If you’ve looked into abstract algebra at all, you might be intimidated by the variety of strange-sounding names; things like like monoids, magmas, semigroups, loops, fields, and so on. What are all these names about?
In general, the procedure is as follows: Choose some number of sets, equipped with some number of binary operations. Then endow these operations with some general structural constraints (things like commutativity, associativity, and so on). The result is some abstract mathematical object that might be very interesting or just medium interesting, depending on the constraints that you’ve applied. The different subfields within abstract algebra are just the studies of what you get when you apply particular <sets, operations, constraints> triples! Let’s take a little tour of these subfields.
We start with the most basic. The simplest choice you could make for the sets and operations would be one set S with one binary operation • on that set, denoted as (S, •). The most primitive constraint that you can apply to this operation is closure, which is the condition that the output of the binary operation must always be an element of S. Common constraints added on top of this include:
- Associativity (A): For all a, b, and c in S, (a • b) • c = a • (b • c)
- Identity (E): there is an element e in S such that for all a in S, e • a = a
- Invertibility (V): for all a in S, there is an element a’ in S such that a’ • a = e
- Commutativity (C): for all a and b in S, a • b = b • a
Now we can consider the different types of mathematical objects that arise from different combinations of these constraints!
AEVC = Abelian group
AEV = Group
AEC = Commutative Monoid
AE = Monoid
A = Semigroup
Only closure = Magma
These are just a few examples, and this is all for the case of a single set with a single operation. Two of the biggest objects of study in abstract algebra are rings and fields, both of which involve one set and two binary operations, usually denoted as + and •. The constraints for rings are as follows:
(R, +, •)
(R,+) is an abelian group (AEVC)
(R,•) is a monoid (AE)
Distributivity (of multiplication with respect to addition): a • (b + c) = a•b + a•c
(Rings also have a slightly more bare-bones cousin called rngs, which are basically rings without a multiplicative identity.)
Fields involve even more structure than rings:
(F, +, •)
(F, +) is an abelian group (AEVC) (call its identity 0)
(F \ {0}, •) is an abelian group (AEVC)
Distributivity (of multiplication w.r.t. addition)
There are so many other mathematical objects besides these, each of which has its own field of study. When you survey these fields at a high level of abstraction, an interesting pattern becomes apparent.
Observation 1: More structured objects are simpler and easier to fully characterize.
Think about vector spaces. A vector space has two sets (call them F and V) and four binary operations (two on F x F, one on V x V, and one on F x V). F forms a field with its two operations, and V forms an abelian group with its operation. And there are a few more constraints on the final operation, ensuring that it is well-behaved in a bunch of ways. Overall, vector spaces are highly constrained in many ways. And as such, linear algebra (the study of vector spaces) is a completely solved field. There are pretty much no interesting new discoveries in linear algebra, because there are only a few interesting things you can say about such well-structured objects, and all such things have been quickly discovered. (A quick caveat: linear algebra finds all sorts of applications in more complicated domains of math, many of which have unsolved problems. I’m not considering these problems as part of understanding vector spaces. There are also more applied open questions about, say, how to most efficiently calculate the product of two n x n matrices, which I again do not consider to reflect a lack of understanding of the structure of vector spaces.) And by the way, this is not a knock on linear algebra! I love vector spaces. It’s just that I think there are even more interesting objects out there!
Take another example, fields. Fields are less structured than vectors in a bunch of ways, but all the same, we can fully characterize all finite fields with a few simple equations. The work required to do this is fairly trivial; you can prove the classification theorems in a couple of minutes with barely any background required. For instance, you can quickly prove that all finite fields have sizes that are powers of primes. And furthermore, all finite fields of the same size are isomorphic! So if you were to write out a function f(n) for the number of non-isomorphic fields of size n, it would just be 1 for every prime power and 0 for everything else.
Similarly, compare abelian groups to groups. Abelian groups are strictly more structured objects that groups, being that they are just groups that satisfy the additional constraint of commutativity. They are also significantly less structured than fields, being that they only have to satisfy the constraints for one operation and thus don’t have to worry about distributivity between two operations. It turns out that just like with fields, you can actually classify all finite abelian groups, and write out a (relatively simple) equation for the number of finite abelian groups of size n. This number is the product of the partition numbers of the exponents of each prime in the prime factorization of n. Proving this takes a lot more work than the classification of fields, and the function is clearly much more complicated than the corresponding function for fields. But it’s enormously simpler than classifying all finite groups!
As far as I’m aware, there is no known formula that takes in a number N and returns the number of non-isomorphic groups of size N. Although there are lots of little facts known about the values of this function for particular values of N (for example, for any prime p, f(p) = 1 and f(p^2) = 2), classification in general is enormously difficult. Here are the numbers of finite groups of order N, for small values of N starting at 1.
[1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51, 1, 2, 1, 14, 1, 2, 2, 14, 1, 6, 1, 4, 2, 2, 1, 52, 2, 5, 1, 5, 1, 15, 2, 13, 2, 2, 1, 13, 1, 2, 4, 267]
(Fun exercise, try seeing how many of these you can prove for yourself!)
Here’s a plot of this sequence, to give you a sense of how complicated and strange it is:
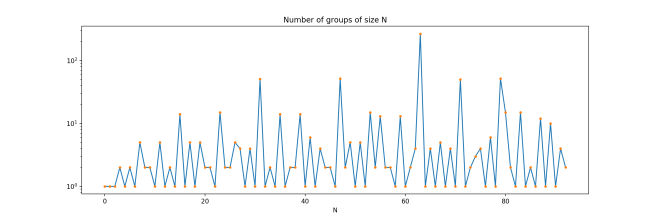
Furthermore, there are bizarre things like the sporadic groups with their stubborn resistance to categorization, and the king of the sporadic groups, the enormous Monster group. All this structure immediately vanishes as soon as you introduce commutativity, leaving you with a much less interesting object!
Observation 2: Highly unstructured objects also become easy to characterize. Think about magmas (M, •), whose only constraint is closure. How many magmas are there of size N? Well, for any two elements in M, there are N choices for the value of their product. So it’s just the number of ways of placing elements from M in N^2 spots, i.e. N^(N^2). Simple! The lack of structure here actually makes classification of the finite magmas extremely quick and easy.
Another example: Take a slightly more structured object, magmas with identity. This basically just fills in 2N – 1 of our slots (for all m, we get that e•m = m and m•e = m), so that our new classification is just N^(N^2 – 2N + 1). What if we add commutativity? Well, that just cuts our degrees of freedom roughly in half, since every time you choose the value of a•b, you have also chosen b•a! (It’s not exactly half, because of the elements that look like a•a).
But if you now add associativity, you end up with a commutative monoid. These objects are vastly more complicated and difficult to characterize. In general, associativity is probably the most interesting single property you can give to an operation (at least, of the commonly used properties we’ve discussed). By constraining an operation to be associative, you automatically endow your mathematical object with a great degree of interesting structure.
—
The conclusion I’ve drawn from these observations is that there is a sweet spot of subjective “interestingness” that exists between the highly structured and the highly unstructured. I think that objects like groups and rings occupy this sweet spot, and as you go further in either direction of the structure spectrum the objects you find become less interesting and harder to find surprising results about.
