Previous: Introduction
What is a hypernatural number? It is a collection of infinitely long sequences of natural numbers. More precisely, it is an equivalence class of these infinite sequences.
An equivalence class under what equivalence relation? This is a little tricky to describe.
I’ll start with a slight lie to simplify the story. When we see the trouble that results from our simple definition, I will reveal the true nature of the equivalence relation that gives the hypernaturals. In the process you’ll see how the notion of an ultrafilter naturally arises.
So, hypernaturals are all about infinite sequences of natural numbers. Some examples of these:
(0,1,2,3,4,5,6,7,8,9,…)
(0,1,0,2,0,3,0,4,0,5,…)
(1,2,1,2,1,2,1,2,1,2,…)
(0,2,4,6,8,10,12,14,…)
(3,1,4,1,5,9,2,6,5,3,…)
We’ll define an equivalence relation ~ between sequences as follows:
Let x and y be infinite sequences of natural numbers.
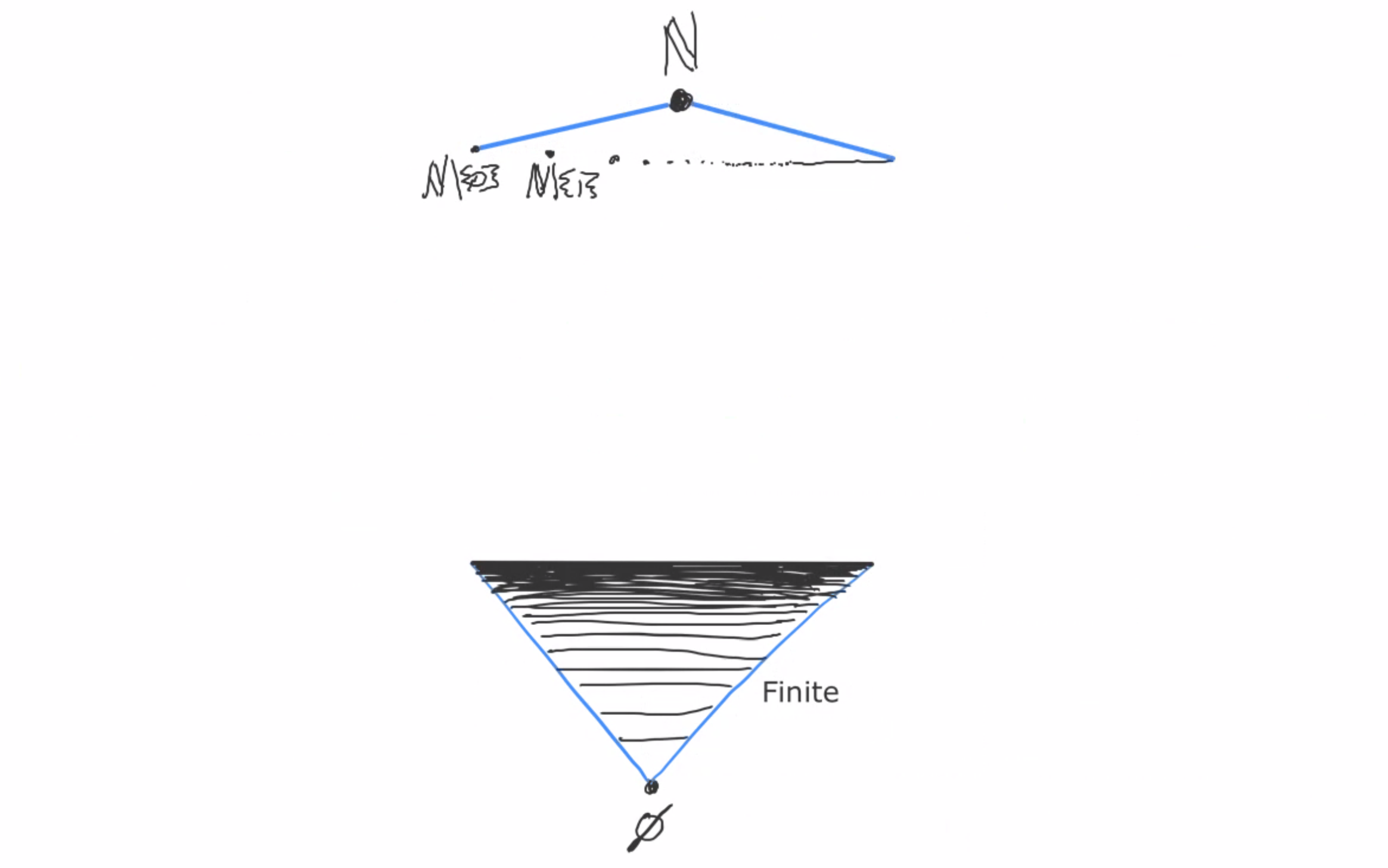
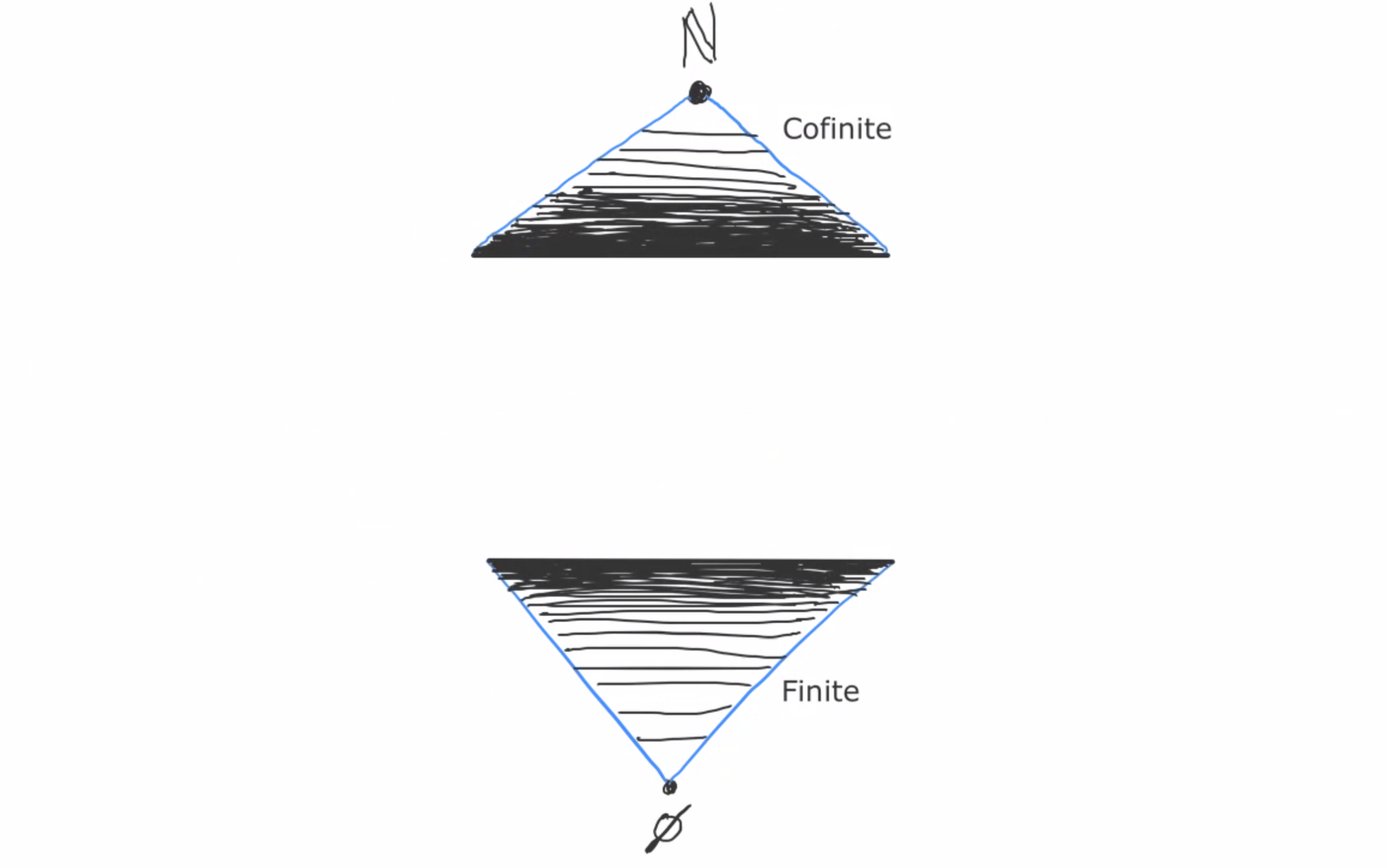
Then x ~ y iff x and y agree in all but finitely many places.
For example, (0,1,2,3,4,5,6,…) ~ (19,1,2,3,4,5,6,…), because these two sequences only disagree at one spot (the zero index).
(1,1,2,2,4,4,…) and (1,2,4,8,…) are not equivalent, because these sequences disagree at infinitely many indices (every index besides the zeroth index).
Same with (0,1,2,3,4,5,6,…) and (1,2,3,4,5,6,7,…); even though they look similar, these sequences disagree everywhere.
(2,4,6,8,10,12,14,…) and (2,0,6,0,10,0,14,…) are not equivalent, because these sequences disagree at infinitely many indices (every odd index).
One can easily check that ~ is an equivalence relation, and thus it partitions the set of sequences of naturals into equivalence classes. We’ll denote the equivalence class of the sequence (a1, a2, a3, …) as [a1, a2, a3, …]. These equivalence classes are (our first stab at the definition of) the hypernaturals!
For instance, the equivalence class of (0,0,0,0,0,…) contains (1,4,2,0,0,0,0,0,…), as well as (0,2,4,19,0,0,0,0,…), and every other sequence that eventually agrees with (0,0,0,0,…) forever. So all of these correspond to the same hypernatural number: [0,0,0,0,…]. This object is our first hypernatural number! It is in fact the hypernatural number that corresponds exactly to the ordinary natural number 0. In other words 0 = [0,0,0,0,…].
[1,1,1,1,…] is a distinct equivalence class from [0,0,0,0,…]. After all, the sequences (0,0,0,0,…) and (1,1,1,1,…) disagree everywhere. You might guess that [1,1,1,1,…] is the hypernatural analogue to the natural number 1, and you’d be right!
For any standard natural number N, the corresponding hypernatural number is [N,N,N,N,N,…], the equivalence class of the sequence consisting entirely of Ns.
Now consider the hypernatural [0,1,2,3,4,5,6,…]. Let’s call it K. Does K = N for any standard natural number N? In other words, is (0,1,2,3,4,5,6,…) ~ (N,N,N,N,N,…) true for any finite N? No! Whatever N you choose, it will only agree with (0,1,2,3,4,5,6,…) at one location. We need cofinite agreement, and here we have merely finite agreement. Not good enough! This means that K is our first nonstandard natural number!
How does K relate to the standard naturals in terms of order? We haven’t talked about how to define < on the hypernaturals yet, but it’s much the same as our definition of =.
[a1, a2, a3, …] = [b1, b2, b3, …]
iff
{ k∈ℕ | ak = bk } is cofinite
[a1, a2, a3, …] < [b1, b2, b3, …]
iff
{ k∈ℕ | ak < bk } is cofinite
Exercise: Verify that this is in fact a well-defined relation. Every equivalence class has many different possible representatives; why does the choice of representatives not matter for the purpose of describing order?
Now we can see that K > N for every standard N. Look at (0,1,2,3,4,5,…) and (N,N,N,N,…). The elements of the first sequence are only less than the elements of the second sequence at the first N indices. Then the elements of K are greater than the elements of N forever. So elements of K’s representative sequence are greater than elements of N’s representative sequence in a cofinite set of indices. Thus, K > N for every standard N. So K is an infinitely large number!
Here’s another one: K’ = [0,2,4,6,8,…]. You can see that K’ > K, because the elements of K’ are greater than those of K at all but one index (the first one). So we have another, bigger, infinite number.
Addition and multiplication are defined elementwise, so
K + K
= [0,1,2,3,4,…] + [0,1,2,3,4,…]
= [0+0, 1+1, 2+2, 3+3, 4+4, …]
= [0,2,4,6,8,…]
= K’
K’
= [0,2,4,6,8,…]
= [2⋅0, 2⋅1, 2⋅2, 2⋅3, 2⋅4, …]
= 2⋅[0,1,2,3,4,…]
= 2⋅K
Predictably, we get many many infinities. In fact, there are continuum many nonstandard hypernatural numbers!
Proof: we construct an injection f from ℝ to *ℕ. If x is a real number, then f(x) := [floor(x), floor(10x), floor(100x), floor(1000x), …]. For example, f(35.23957…) = [35,352,3523,35239,352395, …]. For any two distinct reals x and y, the sequences x and y will eventually disagree forever. So each real is mapped to a distinct hypernatural, meaning that there are no more reals than hypernaturals. At the same time, there are no more hypernaturals than reals, because there are only continuum many countable sequences of natural numbers. So |*ℕ| = |ℝ|.
It turns out that every nonstandard hypernatural number is also larger than every standard natural number. We’ll see why in a bit, but it’ll take a bit of subtlety that I’ve yet to introduce.
Now, > is transitive in ℕ. Is it also transitive in *ℕ? Yes! Suppose A > B and B > C. Choose any representative sequences (a1, a2, a3, …), (b1, b2, b3, …), and (c1, c2, c3, …) for A, B, and C. Then X = { k∈ℕ | ak > bk } and Y = { k∈ℕ | bk > ck } are both cofinite. The intersection of cofinite sets is also cofinite, meaning that X⋂Y = { k∈ℕ | ak > bk and bk > ck } ⊆ { k∈ℕ | ak > ck } is cofinite. So A > C!
It’s a good sign that > is transitive. But unfortunately, the story I’ve told you thus far starts to break down here. The greater-than relation is a total order on the natural numbers. For any naturals a and b, exactly one of the following is true: a = b, a > b, b > a. But this is not true of the hypernaturals!
Consider the two hypernatural numbers n = [0,1,0,1,0,1,…] and m = [1,0,1,0,1,0,…]. Are n and m equal? Clearly not; they disagree everywhere. So n ≠ m.
Is n > m? No. The set of indices where n’s sequence is greater than m’s sequence is {1, 3, 5, 7, …}, which is not cofinite.
So is m > n? No! The set of indices where m’s sequence is greater than n’s sequence is {0, 2, 4, 6, …}, which is also not cofinite!
So as we’ve currently defined the hypernatural numbers, the > relation is not a total relation on them. This might be fine for some purposes, but we’ll be interested in defining the hypernaturals to mirror the properties of the naturals as closely as possible. So we’ll have to tweak our definition of the hypernaturals. The tweak will occur way back at the start where we defined our equivalence relation on sequences of naturals.
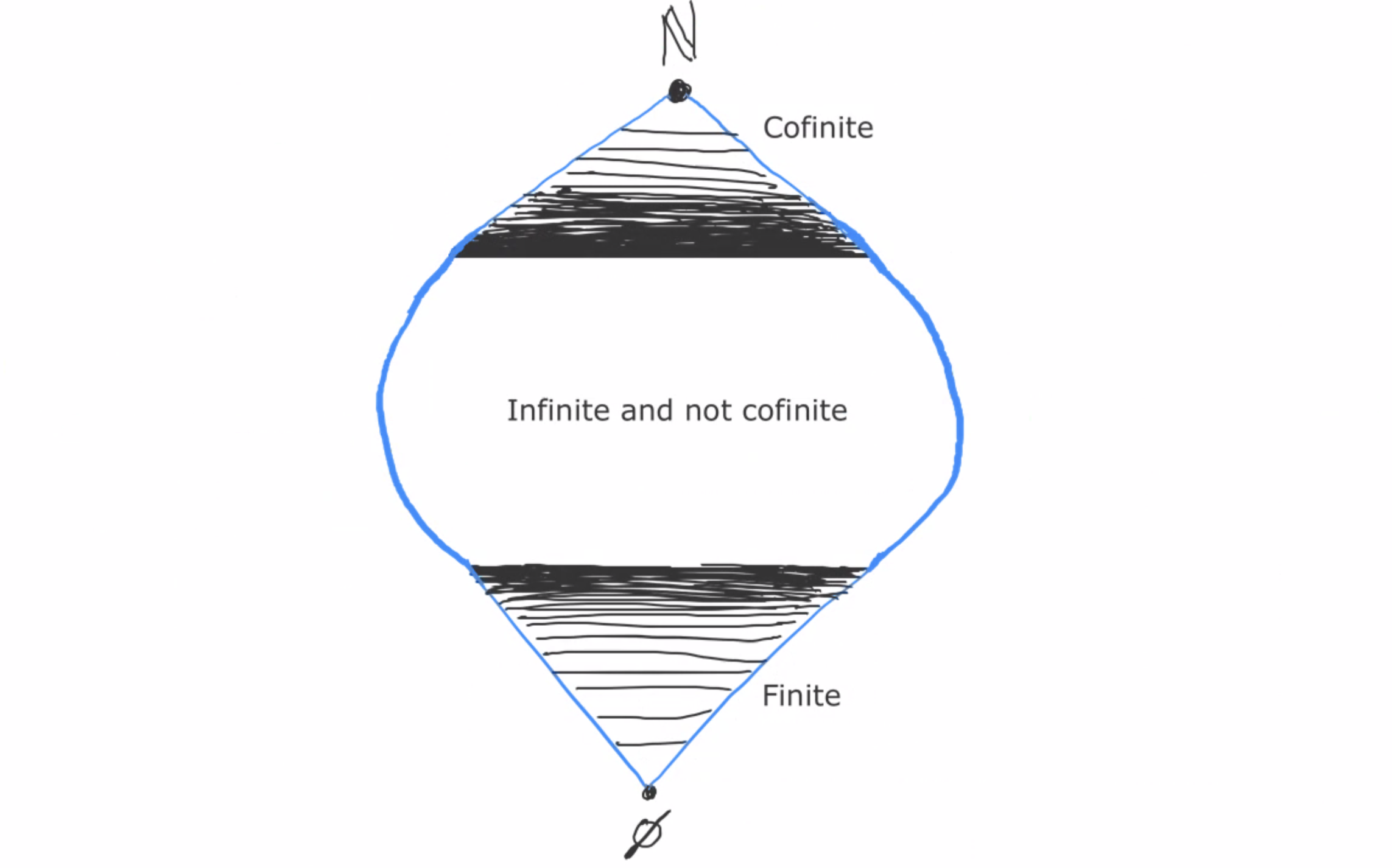
Recall: we said that two sequences (a1, a2, a3, …) and (b1, b2, b3, …), are equivalent if they agree in all but finitely many places. Said another way: a ~ b if { k∈ℕ | ak = bk } is cofinite. We defined > similarly: a > b if the agreement set for > is cofinite.
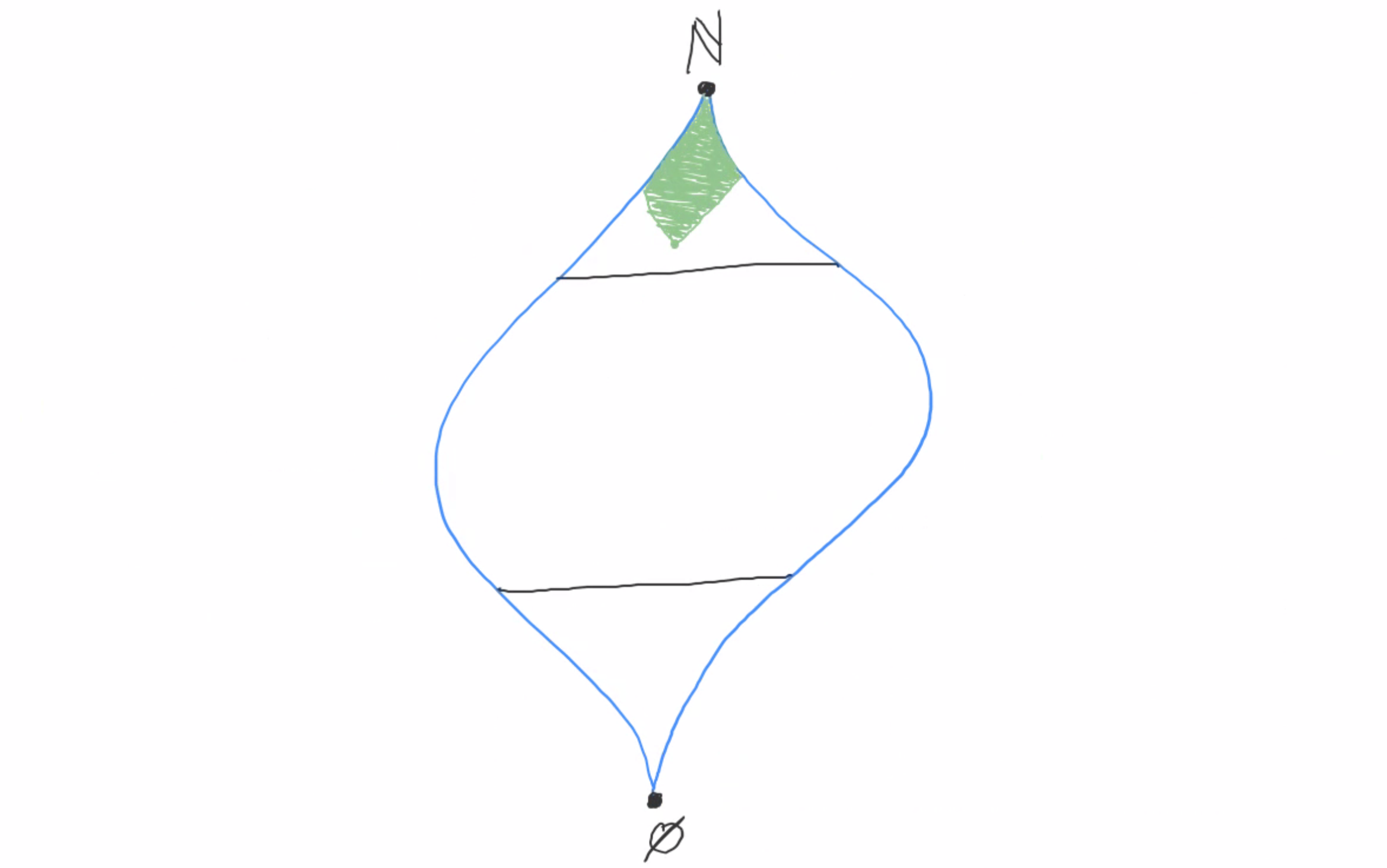
The problem with this definition was that it wasn’t definitive enough. There are cases where the agreement set is neither cofinite nor finite. (Like in our previous example, where the agreement set was the evens.) In such cases, our system gives us no direction as to whether a > b or b > a. We need a criterion that still deals with all the cofinite and finite cases appropriately, but also gives us a definitive answer in every other case. In other words, for ANY possible set X of indices of agreement, either X or X’s complement must be considered “large enough” to decide in its favor.
For example, maybe we say that if { k∈ℕ | ak = bk } = {0,2,4,6,8,…}, then a > b. Now our criterion for whether a > b is: the set of indices for which ak = bk is either cofinite OR it’s the evens. This implies that [1,0,1,0,1,0,…] > [0,1,0,1,0,1,…].
Once we’ve made this choice, consistency forces us to also accept other sets besides the evens as decisive. For instance, now compare (0,0,1,0,1,0,…) and (0,1,0,1,0,1,…). The set of indices where the first is greater than the second is {2,4,6,8,…}. But notice that the first differs only cofinitely from (1,0,1,0,…), meaning that [0,0,1,0,1,0,…] = [1,0,1,0,1,0,…]. The conclusion is that [0,0,1,0,1,0,…] > [0,1,0,1,0,1,…], which says that the set of indices {2,4,6,8,…} must also be decisive. And in general, once we’ve accepted the evens as a decisive set of indices, we must also accept the evens minus any finite set.
The three criterion we’ve seen as desirable for what sets of indices will count as decisive are (1) includes all cofinite sets, (2) for any set X, either X or X’s complement is decisive, and (3) consistency. These requirements turn out to correspond perfectly to a type of mathematical object called a free ultra-filter!
In the next post, we will define ultrafilters and finalize our definition of the hypernatural numbers!