Background for this post: Entropy is expected surprise, A survey of entropy and entropy variants, and Maximum Entropy and Bayes
Suppose you have some old distribution Pold, and you want to update it to a new distribution Pnew given some information.
You want to do this in such a way as to be as uncertain as possible, given your evidence. One strategy for achieving this is to maximize the difference in entropy between your new distribution and your old one.
Max (Snew – Sold) = ∑ -Pnew logPnew – ∑ -Pold logPold
Entropy is expected surprise. So this quantity is the new expected surprise minus the old expected surprise. Maximizing this corresponds to trying to be as much more surprised on average as possible than you expected to be previously.
But this is not quite right. We are comparing the degree of surprise you expect to have now to the degree of surprise you expected to have previously, based on your old distribution. But in general, your new distribution may contain important information as to how surprised you should have expected to be.
Think about it this way.
One minute ago, you had some set of beliefs about the world. This set of beliefs carried with it some degree of expected surprise. This expected surprise is not the same as the true average surprise, because you could be very wrong in your beliefs. That is, you might be very confident in your beliefs (i.e. have very low EXPECTED surprise), but turn out to be very wrong (i.e. have very high ACTUAL average surprise).
What we care about is not how surprised somebody with the distribution Pold would have expected to be, but how surprised you now expect somebody with the distribution Pold to be. That is, you care about the average value of surprise, given your new distribution, your new best estimate of the actual distribution
That is to say, instead of using the simple difference in entropies S(Pnew) – S(Pold), you should be using the relative entropy Srel(Pnew, Pold).
Max Srel = ∑ -Pnew logPnew – ∑ -Pnew logPold
Here’s a diagram describing the three species of entropy: entropy, cross entropy, and relative entropy.
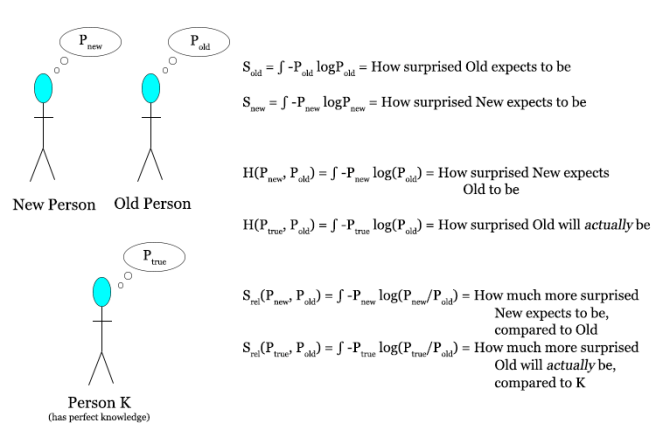
As one more example of why this makes sense: imagine that one minute ago you were totally ignorant and knew absolutely nothing about the world, but were for some reason very irrationally confident about your beliefs. Now you are suddenly intervened upon by an omniscient Oracle that tells you with perfect accuracy exactly what is truly going on.
If your new beliefs are designed by maximizing the absolute gain in entropy, then you will be misled by your old irrational confidence; your old expected surprise will be much lower than it should have been. If you use relative entropy, then you will be using your best measure of the actual average surprise for your old beliefs, which might have been very large. So in this scenario, relative entropy is a much better measure of your actual change in average surprise than the absolute entropy difference, as it avoids being misled by previous irrationality.
A good way to put this is that relative entropy is better because it uses your current best information to estimate the difference in average surprise. While maximizing absolute entropy differences will give you the biggest change in expected surprise, maximizing relative entropy differences will do a better job at giving you the biggest difference in *actual* surprise. Relative entropy, in other words, allows you to correct for previous bad estimates of your average surprise, and substitute in the best estimate you currently have.
These two approaches, maximizing absolute entropy difference and maximizing relative entropy, can give very different answers for what you should believe. It so happens that the answers you get by maximizing relative entropy line up nicely with the answers you get from just ordinary Bayesian updating, while the answers you get by maximizing absolute entropy differences, which is why this difference is important.
