each leads to a Cayley table consistent with the axioms, so we write them both out, using the Sudoku principle to finish each one entirely.
Group 1: (ba = ab)
|
e |
a |
b |
b2 |
ab |
ab2 |
| e |
e |
a |
b |
b2 |
ab |
ab2 |
| a |
a |
e |
ab |
ab2 |
b |
b2 |
| b |
b |
ab |
b2 |
e |
ab2 |
a |
| b2 |
b2 |
ab2 |
e |
b |
a |
ab |
| ab |
ab |
b |
ab2 |
a |
b2 |
e |
| ab2 |
ab2 |
b2 |
a |
ab |
e |
b |
Group 2: (ba = ab2)
|
e |
a |
b |
b2 |
ab |
ab2 |
| e |
e |
a |
b |
b2 |
ab |
ab2 |
| a |
a |
e |
ab |
ab2 |
b |
b2 |
| b |
b |
ab2 |
b2 |
e |
a |
ab |
| b2 |
b2 |
ab |
e |
b |
ab2 |
a |
| ab |
ab |
b2 |
ab2 |
a |
e |
b |
| ab2 |
ab2 |
b |
a |
ab |
b2 |
e |
These two groups are clearly not isomorphic, as one is commutative and the other not. This proves that there are two groups of size 6 up to isomorphism!
Example 5: Solving groups of prime order, again
Suppose |G| = p, where p is some prime number. The center of G, Z(G), is a subgroup of G (by 11). So by Lagrange’s theorem, |Z| = 1 or p.
By the Class Equation (12), |G| = |Z| + ∑|Cl(x)|. All terms divide p and each |Cl(x)| ≠ 1, so we have p = |Z| + ∑p. This is only possible if |Z| = 0 or there are no non-central elements. Z contains e, so |Z| ≠ 0. So there are no non-central elements. Thus G = Z, which is to say G is abelian.
By the Classification of Finite Abelian Groups (8), G is isomorphic to Zp.
Example 6: Prime power groups have non-trivial centers
Suppose |G| = pn, where p is some prime number and n is some positive integer. The Class Equation tells us that |G| = |Z| + ∑|Cl(x)|, where |Z| = 1, p, p2, …, or pn and each |Cl(x)| = p, p2, …, or pn-1. Taking the Class Equation modulo p we find that |Z| = 0 (mod p), so |Z| cannot be 1. So G has a non-trivial center!
Example 7: Solving groups of prime-squared order
Suppose |G| = p2, where p is some prime number. The Class Equation tells us that |G| = |Z| + ∑|Cl(x)|, where |Z| = 1, p, or p2 and each |Cl(x)| = p. So we have p2 = |Z| + ∑p. Taking this equation mod p we find that |Z| = 0 (mod p), so |Z| is non-trivial. (This is just a special case of Example 6 above.) So |Z| = p or p2.
Suppose |Z| = p. Then |G/Z| = p2/p = p. So G/Z is cyclic. But then G is abelian (by 13). So G = Z, which implies that |Z| = p2. Contradiction. So |Z| = p2, i.e. G is abelian.
By the classification of finite abelian groups we see that there are two possibilities: G is isomorphic to integers mod p2 or G is isomorphic to Zp x Zp. These are the only two groups (up to isomorphism) of size p2.
Example 8: Proving Cauchy’s Theorem
Suppose |G| = n, where n is divisible by some prime p.
Let X be the subset of p-tuples of elements from G whose product is e. That is, X = {(g1,g2,…,gp) ∈ Gp s.t. g1g2…gp = e}. Notice that the number of elements in X is |G|p-1 (there are |G| choices for each of the first p-1 elements, and then the final one is fully determined by the constraint). Let the integers mod p (Zp) act on X by the following rule: the action of 1 on an element of X is 1 • (g1,g2,…,gp) = (gp,g1,g2,…,gp-1). (From this we can deduce the action of all the other integers mod p.)
By the Orbit Stabilizer Theorem (9), the possible orbit sizes for this action must divide the size of the cyclic group. That is, for every x ∈ X, |orb(x)| = 1 or p. Let r be the number of orbits of size 1 and s be the number of orbits of size p. Then by the Partition Equation (10), we have r + sp = |X| = |G|p-1. By our starting assumption, we have that the right hand side is divisible by p. And since sp is divisible by p, r must also be divisible by p. That is, r = 0, or p, or 2p, and so on.
Notice that the p-tuple (e,e,…,e) is in X, and that its orbit size is 1. So r is at least 1. So r = p, or 2p, and so on. That means that there is at least one more element of X with orbit size 1. This element must look like (a,a,…,a) for some a ∈ G. And since it’s in X, it must satisfy our constraint, namely: ap = e! So there is at least one non-identity element of order p.
Example 9: Subgroups of Group of Size 20
Suppose |G| = 10 = 22*5
By Cauchy’s Theorem and Sylow’s First Theorem (15), we know there must be subgroups of size 2, 4, and 5. We can learn more about the number of subgroups of sizes 4 and 5 using Sylow’s Third Theorem (16).
If N is the number of subgroups of size 4, then N divides 5 (1 or 5), and N = 1 (mod 2). So N = 1 or 5.
If N is the number of subgroups of size 5, then N divides 4 (1, 2, 4), and N = 1 (mod 5). So N = 1.
Example 10: Subgroups of Group of Size p2q
Suppose |G| = p2q, for primes p and q where 2 < p < q and q-1 is not a multiple of p.
Then by (15) we have subgroups of size p2 and q. Again, we use (16) to learn more about these subgroups.
If N is the number of subgroups of size p2, then N divides q (1 or q), and N = 1 (mod p). q ≠ 1 (mod p), N cannot be q. So N = 1.
If N is the number of subgroups of size q, then N divides p2 (1, p, or p2), and N = 1 (mod q) (so N is 1, or q+1, or 2q+1, and so on). But p is smaller than q, so N can’t be p. And if N = p2, then p2 – 1 must be a multiple of q. But p2 – 1 = (p+1)(p-1). Both of these values are too small to contain factors of q. So their product cannot be a multiple of q. So N ≠ p2 either. So N = 1!
Example 11: Subgroups of Group of Size pqn
Suppose |G| = pqn, where p and q are primes and 2 < p < q.
Using Sylow III (16): If N is the number of subgroups of size qn, then N divides p (1 or p) and N = 1 (mod q). p is too small to be a multiple of q plus 1, So N = 1.
Example 12: Classifying Groups of Size 2p
Suppose |G| = 2p for some prime p > 2. Let’s use everything in our toolkit to fully classify the possibilities!
By Cauchy, we have elements of of order 2 and p. Let a be an element of order 2 and b an element of order p. Let A = <a> = {e, a} and B = <b> = {e, b, b2, …, bp-1}. A and B are both cyclic of different orders, so their intersection is trivial. So by (14), |AB| = |A| |B| / |A ∩ B| = 2p. So AB = G. This means we can write all the elements of G as follows:
|
e |
b |
b2 |
… |
bp-1 |
| e |
e |
b |
b2 |
… |
bp-1 |
| a |
a |
ab |
ab2 |
… |
abp-1 |
So G = {e, b, b2, …, bp-1, a, ab, ab2, …, abp-1}. Call N2 the number of subgroups of size 2 and Np the number of subgroups of size p. Applying Sylow III, it is easy to see that there are two possibilities: (N2 = 1 and Np = 1), or (N2 = p and Np = 1).
Case 1: N2 = p and Np = 1.
Since N2 = p and Np = 1, there are p elements of order 2 (one for each subgroup) and p-1 elements of order p. Adding in e, this accounts for all of G.
Order 1: e
Order p: b, b2, …, bp-1
Order 2: a, ab, ab2, …, abp-1 (the remaining members of G)
Now, since a and b are in G, so must be ba. And since G = AB, ba ∈ AB. It’s not e or a power of b (apply the Cancellation Rule), so ba must be abn for some n. This means that ba is order 2, so (ba)2 = e. Expanding and substituting, we get (ba)2 = (ba)(ba) = (ba)(abn) = ba2bn = bn+1 = e = bp.
So n = p – 1, or in other words, ba = abp-1. This actually allows us to fully fill out the rest of the Cayley table, as we can take any expression and move the ‘b’s all the way to the right, ending up with something that looks like anbm. This is the dihedral group of degree p (the group of symmetries of a regular p-gon)!
Case 2: N2 = 1 and Np = 1.
Order 1: e
Order p: b, b2, …, bp-1
Order 2: a
No other elements can be order 1, 2, or p, so all other elements must be order 2p (think Lagrange’s theorem). For instance, (ab)2p = e and (ab)p ≠ e . You can show that this only works if ab = ba, which allows you to freely move ‘a’s and ‘b’s around in any expression. ((ab)2p = a2p b2p = (a2)p (bp)2 = e, and (ab)p = ap bp = ap = a ≠ e).
Again, we can use this to fill out the entire Cayley table. The group we get is isomorphic to Z2p (the integers mod 2p)!
So if |G| = 2p for some prime p > 2, then G is either the group of symmetries of a regular p-gon, or it’s the integers mod p. Fantastic! If you follow this whole line of reasoning, then I think that you have a good grasp of how to use the toolkit above.