Here’s a general question of great importance: How should we adjust our model of the world in response to data? This post is a tour of a few of the big ideas that humans have come up with to address this question. I find learning about this topic immensely rewarding, and so I shall attempt to share it! What I love most of all is thinking about how all of this applies to real world examples of inference from data, so I encourage you to constantly apply what I say to situations that you find personally interesting.
First of all, we want a formal description of what we mean by data. Let’s describe our data quite simply as a set: 
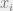
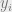
Now, suppose that you have a certain theory about the underlying relationship between the x variables and the y variables. This theory might take the form of a simple function: 
What we want is a notion of how good of a theory T is, given our data. Intuitively, we might think about doing this by simply assessing the distance between each data point 



Now here’s a problem: If we want a probabilistic evaluation of T, then we have to face the fact that it makes a deterministic prediction. Our theory seems to predict with 100% probability that at 
We can solve this problem by modifying our theory T to not just be a theory of the data, but also a theory of error. In other words, we expect that the value we get will not be exactly the predicted value, and give some account of how on average observation should differ from theory.



This error distribution can be whatever we please – Gaussian, exponential, Poisson, whatever. For simplicity let’s say that we know the error is normal (drawn from a Gaussian distribution) with a known standard deviation σ.

A note on notation here: 


This gives us a sensible notion of the probability of obtaining some value of y from a chosen x given the theory T.
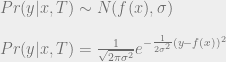
Nice! This is a crucial step towards figuring out how to evaluate theories: we’ve developed a formalism for describing precisely how likely a data point is, given a particular theory (which, remember, so far is just a function from values of independent variables to values of dependent variables, coupled with a theory of how the error in your observations works).
Let’s try to extend this to our entire data set D. We want to assess the probability of the particular values of the dependent variables, given the chosen values of the dependent variables and the function. We’ll call this the probability of D given f.
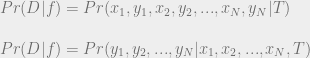
(It’s okay to move the values of the independent variable x across the conditional bar because of our assumption that we know beforehand what values x will take on.)
But now we run into a problem: we can’t really do anything with this expression without knowing how the data points depend upon each other. We’d like to break it into individual terms, each of which can be evaluated by the above expression for 
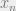

We see an interesting connection arise here between Pr(D | f) and the sum of squares evaluation of fit. More will be said of this in just a moment.
But first, let’s take a step back. Our ultimate goal here is to find a criterion for theory evaluation. And here we’ve arrived at an expression that looks like it might be right for that role! Perhaps we want to say that our criterion for evaluating theories is just maximization of Pr(D | f). This makes some intuitive sense… a good theory is one which predicts the observed data. If general relativity or quantum mechanics predicted that the sun should orbit the earth, or that atoms should be unstable, then we wouldn’t be very in favor of it.
And so we get the Likelihoodism Thesis!
Likelihoodism: The best theory f* given some data D is that which maximizes Pr(D | f). Formally:
![f^*(D) = argmax_f [ Pr(D | f) ]](https://s0.wp.com/latex.php?latex=f%5E%2A%28D%29+%3D+argmax_f+%5B+Pr%28D+%7C+f%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now, since logarithms are monotonic, we can express this in a more familiar form:
![argmax_f [Pr(D | F)] = argmax_f \left[ e^{-\frac{SOS(f, D)}{2 \sigma^2} } \right] = argmax_f \left[-\frac{SOS(f, D)}{2 \sigma^2} \right] = argmin_f [ SOS(f, D) ]](https://s0.wp.com/latex.php?latex=argmax_f+%5BPr%28D+%7C+F%29%5D+%3D+argmax_f+%5Cleft%5B+e%5E%7B-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%7D+%5Cright%5D+%3D+argmax_f+%5Cleft%5B-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%5Cright%5D+%3D+argmin_f+%5B+SOS%28f%2C+D%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Thus the best theory according to Likelihoodism is that which minimizes the sum of squares! People minimize sums of squares all the time, and most of the time they don’t realize that it can be derived from the Likelihoodism Thesis and the assumptions of Gaussian error and independent data. If our assumptions had been different, then we would have found a different expression, and SOS might no longer be appropriate! For instance, the taxicab metric arises as the correct metric if we assume exponential error rather than normal error. I encourage you to see why this is for yourself. It’s a fun exercise to see how different assumptions about the data give rise to different metrics for evaluating the distance between theory and observation. In general, you should now be able to take any theory of error and assess what the proper metric for “degree of fit of theory to data” is, assuming that degree of fit is evaluated by maximizing Pr(D | f).
Now, there’s a well-known problem with the Likelihoodism thesis. This is that the function f that minimizes SOS(f, D) for some data D is typically going to be a ridiculously overcomplicated function that perfectly fits each data points, but does terribly on future data. The function will miss the underlying trend in the data for the noise in the observations, and as a result fail to get predictive accuracy.

This is the problem of overfitting. Likelihoodism will always prefer theories that overfit to those that don’t, and as a result will fail to identify underlying patterns in data and do a terrible job at predicting future data.
How do we solve this? We need a replacement for the Likelihoodism thesis. Here’s a suggestion: we might say that the problem stems from the fact that the Likelihoodist procedure recommends us to find a function that makes the data most probable, rather than finding a function that is made most probable by the data. From this suggestion we get the Bayesian thesis:
Bayesianism: The best theory f given some data is that which maximizes Pr(f | D).
![f^*(D) = argmax_f [ Pr(f | D) ]](https://s0.wp.com/latex.php?latex=f%5E%2A%28D%29+%3D+argmax_f+%5B+Pr%28f+%7C+D%29+%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now, what is this Pr(f | D) term? It’s an expression that we haven’t seen so far. How do we evaluate it? We simply use the theorem that the thesis is named for: Bayes’ rule!

This famous theorem is a simple deductive consequence of the probability axioms and the definition of conditional probability. And it happens to be exactly what we need here. Notice that the right-hand side consists of the term Pr(D | f), which we already know how to calculate. And since we’re ultimately only interested in varying f to find the function that maximizes this expression, we can ignore the constant term in the denominator.
![argmax_f [ Pr(f | D) ] = argmax_f [ Pr(D | f) Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmax_f [ \log Pr(D | f) + \log Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmax_f [ -\frac{SOS(f, D)}{2 \sigma^2} + \log Pr(f) ] \\~\\ argmax_f [ Pr(f | D) ] = argmin_f [ SOS(f, D) - 2 \sigma^2 \log Pr(f) ]](https://s0.wp.com/latex.php?latex=argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+Pr%28D+%7C+f%29+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+%5Clog+Pr%28D+%7C+f%29+%2B+%5Clog+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmax_f+%5B+-%5Cfrac%7BSOS%28f%2C+D%29%7D%7B2+%5Csigma%5E2%7D+%2B+%5Clog+Pr%28f%29+%5D+%5C%5C%7E%5C%5C++argmax_f+%5B+Pr%28f+%7C+D%29+%5D+%3D+argmin_f+%5B+SOS%28f%2C+D%29+-+2+%5Csigma%5E2+%5Clog+Pr%28f%29+%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
The last steps we get just by substituting in what we calculated before. The 2σ² in the first term comes from the fact that the exponent of our Gaussian is (y – f(x))² / 2σ². We ignored it before because it was just a constant, but since we now have another term in the expression being maximized, we have to keep track of it again.
Notice that what we get is just what we had initially (a sum of squares) plus an additional term involving a mysterious Pr(f). What is this Pr(f)? It’s our prior distribution over theories. Because of the negative sign in front of the second term, a larger value of Pr(f) gives a smaller value for the expression that we are minimizing. Similarly, the more closely our function follows the data, the smaller the SOS term becomes. So what we get is a balance between fitting the data and having a high prior. A theory that fits the data perfectly can still end up with a bad evaluation, as long as it has a low enough prior. And a theory that fits the data poorly can end up with a great evaluation if it has a high enough prior.
(Those that are familiar with machine learning might notice that this feels similar to regularization. They’re right! It turns out that different regularization techniques just end up corresponding to different Bayesian priors! L2 regularization corresponds to a Gaussian prior over parameters, and L1 regularization corresponds to an exponential prior over parameters. And so on. Different prior assumptions about the process generating the data lead naturally to different regularization techniques.)
What this means is that if we are trying to solve overfitting, then the Bayesianism thesis provides us a hopeful ray of light. Maybe we can find some perfect prior Pr(f) that penalizes complex overfitting theories just enough to give us the best prediction. But unsurprisingly, finding such a prior is no easy matter. And importantly, the Bayesian thesis as I’ve described it gives us no explicit prescription for what this prior should be, making it insufficient for a full account of inference. What Bayesianism does is open up a space of possible methods of theory evaluation, inside which (we hope) there might be a solution to our problem.
Okay, let’s take another big step back. How do we progress from here? Well, let’s think for a moment about what our ultimate goal is. We want to say that overfitting is bad, and that therefore some priors are better than others insofar as they prevent overfitting. But what is the standard we’re using to determine that overfitting is bad? What’s wrong with an overfitting theory?
Here’s a plausible answer: The problem with overfitting is that while it maximizes descriptive accuracy, it leads to poor predictive accuracy! I.e., theories that overfit do a great job at describing past data, but tend to do a poor job of matching future data.
Let’s take this idea and run with it. Perhaps all that we truly care about in theory selection is predictive accuracy. I’ll give a name to this thesis:
Predictivism: The ultimate standard for theory evaluation is predictive accuracy. I.e., the best theory is that which does the best at predicting future data.
Predictivism is a different type of thesis than Bayesianism and Likelihoodism. While each of those gave precise prescriptions for how to calculate the best theory, Predictivism does not. If we want an explicit algorithm for computing the best theory, then we need to say what exactly “predictive accuracy” means. This means that as far as we know so far, Predictivism could be equivalent to Likelihoodism or to Bayesianism. It all depends on what method we end up using to determine what theory has the greatest predictive accuracy. Of course, we have good reasons to suspect that Likelihoodism is not identical to Predictivism (Likelihoodism overfits, and we suspect that Predictivism will not) or to Bayesianism (Bayesianism does not prescribe a particular prior, so it gives no unique prescription for the best theory). But what exactly Predictivism does say depends greatly on how exactly we formalize the notion of predictive accuracy.
Another difference between Predictivism and Likelihoodism/Bayesianism is that predictive accuracy is about future data. While it’s in principle possible to find an analytic solution to P(D | f) or P(f | D), Predictivism seems to require us to compute terms involving future data! But these are impossible to specify, because we don’t know what the future data will be!
Can we somehow approximate what the best theory is according to Predictivism, by taking our best guess at what the future data will be? Maybe we can try to take the expected value of something like 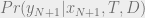

First, in taking an expected value, you must use the distribution of outcomes given by your own theory. But then your evaluation picks up an inevitable bias! You can’t rely on your own theories to assess how good your theories are.
And second, by the assumptions we’ve included in our theories so far, the future data will be independent of the past data! This is a really big problem. We want to use our past data to give some sense of how well we’ll do on future data. But if our data is independent, then our assessment of how well T will do on the next data point will have to be independent of the past data as well! After all, no matter what value 

So is there any way out of this? Surprisingly, yes! If we get creative, we can find ways to approximate this probability with some minimal assumptions about the data. These methods all end up relying on a new concept that we haven’t yet discussed: the concept of a model. The next post will go into more detail on how this works. Stay tuned!
