Imagine that you take a coin that you believe to be fair and flip it 20 times. Each time it lands heads. You say to your friend: “Wow, what a crazy coincidence! There was a 1 in 220 chance of this outcome. That’s less than one in a million! Super surprising.”
Your friend replies: “I don’t understand. What’s so crazy about the result you got? Any other possible outcome (say, HHTHTTTHTHHHTHTTHHHH) had an equal probability as getting all heads. So what’s so surprising?”
Responding to this is a little tricky. After all, it is the case that for a fair coin, the probability of 20 heads = the probability of HHTHTTTHTHHHTHTTHHHH = roughly one in a million.
So in some sense your friend is right that there’s something unusual about saying that one of these outcomes is more surprising than another.
You might answer by saying “Well, let’s parse up the possible outcomes by the number of heads and tails. The outcome I got had 20 heads and 0 tails. Your example outcome had 12 heads and 8 tails. There are many many ways of getting 12 heads and 8 tails than of getting 20 heads and 0 tails, right? And there’s only one way of getting all 20 heads. So that’s why it’s so surprising.”
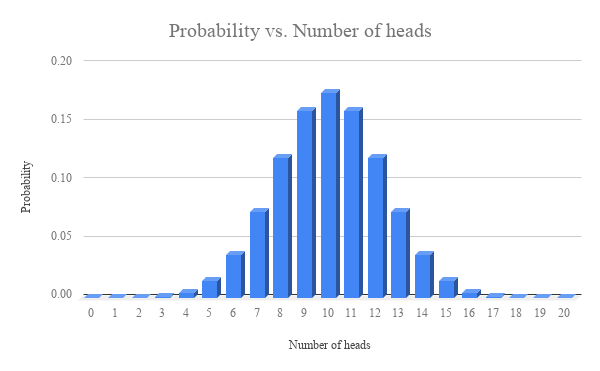
Your friend replies: “But hold on, now you’re just throwing out information. Sure my example outcome had 12 heads and 8 tails. But while there’s many ways of getting that number of heads and tails, there’s only exactly one way of getting the result I named! You’re only saying that your outcome is less likely because you’ve glossed over the details of my outcome that make it equally unlikely: the order of heads and tails!”
I think this is a pretty powerful response. What we want is a way to say that HHHHHHHHHHHHHHHHHHHH is surprising while HHTHTTTHTHHHTHTTHHHH is not, not that 20 heads is surprising while 12 heads and 8 tails is unsurprising. But it’s not immediately clear how we can say this.
Consider the information theoretic formalization of surprise, in which the surprisingness of an event E is proportional to the negative log of the probability of that event: Sur(E) = -log(P(E)). There are some nice reasons for this being a good definition of surprise, and it tells us that two equiprobable events should be equally surprising. If E is the event of observing all heads and E’ is the event of observing the sequence HHTHTTTHTHHHTHTTHHHH, then P(E) = P(E’) = 1/220. Correspondingly, Sur(E) = Sur(E’). So according to one reasonable formalization of what we mean by surprisingness, the two sequences of coin tosses are equally surprising. And yet, we want to say that there is something more epistemically significant about the first than the second.
(By the way, observing 20 heads is roughly 6.7 times more surprising than observing 12 heads and 8 tails, according to the above definition. We can plot the surprise curve to see how maximum surprise occurs at the two ends of the distribution, at which point it is 20 bits.)
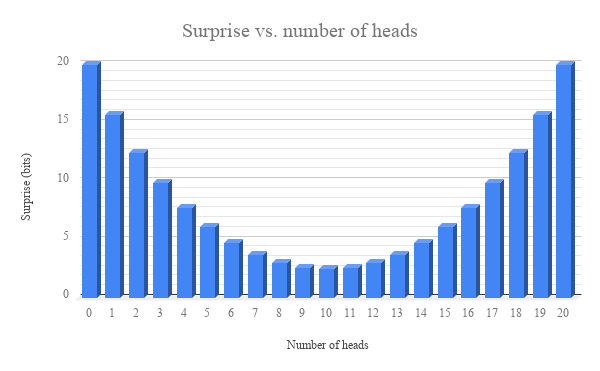
So there is our puzzle: in what sense does it make sense to say that observing 20 heads in a row is more surprising than observing the sequence HHTHTTTHTHHHTHTTHHHH? We certainly have strong intuitions that this is true, but do these intuitions make sense? How can we ground the intuitive implausibility of getting 20 heads? In this post I’ll try to point towards a solution to this puzzle.
Okay, so I want to start out by categorizing three different perspectives on the observed sequence of coin tosses. These correspond to (1) looking at just the outcome, (2) looking at the way in which the observation affects the rest of your beliefs, and (3) looking at how the observation affects your expectation of future observations. In probability terms, these correspond to the P(E), P(T| T) and P(E’ | E).
Looking at things through the first perspective, all outcomes are equiprobable, so there is nothing more epistemically significant about one than the other.
But considering the second way of thinking about things, there can be big differences in the significance of two equally probable observations. For instance, suppose that our set of theories under consideration are just the set of all possible biases of the coin, and our credences are initially peaked at .5 (an unbiased coin). Observing HHTHTTTHTHHHTHTTHHHH does little to change our prior. It shifts a little bit in the direction of a bias towards heads, but not significantly. On the other hand, observing all heads should have a massive effect on your beliefs, skewing them exponentially in the direction of extreme heads biases.
Importantly, since we’re looking at beliefs about coin bias, our distributions are now insensitive to any details about the coin flip beyond the number of heads and tails! As far as our beliefs about the coin bias go, finding only the first 8 to be tails looks identical to finding the last 8 to be tails. We’re not throwing out the information about the particular pattern of heads and tails, it’s just become irrelevant for the purposes of consideration of the possible biases of the coin.
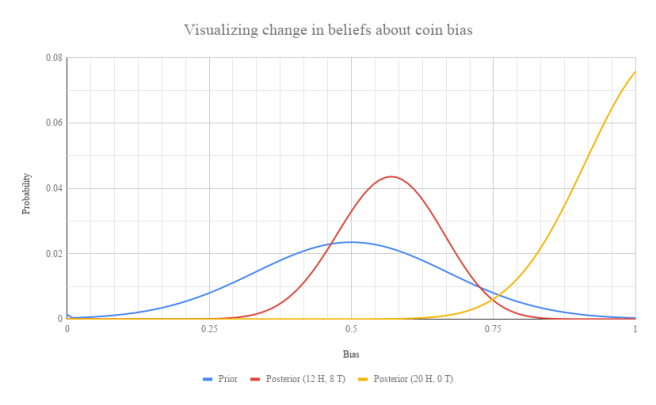
If we want to give a single value to quantify the difference in epistemic states resulting from the two observations, we can try looking at features of these distributions. For instance, we could look at the change in entropy of our distribution if we see E and compare it to the change in entropy upon seeing E’. This gives us a measure of how different observations might affect our uncertainty levels. (In our example, observing HHTHTTTHTHHHTHTTHHHH decreases uncertainty by about 0.8 bits, while observing all heads decreases uncertainty by 1.4 bits.) We could also compare the means of the posterior distributions after each observation, and see which is shifted most from the mean of the prior distribution. (In this case, our two means are 0.57 and 0.91).
Now, this was all looking at things through what I called perspective #2 above: how observations affect beliefs. Sometimes a more concrete way to understand the effect of intuitively implausible events is to look at how they affect specific predictions about future events. This is the approach of perspective #3. Sticking with our coin, we ask not about the bias of the coin, but about how we expect it to land on the next flip. To assess this, we look at the posterior predictive distributions for each posterior:
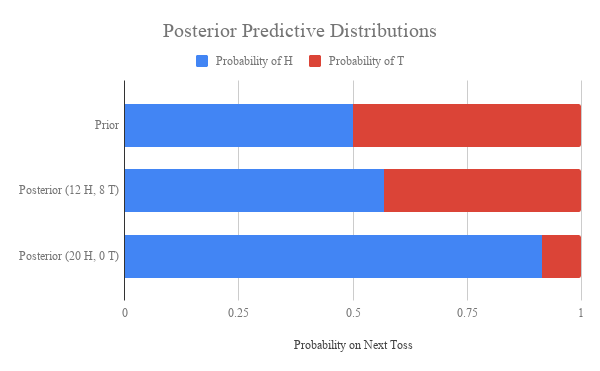
It shouldn’t be too surprising that observing all heads makes you more confident that the next coin will land heads than observing HHTHTTTHTHHHTHTTHHHH. But looking at this graph gives a precise answer to how much more confident you should be. And it’s somewhat easier to think about than the entire distribution over coin biases.
I’ll leave you with an example puzzle that relates to anthropic reasoning.
Say that one day you win the lottery. Yay! Super surprising! What an improbable event! But now compare this to the event that some stranger Bob Smith wins the lottery. This doesn’t seem so surprising. But supposing that Bob Smith buys lottery tickets at the same rate as you, the probability that you win is identical to the probability that Bob Smith wins. So… why is it any more surprising when you win?
This seems like a weird question. Then again, so did the coin-flipping question we started with. We want to respond with something like “I’m not saying that it’s improbable that some random person wins the lottery. I’m interested in the probability of me winning the lottery. And if we parse up the outcomes as that either I win the lottery or that somebody else wins the lottery, then clearly it’s much more improbable that I win than that somebody else wins.”
But this is exactly parallel to the earlier “I’m not interested in the precise sequence of coin flips, I’m just interested in the number of heads versus tails.” And the response to it is identical in form: If Bob Smith, a particular individual whose existence you are aware of, wins the lottery and you know it, then it’s cheating to throw away those details and just say “Somebody other than me won the lottery.” When you update your beliefs, you should take into account all of your evidence.
Does the framework I presented here help at all with this case?
