Mathematical logic is the study of the type of reasoning we perform when we do mathematics, and the attempt to formulate a general language as the setting in which all mathematics is done. In essence, it is an attempt to form a branch of mathematics, of which all other branches of mathematics will emerge as special cases.
You might sort of think that when speaking at this level of abstraction, there will nothing general and interesting to say. After all, we’re trying to prove statements not within a particular domain of mathematics, but theorems that are true across a wide swath of mathematics, potentially encompassing all of it.
The surprising and amazing thing is that this is not the case. It turns out that there are VERY general and VERY surprising things you can discover by looking at the logical language of mathematics, a host of results going by names like the Completeness Theorem, the Incompleteness Theorem, the Compactness Theorem, the Löwenheim-Skolem Theorem, and so on. These results inevitably have a great deal of import to our attitudes towards the foundations of mathematics, being that they generally establish limitations or demonstrate eccentricities in the types of things that we can say in the language of mathematics.
My goal in this post is to provide a soft introduction to the art of dealing in mathematics at this level of ultimate abstraction, and then to present some of the most strange things that we know to be true. I think that this is a subject that’s sorely missing this type of soft introduction, and hope I can convey some of the subject’s awesomeness!
— — —
To start out with, why think that there is any subject matter to be explored here? Different branches of mathematics sometimes appear to be studying completely different types of structures. I remember an anecdote from an old math professor of mine, who worked within one very narrow and precisely defined area of number theory, and who told me that when she goes to talks that step even slightly outside her area of specialty, the content of the lectures quickly incomprehensible to her. Why think that there is such a common language of mathematics, if specialists in mathematics can’t even understand each other when talking between fields?
The key thing to notice here is that although different fields of mathematics are certainly wildly different in many ways, there nevertheless remain certain fundamental features that are shared in all fields. Group theorists, geometrists, and number theorists will all accept the logical inference rule of modus ponens (if P is true and P implies Q, then Q is true), but none of them will accept its converse (if Q is true and P implies Q, then P is true). No matter what area of mathematics you study, you will accept that if P(x) is true for all x, then it is true for any particular x you choose. And so on. These similarities may seem obvious and trivial, but they HAVE to be obvious and trivial to be things that every mathematician agrees on. The goal, then, is to formalize a language that has these fundamental inference rules and concepts built in, and that has many special cases to account for the differences between domains of math, specified by some parameters that are freely chosen by any user of the system.
There are actually several distinct systems that attempt to accomplish this task. Generally speaking, there are three main branches, in order of increasing expressive power: propositional logic, first order (predicate) logic, and second order logic.
Reasoning In Zeroth Order
Let’s start with propositional logic, sometimes called “zeroth order logic.” Propositional logic is the framework developed to deal with the validity of the following types of arguments:
Argument 1
- 2+2=4.
- If 2+2=4, then 1+3=4.
- So 1+3=4.
Argument 2
- The Riemann hypothesis is false and P = NP.
- So P = NP.
Notice that it doesn’t matter if our premises are true or not. Logical validity doesn’t care about this, it just cares that the conclusions really do follow from the premises. This is a sign of the great generality at which we’re speaking. We’re perfectly fine with talking about a mathematical system in which the Riemann hypothesis is false, or in which 2+2 is not 4, just so long as we accept the logical implications of our assumptions.
Propositional logic can express the validity of these arguments by formalizing rules about valid uses of the concepts ‘and’, ‘if…then…’, ‘or’, and so on. It remains agnostic to the subject matter being discussed by not fully specifying the types of sentences that are allowed to be used in the language. Instead, any particular user of the language can choose their set of propositions that they want to speak about.
To flesh this out more, propositional logic fulfills the following three roles:
- Defines an alphabet of symbols.
- Specifies a set of rules for which strings are grammatical and which are not.
- Details rules for how to infer new strings from existing strings.
In more detail:
- The set of symbols in propositional logic are split into two categories: logical symbols and what I’ll call “fill-in-the-blank” symbols. The logical symbols are (, ), ∧, ∨, ¬, and →. The fill-in-the-blank symbols represent specific propositions, that are specified by any particular user of the logic.
- Some strings are sensible and others not. For example, the string “P∧∧” will be considered to be nonsensical, while “P∧Q” will not. Some synonyms for sensible strings are well-formed formulas (WFFs), grammatical sentences, and truth-apt sentences. There is a nice way to inductively generate the set of all WFFs: Any proposition is a WFF, and for any two WFFs F and F’, the following are also WFFs: (F∧F’), (F∨F’), ¬F, (F→F’).
- These include rules like modus ponens (from P and P→Q, derive Q), conjunction elimination (from P∧Q, derive P), double negation elimination (from ¬¬P, derive P), and several more. They are mechanical rules that tell you how to start with one set of strings and generate new ones in a logically valid way, such that if the starting strings are true than the derived ones must also be true. There are several different but equivalent formulations of the rules of inference in propositional logic.
A propositional language fills in the blanks in the logic. Say that I want to talk about two sentences using propositional logic: “The alarm is going off”, “A robber has broken in.” For conciseness, we’ll abbreviate these two propositions as A for alarm and R for robber. All I’ll do to specify my language is to say “I have two propositions: {A, R}”
The next step is to fill in some of the details about the relationships between the propositions in my language. This is done by supplementing the language with a set of axioms, and we call the resulting constrained structure a propositional theory. For instance, in my example above we might add the following axioms:
- A→R
- A∨R
In plain English, these axioms tell us that (1) if the alarm is going off, then a robber has broken in, and (2) an alarm is going off or a robber has broken in.
Finally, we talk about the models of our theory. Notice that up until now, we haven’t talked at all about whether any statements are true or false, just about syntactic properties like “The string P∨¬ is not grammatical” and about what strings follow from each other. Now we interpret our theory by seeing what possible assignments of truth values to the WFFs in our language are consistent with our axioms and logical inference rules. In our above example, there are exactly two interpretations:
Model 1: A is true, R is true
Model 2: A is false, R is true
These models can be thought of as the possible worlds that are consistent with our axioms. In one of them, the alarm has gone off and a robber has broken in, and in the other, the alarm hasn’t gone off and the robber has broken in.
Notice that R turns out true in both models. When a formula F is true in all models of a theory, we say that the theory semantically entails F, and write this as T ⊨ F. When a formula can be proven from the axioms of the theory using the rules of inference given by the logic, then we say that the theory syntactically entails F, and write this as T ⊢ F.
This distinction between syntax and semantics is really important, and will come back to us in later discussion of several important theorems (notably the completeness and incompleteness theorems). To give a sneak peek: above we found that R was semantically entailed by our theory. If you’re a little familiar with propositional logic, you might have also realized that R can be proven from the axioms. In general, syntactic truths will always be semantic truths (if you can prove something, then it must be true in all models, or else the models would be inconsistent. But a model is by definition a consistent assignment of truth values to all WFFs). But a natural question is: are all semantic consequences of a theory also syntactic consequences? That is, are all universal truths of the theory (things that are true in every model of the theory) provable from the theory?

If the answer is yes, then we say that our logic is complete. And it turns out that the answer is yes, for propositional logic. Whether more complex logics are complete turns out to be a more interesting question. More on this later.
This four-step process I just laid out (logic to language to theory to model) is a general pattern we’ll see over and over again. In general, we have the following division of labor between the four concepts:
- Logic: The logic tells us the symbols we may use (including some fill-in-the-blank categories of symbols), the rules of grammar, and a set of inference rules for deriving new strings from an existing set.
- Language: The language fills in the blanks in our logic, fully specifying the set of symbols we will be using.
- Theory: The theory adds axioms to the language.
- Model: A model is an assignment of truth values to all WFFs in the language, consistent with the axioms and the inference rules of our logic.
It’s about time that we apply this four-step division to a more powerful logic. Propositional logic is pretty weak. Not much interesting math can be done in a purely propositional language, and it’s wildly insufficient to capture our notion of logically valid reasoning. Consider, for example, the following argument:
- Socrates is a man.
- All men are mortal.
- So, Socrates is mortal.
This is definitely a valid argument. No rational agent could agree that 1 and 2 are true, and yet deny the truth of 3. But can we represent the validity of this argument in propositional logic? No!
Consider that the three sentences “Socrates is a man”, “All men are mortal”, and “Socrates is mortal” are distinct propositions, and the relationships between them are too subtle for propositional logic to capture. Propositional logic can’t see that the first proposition is asserting the membership of Socrates to a general class of things (“men”), and that the second proposition is then making a statement about a universal property of things in this class. It just sees two distinct propositions. To propositional logic, this argument just looks like
- P
- Q
- Therefore, R
But this is not logically valid! We could make it valid by adding as a premise the sentence (P∧Q)→R, which corresponds to the English sentence “If Socrates is a man and all men are mortal, then Socrates is mortal.” But this should be seen as a tautology, something that is provable in any first order theory that contains the propositions P Q and R, not a required additional assumption. Worse, if somebody came along and stated the proposition A = “Aristotle is a man”, then we would need a whole ‘nother assumption to assert that Aristotle is also mortal! And in general, for any individual instance of this argument, we’d need an independent explanation for its validity. This is not parsimonious, and indicative that propositional logic is missing something big.
Missing what? To understand why this argument is valid, you must be able to reason about objects, properties, and quantification. This is why we must move on to an enormously more powerful and interesting logic: first order logic.
Reasoning In First Order
First order logic is a logic, so it must fill the same three roles as we saw propositional logic did above. Namely, it must define the alphabet, the grammar, and the inference rules.
Symbols
Logical: ∧ ∨ ¬ → ( ) ∀ ∃ =
Variables: x y z w …
Constants: ______
Predicates: ______
Functions: ______
That’s right, in first order we have three distinct categories of fill-in-the-blank symbols. Intuitively, constants will be names that refer to objects, predicates will be functions from objects to truth values, and functions will take objects to objects. To take an everyday example, if the objects in consideration are people, then we might take ‘a’ to be a constant referring to a person named Alex, ’T’ to be a predicate representing ‘is tall’, and ‘f’ to be a function representing “the father of”. So T(a) is either true or false, while f(a) doesn’t have a truth value (it just refers to another object). But T(f(a)) does have a truth value, because it represents the sentence “Alex’s father is tall.”
Next, we define well-formed formulas. This process is more complicated than it was for propositional logic, because we have more types of things than we did before, but it’s not too bad. We start by defining a “term”. The set of terms is inductively generated by the following scheme: All constants and variables are terms, and any function of terms is itself a term. Intuitively, the set of terms is the set of objects that our language is able to “point at”.
With the concept of terms in hand, we can define WFFs through a similar inductive scheme: Any predicate of terms is a WFF. And for any WFFs F and F’, (F∧F’), (F∨F’), (¬F), (F→F’), ∀x F, ∃x F are all WFFs. The details of this construction are not actually that important, I just think it’s nice how you can generate all valid first order formulas from fairly simple rules.
Good! We have an alphabet, a grammar, and now all we need from our logic is a set of inference rules. It turns out that this set is just going to be the inference rules from propositional logic, plus some new ones:
Quantifier elimination: From ∀x P(x) derive P(t) (for any term t and predicate P)
Quantifier introduction: From P(t) derive ∃x P(x) (for any term t and predicate P)
That’s it, we’ve defined first order logic! Now let’s talk about a first order language. Just like before, the language is just obtained by filling in the blanks left open by our logic. So for instance, we might choose the following language:
Constants: a
Functions: f
Predicates: none
In specifying our function, we have to say exactly what type of function it is. Functions can take as inputs a single object (“the father of”) or multiple objects (“the nearest common ancestor of”), and this will make a difference to how they are treated. So for simplicity, let’s say that our function f just takes in a single object.
A first order theory will simply be a language equipped with some set of axioms. Using our language above, we might have as axioms:
- ∀x (f(x) ≠ x)
- ∀x (f(x) ≠ a)
In plain English, we’re saying that f never takes any object to itself or to a.
And lastly, we get to the models of a first order theory. There’s an interesting difference between models here and models in propositional logic, which is that to specify a first order model, you need to first decide on the size of your set of objects (the size of the ‘universe’, as it’s usually called), and then find a consistent assignment of truth values to all propositions about objects in this universe.
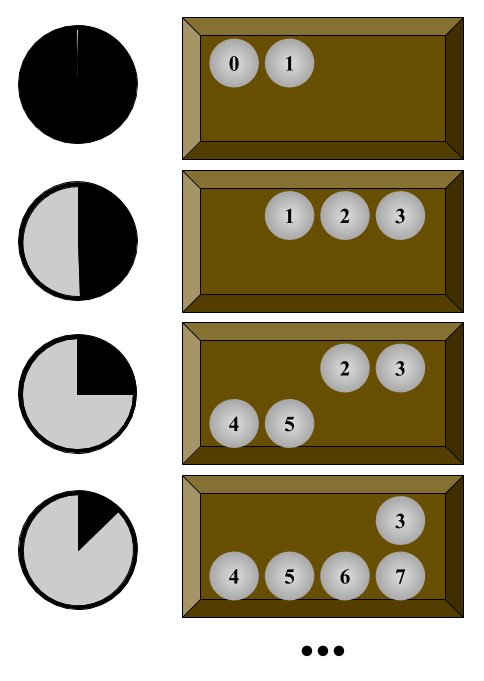
So, for instance, we can start searching for models of our theory above by starting with models with one object, then two objects, then three, and so on. We’ll draw little diagrams below in which points represent objects, and the arrow represents the action of the function f on an object.
- No 1-element universe.
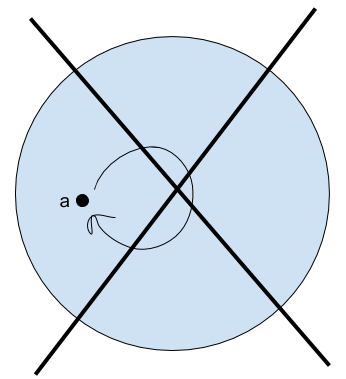
- No 2-element universe.

- 3-element universe

- 4 element universes




- And so on…
It’s a fun little exercise to go through these cases and see if you can figure out why there are no models of size 1 or 2, or why the one above is the only model of size 3. Notice, by the way, that in the last two images, we have an object for which there is no explicit term! We can’t get there just using our constant and our functions. Of course, in this case we can still be clever with our quantifiers to talk about the Nameless One indirectly (for instance, in both of these models we can refer to the object that is not equal to a, f(a), or f(f(a))) But in general, the set of all things in the universe is not going to be the same as the set of things in the universe that we can name.
Here’s a puzzle for you: Can you make a first order sentence that says “I have exactly four objects”? That is, can you craft a sentence that, if added as an axiom to our theory, will rule out all models besides the ones that have exactly four elements?
(…)
(Think about it for a moment before moving on…)
(…)
Here’s how to do it for a universe with two objects (as well as a few other statements of interest). The case of four objects follows pretty quickly from this.
- “I have at most two objects” = ∃x∃y∀z (z=x ∨ z=y)
- “I have exactly two objects” = ∃x∃y (x≠y ∧ ∀z(z=x ∨ z=y))
- “I have at least two objects” = ∃x∃y (x≠y)
Another puzzle: How would you say “I have an infinity of objects”, ruling out all finite models?
(…)
(Think about it for a moment before moving on…)
(…)
This one is trickier. One way to do it is to introduce an infinite axiom schema: “I have at least n objects” for each n.
This brings up an interesting point: theories with infinite axioms are perfectly permissible for us. This is a choice that we make that we could perfectly well deny, and end up with a different and weaker system of logic. How about infinitely long sentences? Are those allowed? No, not in any of the logics we’re talking about here. A logic in which infinite sentences are allowed is called an infinitary logic, and I don’t know too much about such systems (besides that propositional, first, and second order logics are not infinitary).
Okay… so how about infinitely long derivations? Are those allowed? No, we won’t allow those either. This one is more easy to justify, because if infinite derivations were allowed, then we could prove any statement P simply by the following argument “P, because P, because P, because P, because …”. Each step logically follows from the previous, and in any finite system we’d eventually bottom out and realize that the proof has no basis, but in a naive infinite-proof system, we couldn’t see this.
Alright, one last puzzle. How would you form the sentence “I have a finite number of objects”? I.e., suppose you want to rule out all infinite models but keep the finite ones. How can you do it?
(…)
(Think about it for a moment before moving on…)
(…)
This one is especially tricky, because it turns out to be impossible! (Sorry about that.) You can prove, and we will prove in a little bit, that no first order axiom (or even infinite axiom schema) is in general capable of restricting us to finite models. We have run up against our first interesting expressive limitation of first-order logic!
Okay, let’s now revisit the question of completeness that I brought up earlier. Remember, a logic is complete if for any theory in that logic, the theory’s semantic implications are the same as its syntactic implications (all necessary truths are provable). Do you think that first order logic is complete?
The answer: Yes! Kurt Gödel proved that it is in his 1929 doctoral dissertation. Anything that is true in all models of a first order theory, can be proven from the axioms of that theory (and vice versa). This is a really nice feature to have in a logic. It’s exactly the type of thing that David Hilbert was hoping would be true of mathematics in general. (“We must know. We will know!”) But this hope was dashed by the same Kurt Gödel as above, in his infamous incompleteness theorems.
There will be a lot more to say about that in the future, but I’ll stop this post for now. Next time, we’ll harness the power of first order logic to create a first order model of number theory! This will give us a chance to apply some powerful results in mathematical logic, and to discover surprising truths about the logic’s limitations.

















 . This number is either rational or irrational. Let’s examine each case.
. This number is either rational or irrational. Let’s examine each case.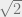 is irrational. So if
is irrational. So if 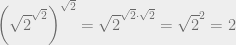
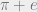 and
and 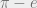 transcendental?
transcendental? and
and  are both transcendental numbers (i.e. they cannot be expressed as the roots of any polynomial with rational coefficients). But are
are both transcendental numbers (i.e. they cannot be expressed as the roots of any polynomial with rational coefficients). But are  would also not be transcendental, which we know is false! So we know that at least one of them has to be true, using a proof that doesn’t guarantee the truth of either of them! Cool, right?
would also not be transcendental, which we know is false! So we know that at least one of them has to be true, using a proof that doesn’t guarantee the truth of either of them! Cool, right?