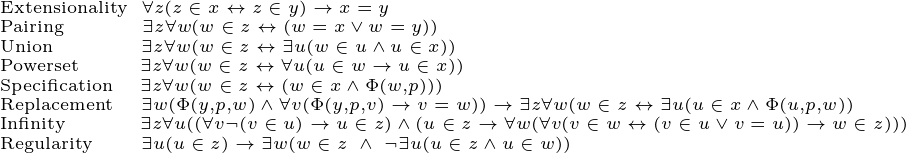Part 2 here.
Part 1: What is Forcing?
Forcing is a set-theoretic technique developed by Paul Cohen in the 1960s to prove the independence of the Continuum Hypothesis from ZFC. He won a Fields Medal as a result, and to this day it’s the only Fields Medal to be awarded for a work in logic. It’s safe to say that forcing is one of the most powerful techniques that set theorists have at their disposal as they explore the set theoretic multiverse.
Forcing has an intimidating reputation, which is somewhat deserved. The technique involves many moving parts and it takes some time to see how they all fit together. I found these three resources to be excellent for learning the basics of the technique:
Each of these sources takes a slightly different approach, and I think that they complement each other quite well. I’ve produced a high-level outline of the argument for why forcing works, as well as how to use forcing to prove the independence of the CH. I don’t feel quite competent to present all of forcing from the ground up, so this outline is not meant to be self-contained. In particular, I’m gonna assume you’re familiar with the basics of first order logic and ZFC and are comfortable with Boolean algebras. I’m also going to skim over the details of cardinal collapse, which are still fairly opaque to me.
Forcing in 5 lines!
- Fix a countable transitive model M ⊨ ZFC and a Boolean algebra (B, ≤) ∈ M.
- Define MB := { f ∈ M | f: MB ⇀ B } ⊆ M.
- Choose an M-generic ultrafilter G ⊆ B.
- For every n in MB, define valG(n) := { valG(m) | (m, b) ∈ n for some b in G }.
- Define M[G] := { valG(n) | n ∈ MB }. This is a countable transitive model of ZFC containing all of M as well as G!
We start with a countable transitive model M of ZFC, and then construct a larger countable transitive model M[G] of ZFC that contains a new set G. Let me say a few words on each step.
Step 1
1. Fix a countable transitive model M ⊨ ZFC and a Boolean algebra (B, ≤) ∈ M.
There’s not much to say about Step 1. I suppose it’s worth noting that we’re assuming the existence of a countable transitive model of ZFC, meaning that the results of forcing are all conditioned not just on the consistency of ZFC, but on the existence of transitive models of ZFC, which is significantly stronger. (The existence of countable transitive models is no stronger than the existence of transitive models, by the downwards Lowenheim-Skolem theorem.)
Moving on!
Step 2
2. Define MB := { f ∈ M | f: MB ⇀ B }
MB is sometimes called a Boolean-valued model of ZFC. The elements of MB are called “B-names” or “B-valued sets” or just “B-sets” (as I’ll call them). These B-sets are partial functions in M that go from MB to B. “Huh? Hold on,” I hear you saying, “Isn’t that a circular definition?”
It might look circular, but it’s not; it’s inductive. First of all, regardless of what MB is, the empty set counts as a partial function from MB to B: all its inputs are in MB, all its outputs are in B, and no input gets sent to multiple outputs! ∅ is also in M, so ∅ is an element of MB. But now that we know that ∅ is in MB, we can also construct the function {(∅, b)} for each b in B. This satisfies the criterion of “being a partial function from MB to B”, and it is in M because B is in M. So for any b in B, {(∅, b)} is in MB. And now we can construct more partial functions with these new elements of MB, like {(∅, b), ({(∅, b’)}, b’’)} and so on.
If you’re still not convinced that the definition of MB is sensible, we can define it without any apparent circularity, making the induction explicit:
- V0 = ∅
- Vα+1 = { f ∈ M | f is a partial function from Vα to B } for any ordinal α in M.
- Vλ = ⋃{Vα | α ∈ λ} for any limit ordinal λ in M.
- Finally, MB = ⋃{Vα | α ∈ M}.
Okay, so now we know the definition of MB. But what is it? How do we intuitively think about the elements of MB? One way is to think of them as “fuzzy sets”, sets that contain each other to varying degrees. In this way of seeing things, the Boolean algebra B is our extension of the trivial Boolean algebra {True, False} to a more complicated Boolean algebra that allows intermediate truth values as well. So for instance, of the B-set {(∅, b)} we can say “it contains ∅ to degree b, and contains nothing else”. Of the B-set {(∅, b), ({(∅, b’)}, b’’)} we may say “it contains ∅ to degree b, and contains [the set that contains ∅ to degree b’] to degree b’’, and nothing else.” And so on.
Every Boolean algebra has a top element ⊤ corresponding to “definite truth” and a bottom element ⊥ corresponding to “definite falsity”, so our B-sets don’t have to be entirely fuzzy. For instance the B-set {(∅, ⊤)} definitely contains ∅ and definitely doesn’t contain anything else. It can be thought of as intuitively similar to the set {∅} in M. And the B-set {(∅, ⊥)} definitely doesn’t contain ∅, or anything else for that matter. This brings up an interesting question: how is the B-set {(∅, ⊥)} any different from the B-set ∅? They have the same intuitive properties: both contain nothing (or said differently, contain each thing to degree ⊥). Well that’s right! You can think of {(∅, ⊥)} and ∅ as two different names for the same idea. They are technically distinct as names, but in Steps 3 and 4 when we collapse MB back down to an ordinary model of ZFC, the distinction between them will vanish. (The details of how exactly we assign B-values to sentences about MB are interesting in their own right, and might deserve their own post.)
So intuitively what we’ve done is take our starting model M and produce a new structure that looks a lot like M in many ways except that it’s highly ambiguous: in addition to all the old sharp sets we have all these new fuzzy sets that are unsure about their members. In the next two steps we collapse all this ambiguity back down, erasing all of the fuzziness. It turns out that there are many ways to collapse the ambiguity (one for each ultrafilter in B in fact!), but we’ll want to choose our ultrafilter very carefully so that we (1) don’t end up back where we started, (2) end up with a model of ZFC, and (3) end up with an interesting model of ZFC.
Step 3
3. Choose an M-generic ultrafilter G ⊆ B.
There’s some terminology here that you might be unfamiliar with.
Firstly, what’s an ultrafilter? It’s a nonempty proper subset of B that’s closed upwards, closed under intersection, and contains one of b or ¬b for each b in B. I talked about ultrafilters here in the context of power sets, but it generalizes easily to Boolean algebras (and there are some pretty pictures to develop your intuitions a bit).
Okay, so that’s what ultrafilters are. What is it to be a generic ultrafilter? A generic ultrafilter is one that intersects every dense subset of B. What’s a dense subset of B? A dense subset of a Boolean algebra (B, ≤) is any subset of B\{⊥} that lower-bounds all of B\{⊥}. In other words, D is a dense subset of B if for every element of B\{⊥} there’s a lower element of D. Intuitively, D is like a foundation that the rest of B\{⊥} rests upon (where “upwards” corresponds to “greater than”). No matter where you are in B\{⊥}, you can follow the order downwards and eventually find yourself at an element of D. And a generic ultrafilter is an ultrafilter that shares something in common with each of these foundational subsets.Why have we excluded the bottom element of B, ⊥? If we hadn’t done so then the dense subsets would just be any and all sets containing ⊥! Then any generic ultrafilter would have to contain ⊥, but this is inconsistent with the definition of an ultrafilter!
Finally, what’s an M-generic ultrafilter? Recalling that a generic ultrafilter has to intersect every dense subset of B, an M-generic ultrafilter only needs to intersect every dense subset of B that’s in M.
I hear a possible objection! “But you already told us that B is in M! And since ZFC has the power set axiom, don’t we know that M must also contain all of B’s subsets? If so then M-genericity is no different from genericity!” The subtlety here is that the power set axiom guarantees us that M contains a set 𝒫(B) that contains all the subsets of B that are in M. Nowhere in ZFC is there a guarantee that every subset of B exists, and in fact such a guarantee is not possible in any first-order theory whatsoever! (Can you see how this follows from the downward Lowenheim-Skolem theorem?) The power set axiom doesn’t create any subsets of B, it merely collects together all the subsets of B that already exist in M.
Now, why do we care about G being M-generic? A few steps down the line we’ll see why M-genericity is such an important property, but in all honesty my intuition is murky here as to how to motivate it a priori. For now, take it on faith that M-genericity ends up being exactly the right property to require of G for our purposes. We’ll end up making extensive use of the fact that G intersects every dense subset of B in M.
Very keen readers might be wondering: how do we know that an M-generic ultrafilter even exists? This is where the countability of M saves us: since M is countable, it only contains countably many dense subsets of B: (D0, D1, D2, …). We construct G as follows: first we choose any b0 ∈ D0. Then for any n ∈ ℕ, since Dn+1 is dense in B, we can find a dn+1 ∈ Dn+1 such that dn+1 ≤ dn. Now we have an infinite descending chain of elements from dense subsets. Define G to be the upwards closure of {dn | n ∈ ℕ}, i.e. G = {b ∈ B | b ≥ dn for some n ∈ ℕ}. This is M-generic by construction, and it’s an ultrafilter: for any b ∈ B, either {b’ ∈ B | b’ ≤ b} or {b’ ∈ B | b’ ≤ ¬b} is dense, implying that G contains either b or ¬b. (Convince yourself that it’s also closed upwards and under ∧.)
Really important note: this proof of G’s existence relies on the countability of M. But from M’s perspective, it isn’t countable; i.e. M doesn’t believe that there’s a bijection that puts each set in correspondence with an element of omega. So M can’t prove the existence of G, and in fact G is a set that doesn’t exist within M at all.
Step 4
4. For every n in MB, define valG(n) := {valG(m) | (m, b) ∈ n for some b in G}.
Ok, next we use G to define a “valuation function” valG(•). This function takes the B-sets created in Step 2 and “collapses” them into ordinary sets. It’s defined inductively: the G-valuation of a B-set n is defined in terms of the G-valuations of the elements of n. (As a side note, the fact that this definition works relies on the transitivity of our starting model! Can you see why?)
Let’s work out some simple examples. Start with n = ∅. Then valG(∅) = {valG(m) | (m, b) ∈ ∅ for some b in G} = ∅, because there is no (m, b) in ∅. Thus G evaluates ∅ as ∅. So far so good! Now for a slightly trickier one: n = {(∅, b)}, where b is some element of B.
valG( {(∅,b)} ) = {valG(m) | (m, b) ∈ {(∅, b)} for some b in G} = {valG(m) | m = ∅ & b ∈ G}
There are two cases: either b is in G or b is not in G. In the first case, {(∅, b)} is evaluated to be {∅}. In the second, {(∅,b)} is evaluated to be {}. What’s the intuition here? G is a subset of B, and we can think of it as a criterion for determining which Boolean values will be collapsed to True. And since G is an ultrafilter, every Boolean value will either be collapsed to True (if b ∈ G) or to False (if ¬b ∈ G). Recall that we thought of {(∅, b)} as a B-set that “contained ∅ to degree b”. Our G-evaluation of this set removed all fuzziness: if b was included in G then we evaluate {(∅, b)} as actually containing ∅. And if not, then we said that it didn’t. Either way, all fuzziness has been removed and we’ve ended up with an ordinary set!
The same happens for every B-set. When we feed it into the function valG(•), we collapse all its fuzziness and end up with an ordinary set, whose members are determined by our choice of B.
Step 5
5. Define M[G] := {valG(n) | n ∈ MB}. M[G] is a countable transitive model of ZFC such that M ⊆ M[G] and G ∈ M[G].
Now we simply evaluate all the B-sets and collect them together, and give the result a name: M[G]. This part is easy: the hard work has already been done in defining MB and valG. What remains is to show that this new set is a countable transitive model of ZFC containing all of M as well as G. Let’s do this now.
First of all, why is M[G] countable? Well, M is countable and MB is a subset of M, so MB is countable. And valG is a surjective function from MB into M[G], so |M[G]| ≤ |MB|.
Second, why is M[G] transitive? This follows immediately from its definition: the elements of M[G] are G-valuations, and elements of G-valuations are themselves G-valuations. So elements of elements of M[G] are themselves elements of M[G]. That’s transitivity!
Third, why is M[G] a model of ZFC? Er, we’ll come back to this one.
Fourth, why is M ⊆ M[G]? To show this, we’ll take any arbitrary set x in M and show that it exists in M[G]. To do this, we first define a canonical name for x: a B-set Nx that acts as the surrogate of x in MB. Define Nx to be {(Ny, ⊤) | y ∈ x}. (Make sure that Nx is actually in MB!) What’s the G-valuation of Nx? It’s just x! Here’s a proof by ∈-induction:
First, N∅ = {(Ny,⊤) | y ∈ ∅} = ∅.
So valG(N∅) = valG(∅) = {valG(m) | (m, b) ∈ ∅ for some b in G} = ∅.
Now, assume that valG(Ny) = y for every y ∈ x.
Then valG(Nx) = {valG(Ny) | (Ny, b) ∈ Nx for some b in G} = {y | (Ny, ⊤) ∈ Nx} = {y | y ∈ x} = x.
Thus by ∈-induction, for all x, valG(Nx) = x.
Finally, why is G ∈ M[G]? We prove this by finding a B-set that G-valuates to G itself. Define A := {(Nb, b) | b ∈ B}. Then valG(A) = { valG(m) | (m, b) ∈ A for some b in G } = {valG(Nb) | b ∈ G} = {b | b ∈ G} = G.
And there it is! We’re done!
Ha ha, tried to pull a fast one on you. We still have one crucial step remaining: proving that M[G] is actually a model of ZFC! As far as I know, there’s no concise way to do this… you have to actually go through each axiom of ZFC and verify that M[G] satisfies it. I’m not going to do that here, but I will provide proofs of four axioms to give you a flavor.
Infinity: M contains a set I satisfying the axiom of infinity and M ⊆ M[G]. So I ∈ M[G], and it still satisfies infinity (still contains ∅ and is closed under successor).
Pairing: Let x and y be any two sets in M[G]. Then for some n1 and n2 in MB, x = valG(n1) and y = valG(n2). Now define n := {(n1, ⊤), (n2, ⊤)} ∈ MB. Then valG(n) = {x, y}.
Union: Let x be any element of M[G]. Since M[G] is transitive, every element y of an element of x is in M[G]. So for each such y there’s a B-set ny such that valG(ny) = y. Define n := {(ny,⊤) | y ∈ z for some z ∈ x}. Then valG(n) = {valG(ny) | y ∈ z for some z ∈ x} = {y | y ∈ z for some z ∈ x} = ⋃x.
Comprehension: Let φ(y) be any first-order formula in the language of ZFC, and x ∈ M[G]. For every element y of x, let ny be any B-set that G-valuates to y. Define n := {(ny,⊤) | y ∈ x & φ(y)}. Then valG(n) = {y ∈ x | φ(y)}.
And I leave you to fill in the rest of the axioms of ZFC for yourself. Much of it looks very similar to the proofs of pairing, union, and comprehension: make the natural choice for a B-set which G-valuates to the particular set whose existence you’re trying to prove. And THEN you’re done!
✯✯✯
Okay! If you’ve made it this far, take a breather and congratulate yourself. You now understand how to adjoin a new set to an existing model of ZFC so long as this new set is an M-generic ultrafilter in a Boolean algebra B ∈ M). And this process works equally well no matter what Boolean algebra you pick!
In fact, the choice of the Boolean algebra in step 1 is the key degree of freedom we have in this whole process. B isn’t the set that we end up adjoining to M, and in fact B is always chosen to be an element of our starting model. But the fact that G is always chosen to be an M-generic filter in B means that the structure of B greatly influences what properties G has.
You might notice that we also technically have another degree of freedom in this process: namely step 3 where I said “choose an M-generic filter G in B”. While this is technically true, in practice much of forcing is about finding really clever choices of B so that any M-generic filter in B has whatever interesting property we’re looking for.
There’s another subtlety about the choice of B, namely that in applications of forcing one generally starts with a partially ordered set (P, ≤) and then extends it to a Boolean algebra B. A really cool result with an even cooler topological proof is that this extension is always possible. For any choice of P one can construct a complete Boolean algebra B such that P is order-isomorphic to a dense subset of B. (In a sentence, we turn P into a topological space whose open sets are the downwards-closed subsets and then let B be the set of regular open sets ordered by inclusion. More on this below.)
What’s great about this is that since P is dense in B, all dense subsets of P are also dense subsets of B. This means that we can analyze properties of our M-generic ultrafilter G in B solely by looking at the dense subsets of P! This means that for many purposes you can simply ignore the Boolean algebra B and let it do its work in the background, while focusing on the partially ordered set (P, ≤) you picked out. The advantage of this should be obvious: there are many more partially ordered sets than there are Boolean algebras, so we have much more freedom to creatively choose P.
Let’s summarize everything by going over the outline we started with and filling in a few details:
Forcing in slightly more than 5 lines
- Fix a countable transitive model M ⊨ ZFC and a partial order (P, ≤) ∈ M.
- Extend P to a Boolean algebra (B, ≤) ∈ M.
- Define T := {A ⊆ P | A is closed downwards}.
- Define B := {S ∈ T | Int(Cl(S)) = S}.
- (B, ⊆) is a Boolean algebra: ¬A = Int(Ac), A∧B = A⋂B, A∨B = Int(Cl(A∪B)).
- P is order-isomorphic to a dense subset of B
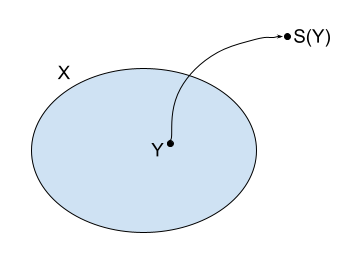
- For p ∈ P, define S(p) := {q ∈ P | q ≤ p} ∈ B.
- S is an order-isomorphism from P to B and {S(p) | p ∈ P} is dense in B.
- Define MB := { f ∈ M | f: MB ⇀ B }.
- Choose an M-generic ultrafilter G ⊆ B.
- Since M is countable, we can enumerate the dense subsets of B in M: (D0, D1, D2, …)
- Choose any b0 ∈ D0.
- For any n ∈ ℕ, since Dn+1 is dense in B, we can find a dn+1 ∈ Dn+1 s.t. dn+1 ≤ dn.
- G := { b ∈ B | b ≥ dn for some n ∈ ℕ } is an M-generic ultrafilter in B.
- For every n in MB, define valG(n) := { valG(m) | (m, b) ∈ n for some b in G }.
- Define M[G] := { valG(n) | n ∈ MB }.
- M[G] is a countable transitive model of ZFC.
- M ⊆ M[G]
- For any x ∈ M, define Nx := {(Ny,⊤) | y ∈ x} ∈ MB.
- Then valG(Nx) = x, so x ∈ M[G].
- G ∈ M[G]
- Define A := {(Nb, b) | b ∈ B} ∈ MB.
- valG(A) = G, so G ∈ M[G].
We are now ready to apply forcing to prove the independence of CH from ZFC! In Part 2 you will learn exactly what choice of P makes the cardinality of the continuum ≥ ℵ2 (thus making CH false) and what choice of P makes the cardinality of the continuum exactly ℵ1 (thus making CH true). In fact, I’ll do you one better: in Part 2 you’ll learn what to make P in order to make the cardinality of the continuum larger than ℵ69, ℵ420, or virtually any other cardinality you like!
End of Part 1. Part 2 here.