For background on how lambda diagrams work, look HERE.
The equivalence of lambda calculus with Turing machine computations, and the logical limitations on computation, combine to give us interesting limitative results on lambda diagrams.
Reducibility, Absolute and Contingent
We begin by defining a notion of reducibility. A lambda diagram is reduced if there is no beta reduction that can be applied to the diagram. Here are some examples of reduced diagrams:
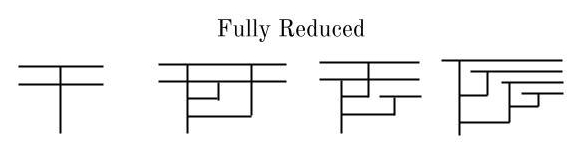
And here are some examples of non-reduced diagrams:
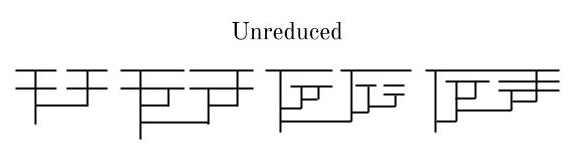
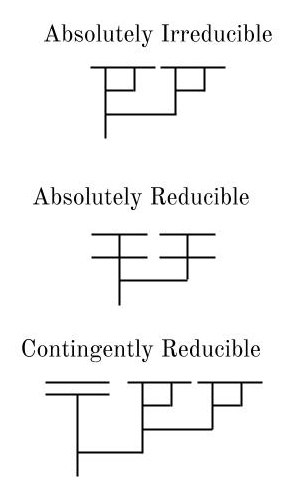
For each of these diagrams, if you keep applying beta reductions in any order you will eventually get to a point where the diagram is reduced. But this is not the case for all lambda diagrams. Check out the following diagram for M M (the Mockingbird function applied to itself):
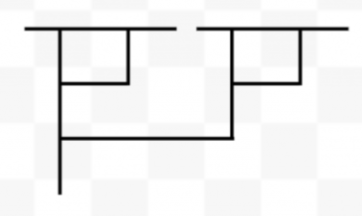
Applying beta reduction gives you the following:

And we’re back where we started! This tells us that our diagram is irreducible.
Sometimes there are multiple beta reductions that can be applied. In these cases, it might be that one sequence of beta reductions reduces the diagram, but another sequence goes forever without reducing it. For instance, here is the diagram for False (M M):
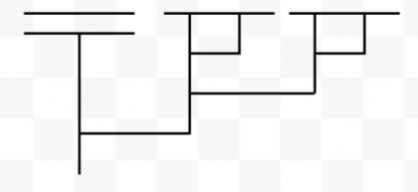
If we first feed (M M) as input to False, then we get a reduced diagram:

But if we first feed M to M, then what we get back is the same thing we started with:

If we keep feeding M to M, we keep getting back the same diagram and never fully reduce. When a diagram reduces on some series of beta reductions and never reduces on others, we call the diagram contingently reducible. If every strategy of beta reduction eventually reduces the diagram, we call it absolutely reducible. And if no strategy reduces the diagram, we call it absolutely irreducible.
Some interesting observations:
It’s possible for two diagrams A and B to both be absolutely reducible, but for A B to be absolutely irreducible.

It’s also possible for a diagram A to be absolutely irreducible, but the diagram A B to be contingently reducible (though never absolutely reducible).
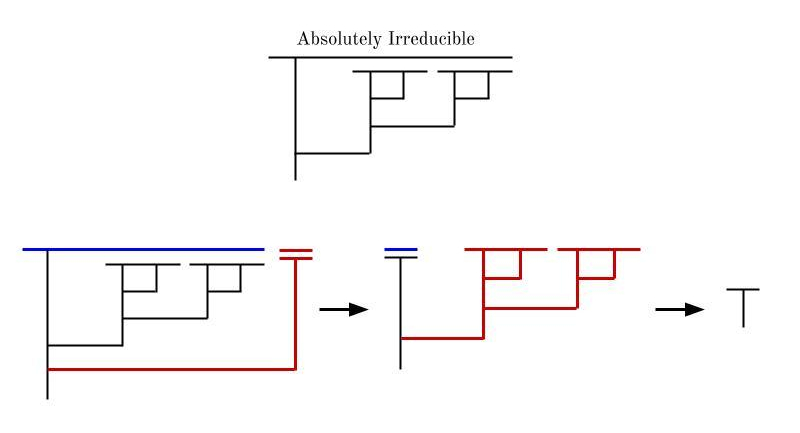
It’s not, however, possible for A to be absolutely irreducible but A B to be absolutely reducible. Why? Simply because you can choose your reduction strategy for A B to be any of the reduction strategies for A, each of which always fails. In general, if any sub-diagram within a lambda diagram is contingently reducible, then the whole diagram cannot be absolutely reducible. Why? Simply because you can choose your reduction strategy for the whole diagram to be a reduction strategy that fails for the sub-diagram (at least one such strategy must exist, by our assumption that the sub-diagram is only contingently reducible). This same reduction strategy that fails for the sub-diagram, also fails for the whole diagram. So the whole diagram cannot be absolutely reducible.
Here’s a question that I don’t know the answer to: Is it possible for an application of of an irreducible diagram to an irreducible diagram to be reducible? I suspect not.
The distinction between contingent and absolute reducibility goes away the moment you fix a general reduction strategy that for any diagram gives a unique prescription for which reduction should be applied (if any are possible). Henceforth, I will assume that a particular reduction strategy has been fixed, and so will only speak of reducibility and irreducibility, no absolutes and contingents.
Reducibility Oracles
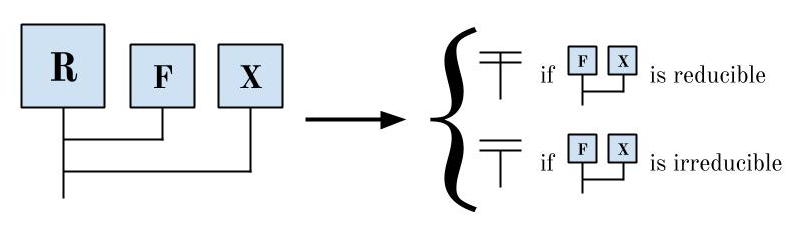
It might be convenient if we could always know whether a given diagram reduces or not. We might even wonder if there’s a lambda diagram that “computes” the answer to this question. Let’s suppose there is such a diagram, which we’ll call a “reducibility oracle.” It’s a black box, so we’ll denote its diagram as a box with an R:

We’ll define the behavior of the reducibility behavior as follows:
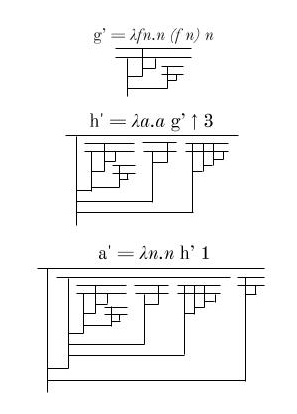
We’ll now design a larger diagram R’ that uses R:
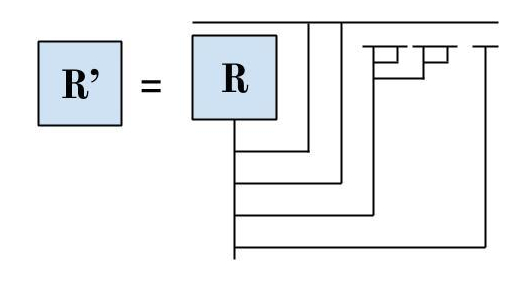
Let’s see how R’ behaves when given an input (call it F).
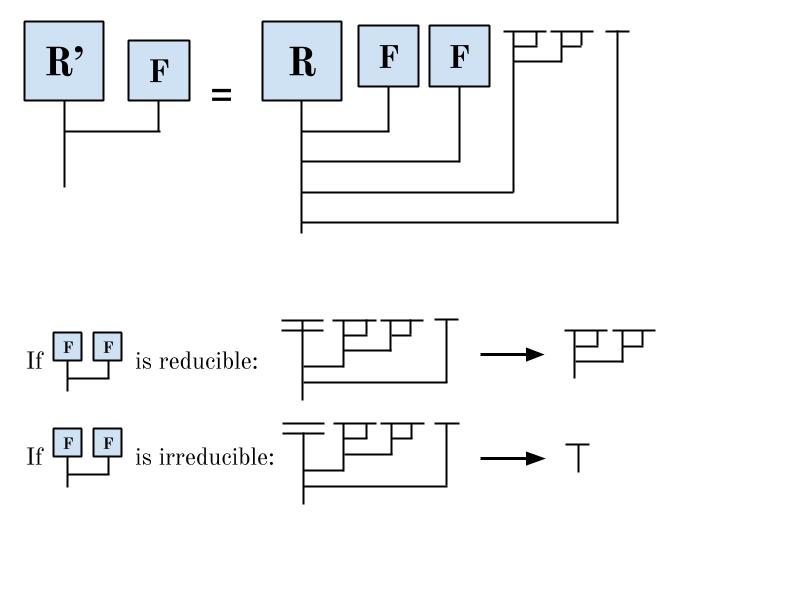
Notice that if F F is reducible, then R’ F is irreducible. And if F F is irreducible, then R’ F is reducible.
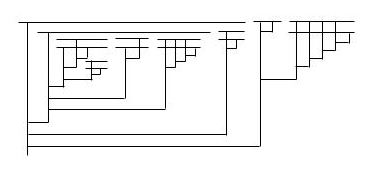
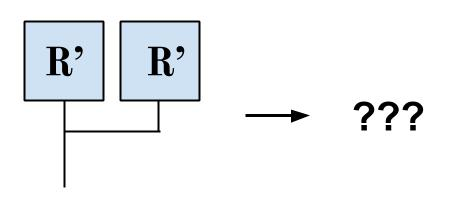
So what happens if we feed R’ to itself? Well, by the logic of the above paragraph, if R’ R’ is reducible, then R’ R’ is irreducible. And if R’ R’ is irreducible, then R’ R’ is reducible. We have obtained a contradiction! And so no such reducibility oracle diagram can exist.

But wait, there’s more!
Let’s define S(N) to be the size of the smallest lambda diagram that reduces to the Church numeral N, where size means the number of lines required to build the diagram.
There’s a tight correspondence between lambda calculus and programming languages. In fact, lambda calculus can be thought of as just one specific highly abstract functional programming language (along the lines of Haskell and Lisp). Recall now that the Kolmogorov complexity K of a string s (given a particular programming language) is defined as the shortest program that outputs that string. If we choose our programming language to be lambda calculus, then we get a correspondence between K(N) and S(N). This correspondence gives us the following results:
There is no lambda diagram that serves as a “size oracle” – i.e. a lambda diagram that when fed a number N, returns S(N). (Analogous to the uncomputability of Kolmogorov complexity)
For any sound proof system F, there’s a number L such that F cannot prove that the smallest lambda diagram that reduces to any number has more than L lines. (Analogous to Chaitin’s incompleteness theorem).
Sizes of lambda diagrams
Let me make some final notes on the function S(N). Every number has a “standard form”: λfx.f (f … (f x))), with N copies of f. The lambda diagram for this looks like an upside down ladder with N steps:
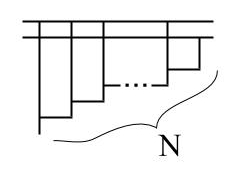
This has 2N + 3 lines, so we know that for all N, S(N) ≤ 2N + 3. We can define a number as “irreducibly complex” if S(N) = 2N + 3. For instance, 0 and 1 are irreducibly complex, and I think that 2 and 3 are as well:
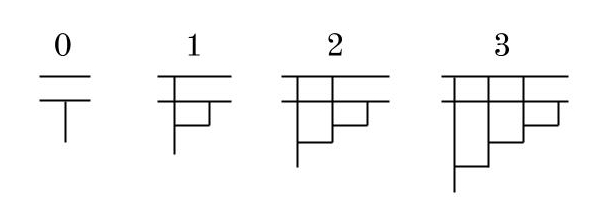
This raises an interesting question: What is the smallest number that isn’t irreducibly complex? Another question is whether there are arbitrarily large irreducibly complex numbers (I strongly suspect not, but am not positive).
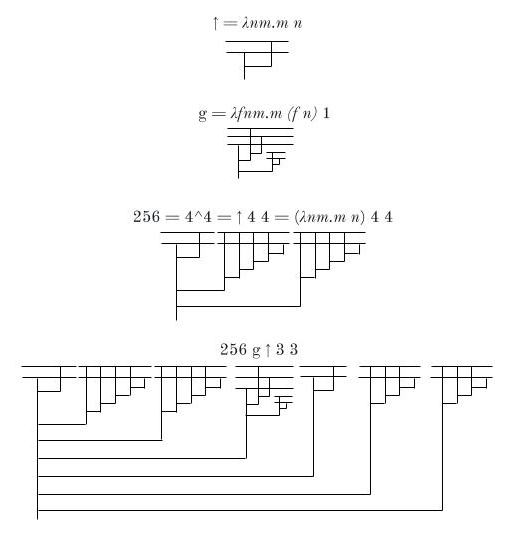
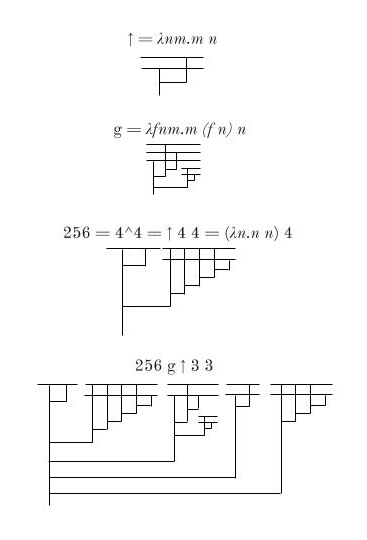
We can find some upper bounds for S(N), where N is a product or a power, as follows:
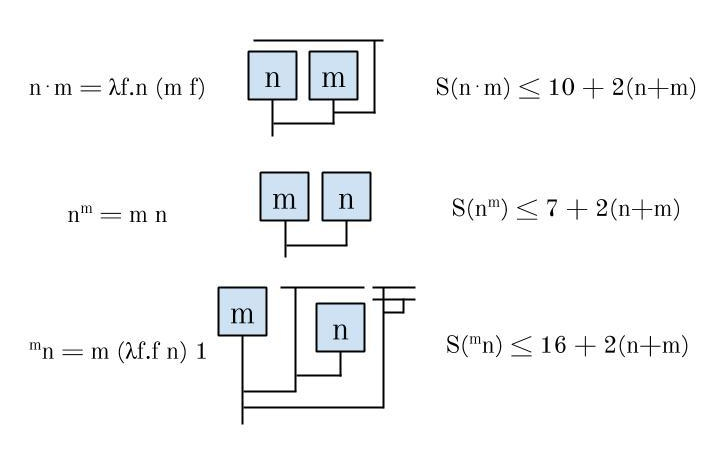
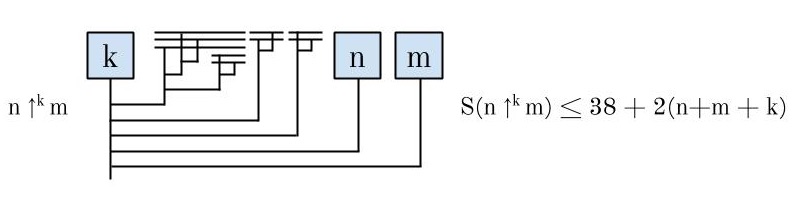
In general, for any computable function f whatsoever, there is a lambda diagram for f, to which we can append the diagram for any number N to represent f(N). The size of this diagram will just be the size of the diagram for f, plus the size of the diagram for N, plus 1 (for the line connecting the two). This means that if a number M can be written as f(N) for some computable f, then we can produce a diagram for M whose size is some constant + 2N. Thus S(f(N)) grows at most linearly with respect to N, no matter how fast-growing f is.