This post is about the most startling puzzle I’ve ever heard. First, two warm-up hat puzzles.
Four prisoners, two black hats, two white hats
Four prisoners are in a line, with the front-most one hidden from the rest behind a wall. Each is wearing a hat, but they can’t see its color. There are two black hats and two white hats, and all four know this.

As soon as any prisoner figures out the color of their own hat, they must announce it. If they’re right, everybody goes free. They cannot talk to each other or look any direction but forwards.
Are they guaranteed freedom?
Solution
Yes, they are! If D sees the same color hat on B and C’s heads, then he can conclude his own hat’s color is the other, so everybody goes free. If he sees differently colored hats, then he cannot conclude his hat color. But C knows this, so if D doesn’t announce his hat color, then C knows that his hat color is different from B’s and they all go free. Done!
Next:
Ten prisoners, unknown number of black and white hats
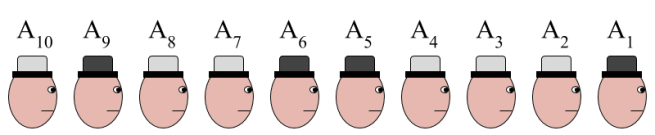
Each prisoner is randomly assigned a hat. The number of black and white hats is unknown. Starting from the back, each must guess their hat color. If it matches they’re released, and if not then they’re killed on the spot. They can coordinate beforehand, but cannot exchange information once the process has started.
There is a strategy that gives nine of the prisoners 100% chance of survival, and the other a 50% chance. What is it?
Solution
A10 counts the number of white hats in front of him. If it’s odd, he says ‘white’. Otherwise he says ‘black’. This allows each prisoner to learn their own hat color once they hear the prisoner behind them.
— — —
Alright, now that you’re all warmed up, let’s make things a bit harder.
Countably infinite prisoners, unknown number of black and white hats, no hearing
There are a countable infinity of prisoners lined up with randomly assigned hats. They each know their position in line.

The hat-guessing starts from A1 at the back of the line. Same consequences as before: the reward for a right guess is freedom and the punishment for a wrong guess is death.
The prisoners did have a chance to meet and discuss a plan beforehand, but now are all deaf. Not only can they not coordinate once the guessing begins, but they also have no idea what happened behind them in the line.
The puzzle for you is: Can you find a strategy that ensures that only finitely many prisoners are killed?
Oh boy, the prisoners are in a pretty tough spot here. We’ll give them a hand; let’s allow them logical omniscience and the ability to memorize an uncountable infinity of information. Heck, let’s also give them an oracle to compute any function they like.
Give it a try!
(…)
(…)
Solution
Amazingly, the answer is yes. All but a finite number of prisoners can be saved.
Here’s the strategy. First start out by identifying white hats with the number 0, and black hats with the number 1. Now the set of all possible sequences of hats in the line is the set of all binary sequences. We define an equivalence relation on such sequences as follows: 𝑥 ~ 𝑦 if and only if 𝑥 and 𝑦 are identical after a finite number of digits in the sequence. This will partition all possible sequences into equivalence classes.
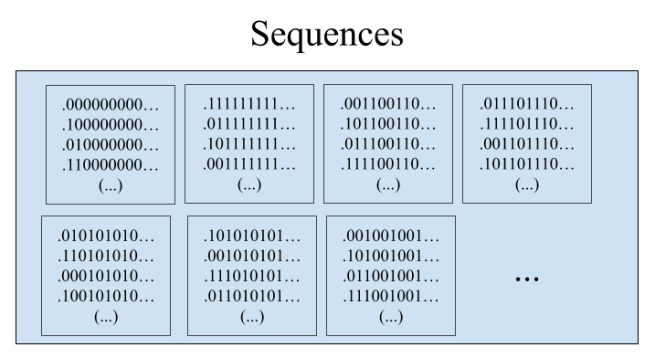
For example, the equivalence class of 0 will just be the subset of the rationals whose binary expansion ends at some point (i.e. the subset of the rationals that can be written as an integer over a power of 2). Why? Well, if a binary sequence 𝑥 is equivalent to .000000…, then after a finite number of digits of 𝑥, it will have to be all 0s forever. And this means that it can be written as some integer over a power of 2.
When the prisoners meet up beforehand, they use the axiom of choice to select one representative from each equivalence class. (Quick reminder: the axiom of choice says that for any set 𝑥 of nonempty disjoint sets, you can form a new set that shares exactly one element with each of the sets in 𝑥.) Now each prisoner is holding in their head an uncountable set of sequences, each one of which represents an equivalence class.
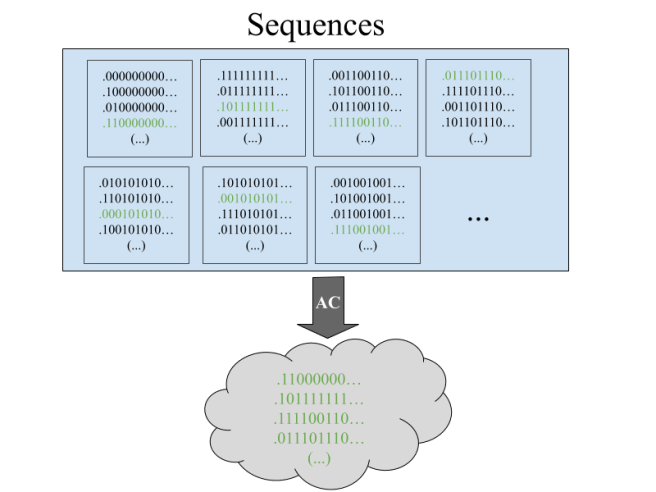
Once they’re in the room, every prisoner can see all but a finite number of hats, and therefore they know exactly which equivalence class the sequence of hats belongs to. So each prisoner guesses their hat color as if they were in the representative sequence from the appropriate equivalence class. Since the actual sequence and the representative sequence differ in only finitely many places (all at the start), all entries are going to be the same after some finite number of prisoners. So every single prisoner after this first finite batch will be saved!

This result is so ridiculous that it actually makes me crack up thinking about it. There is surely some black magic going on here. Remember, each prisoner can see all the hats in front of them, but they know nothing about the total number of hats of each color, so there is no correlation between the hats they see and the hat on their head. And furthermore, they are deaf! So they can’t learn any new information from what’s going on behind them! They literally have no information about the color of their own hat. So the best that each individual could do must be 50/50. Surely, surely, this means that there will be an infinite number of deaths.
But nope! Not if you accept the axiom of choice! You are guaranteed only a finite number of deaths, just a finite number that can be arbitrarily large. How is this not a contradiction? Well, for it to be a contradiction, there has to be some probability distribution over the possible outcomes which says that Pr(finite deaths) = 0. And it turns out that the set of representative sequences form a non-measurable set (a set which cannot have a well-defined size using the ordinary Lebesgue measure). So no probability can be assigned to it (not zero probability, literally undefined)! Now remember that zero deaths occur exactly when the real sequence is one of the representative sequences. This means that no probability can be assigned to this state of affairs. The same thing applies to the state of affairs in which one prisoner dies, or two prisoners, and so on. You literally cannot define a probability distribution over the number of prisoners to die.
By the way, what happens if you have an uncountable infinity of prisoners? Say we make them infinitely thin and then squeeze them along the real line so as to populate every point. Each prisoner can see all but a finite number of the other prisoner’s hats. Let’s even give them hats that have an uncountable number of different colors. Maybe we pick each hat color by just randomly selecting any frequency of visible light.
Turns out that we can still use the axiom of choice to guarantee the survival of all but finitely many prisoners!

One last one.
Countably infinite prisoners, unknown number of black and white hats, with hearing
We have a countable infinity of prisoners again, each with either a black or white hat, but this time they can hear the colors called out by previous prisoners. Now how well can they do?
The answer? (Assuming the axiom of choice) Every single prisoner can be guaranteed to survive except for the first one, who survives with 50% probability. I really want this to sink in. When we had ten prisoners with ten hats, they could pull this off by using their knowledge of the total number of black and white hats amongst them. Our prisoners don’t have this anymore! They start off knowing nothing about the number of white and black hats besides what they can see in front of them. And yet they still get out of it with all but one prisoner guaranteed freedom.
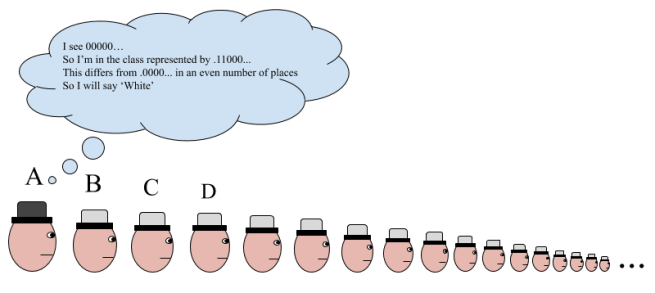
How do they do this? They start off same as before, defining the equivalence relation and selecting a representative sequence from each equivalence class. Now they label every single sequence with either a 0 or a 1. A sequence gets a 0 if it differs from the representative sequence in its equivalence class in an even number of places, and otherwise it gets a 1. This labeling has the result that any two sequences that differ by exactly one digit have opposite labels.
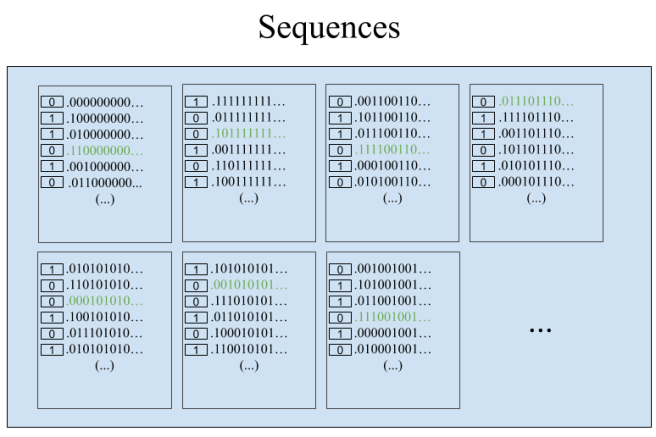
Now the first person (A) just says the label of the sequence he sees. For the next person up (B), this is the sequence that starts with their hat. And remember, they know which equivalence class they’re in, since they can see everybody in front of them! So all they need to do is consider what the label of the sequence starting with them would be if they had a white hat on. If it would be different than the label they just heard, then they know that their hat is black. And if it would be the same, then their hat is white!
The person in front of B knows the equivalence class they’re in, and now also knows what color B’s hat was. So they can do the exact same reasoning to figure out their hat color! And so on, saving every last countable prisoner besides A..
Let’s see an example of this, for the sequence 100000…

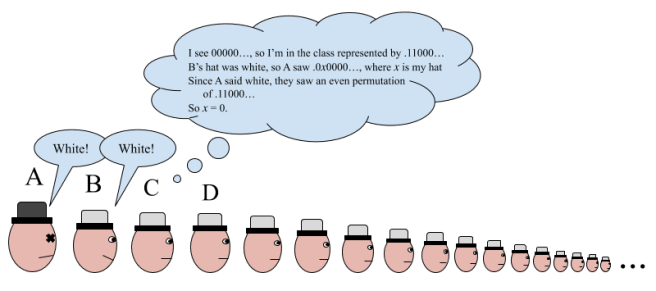

And so on forever, until every last prisoner besides A is free.
This set of results is collectively the most compelling argument I know for rejecting AC, and I love it.