I added cross validation to my model selection program, and ooh boy do I now understand why people want to find more efficient alternatives.
Reliable CV calculations end up making the program run orders of magnitude slower, as they require re-fitting the curve for every partition of your data and this is the most resource-intensive part of the process. While it’s beautiful in theory, this is a major set-back in practice.
For a bunch of different true distributions I tried, I found that CV pretty much always lines up with all of the other methods, just with a more “jagged” curve and a steeper complexity penalty. This similarity looks like a score for the other methods, assuming that CV does a good job of measuring predictive power. (And for those interested in the technical details, the cross validation procedure implemented here is leave-one-out CV)
I also added an explicit calculation of DKL, which should help to give some idea of a benchmark against which we can measure all of these methods. Anyway, I have some more images!
True curve = e-x/3 – ex/3
N = 100 data points
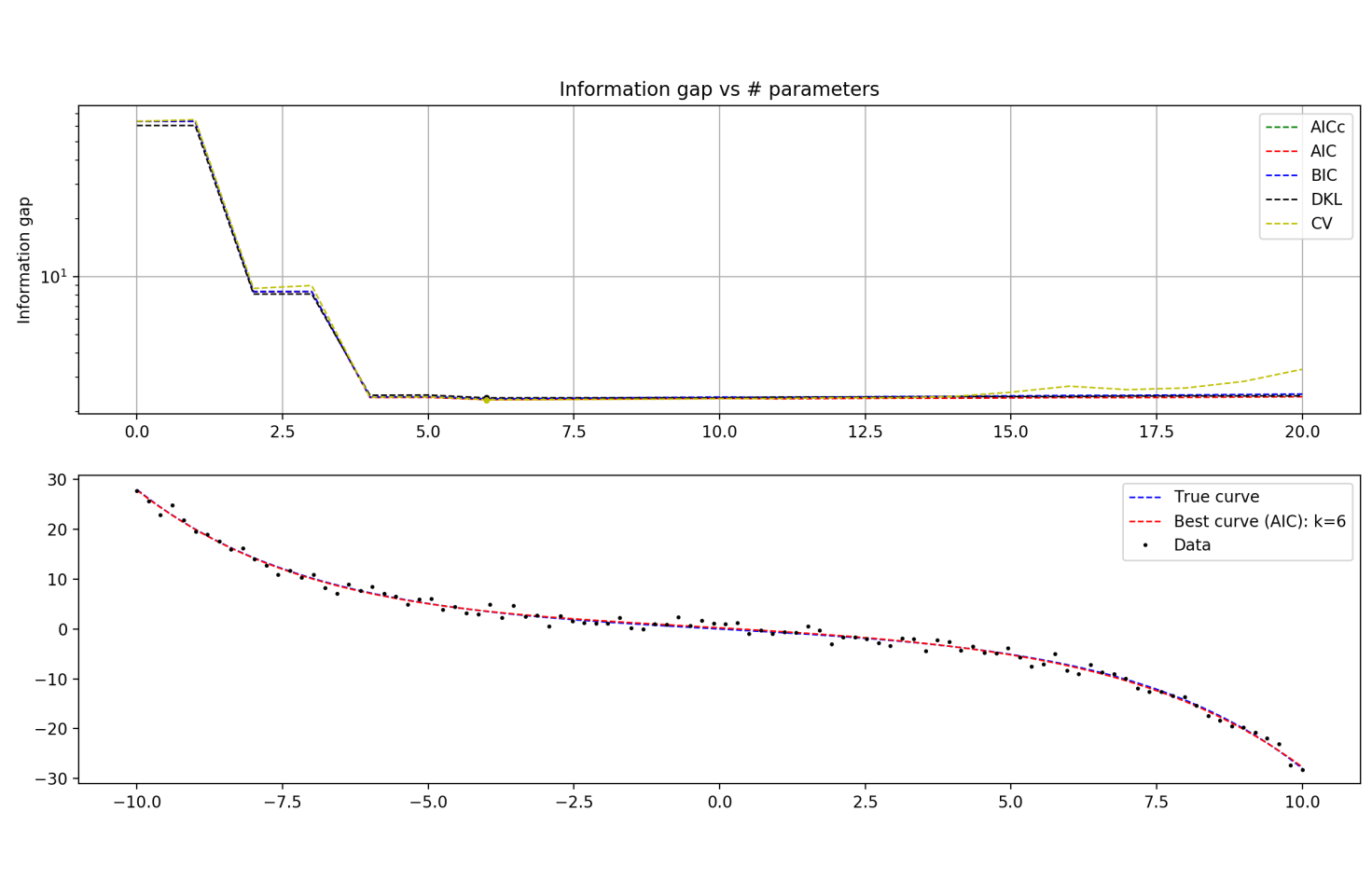
N = 100 data points, zoomed in a bit
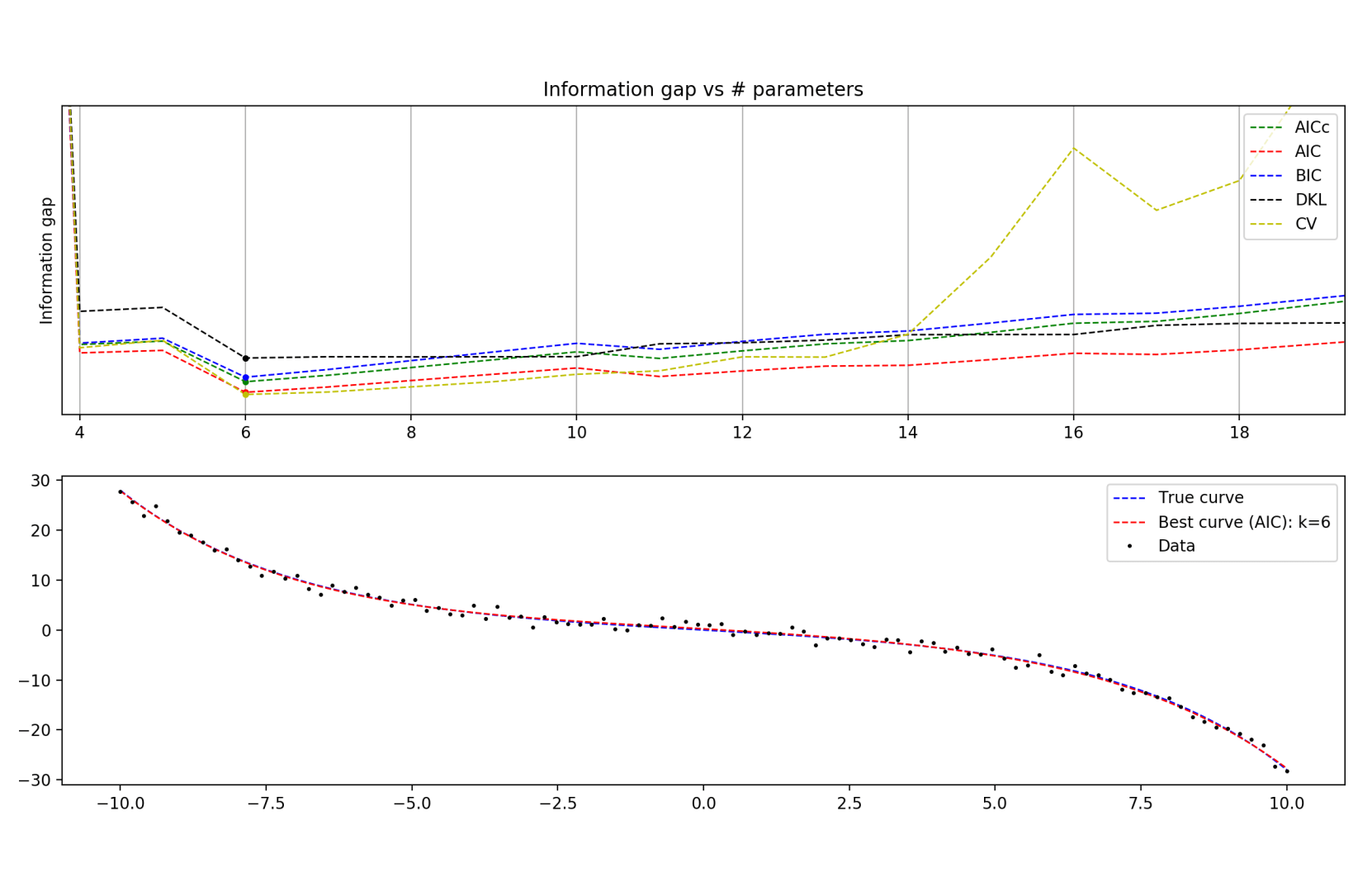
For smaller data sets, you can see that AICc tracks DKL much more closely than any other technique (which is of course the entire purpose of AICc).
N = 25
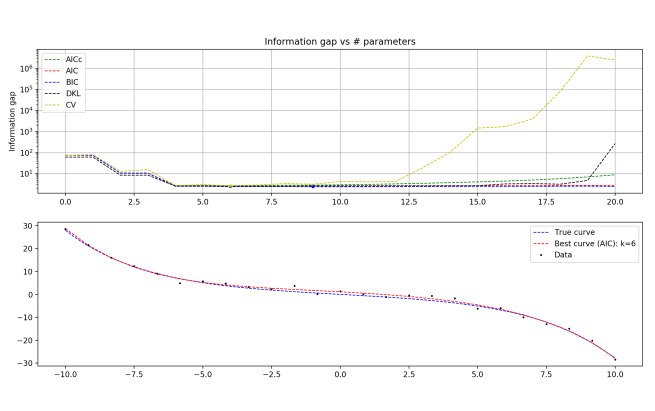
N = 25, zoomed
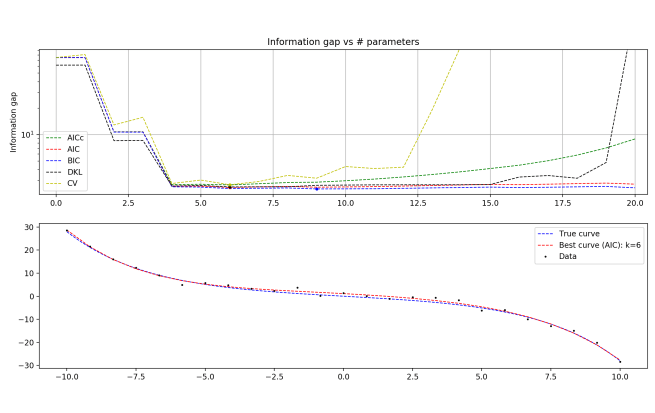
N = 25, super zoom
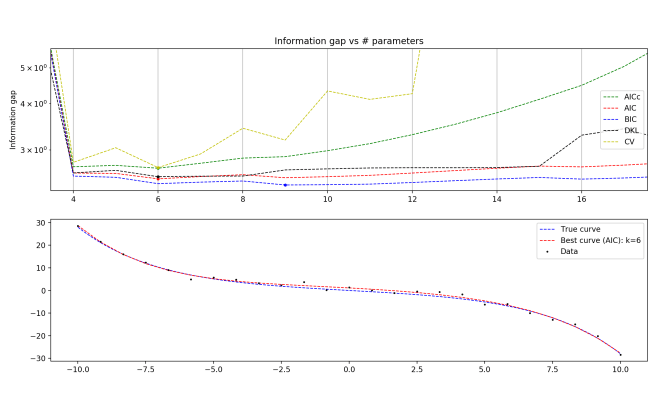
Interestingly, you start to see BIC really suffering relative to the other methods, beginning to overfit the data. This is counterintuitive; BIC is supposed to be the method that penalizes complexity excessively and underfits the data. Relevant is that in this program, I use the form of BIC that doesn’t approximate for large N.
BICsmall N = k log(N/2π) – 2L
BICordinary = k log(N) – 2L
When I use the approximation instead, the problem disappears. Of course, this is not too great a solution; why should the large N approximation be necessary for fixing BIC specifically when N is small?
(Edit: after many more runs, it’s looking more like it may have just been a random accident that BIC overfit in the first few runs)
Just for the heck of it, I also decided to torture my polynomials a little bit by making them try to fit the function 1/x. I got dismal results no matter how I tried to tweak the hyper-parameters, which is, well, pretty much what I expected (1/x has no Taylor expansion around 0, for one thing).
More surprisingly, I tried fitting a simple Gaussian curve and again got fairly bad results. The methods disagreed with one another a lot of the time (although weirdly, AICc and BIC seemed to generally be in agreement), and gave curves that were overfitting the data a bit. The part that seems hardest for a polynomial to nail down is the flattened ends of the Gaussian curve.
True curve = 40 exp(-x2/2), N = 100 data points
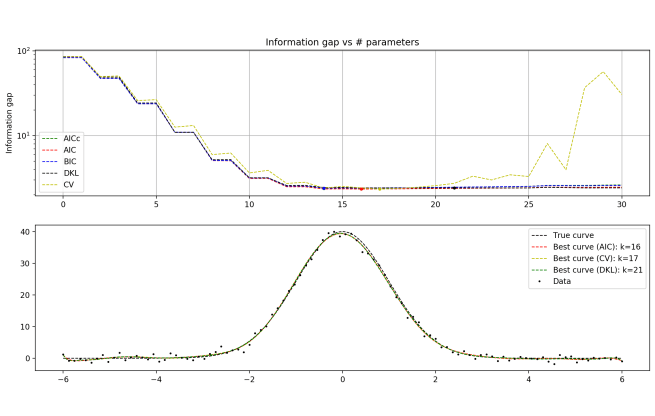
And zoomed in…
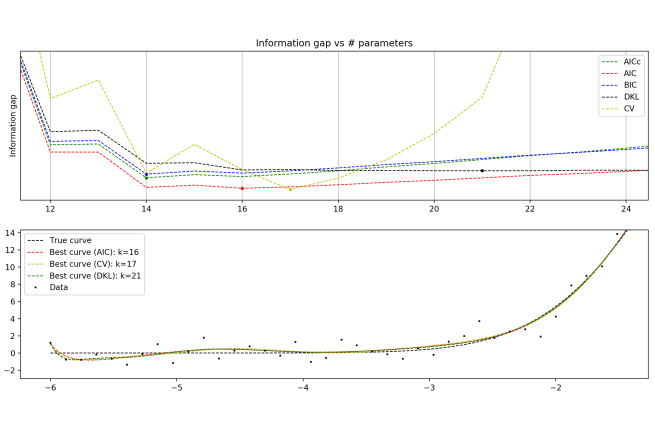
If the jaggedness of the cross validation score is not purely an artifact of random fluctuations in the data, I don’t really get it. Why should, for example, a 27-parameter model roughly equal a 25-parameter model in predictive power, but a 26-parameter model be significantly worse than both?
