Goodstein sequences are amazingly strange and unintuitive. I want to tell you all their unusual properties up-front, but I also don’t want to spoil the surprise. So let me start by defining the Goodstein sequence of a number.
We start by defining the hereditary base-n representation of a number m. We first write m as a sum of powers of n (e.g. for m = 266 and n = 2, we write 266 = 28 + 23 + 21). Now we write each exponent as a sum of powers of n. (So now we have 266 = 223 + 22+1 + 21). And we continue this until all numbers in the representation are ≤ n. For 266, our representation stabilizes at 266 = 222+1 + 22+1 + 21.
Now we define Gn(m) as follows: if m = 0, then Gn(m) = 0. Otherwise, Gn(m) is the number produced by replacing every n in the hereditary base-n representation of m by n+1 and subtracting 1. So G2(266) = G2(222+1 + 22+1 + 21) = 333+1 + 33+1 + 31 – 1 ≈ 4.4 × 1038.
Finally, we define the Goodstein sequence for a number n as the following:
a0 = n
a1 = G2(a0)
a2 = G3(a1)
a3 = G4(a2)
And so on.
Let’s take a small starting number and look at its Goodstein sequence. Suppose we start with 4.
a0 = 4 = 22
a1 = 33 – 1 = 2⋅32 + 2⋅3 + 2 = 26
a2 = 2⋅42 + 2⋅4 + 1 = 41
a3 = 2⋅52 + 2⋅5 = 60
a4 = 2⋅62 + 2⋅6 – 1 = 2⋅62 + 6 + 5 = 83
a5 = 2⋅72 + 7 + 4 = 109
Now, notice that the sequence always seems to increase. And this makes sense! After all, each step we take, we increase the base of each exponent by 1 (a big increase in the value) and only subtract 1. Here’s a plot of the first 100 values of the Goodstein sequence of 4:

And for further verification, here are the first million values of the Goodstein sequence of 4:

Looks like exponential growth to me! Which, again, is exactly what you’d expect. In addition, the higher the starting value, the more impressive the exponential growth we see. Here we have the first 100 values of the Goodstein sequence of 6:

Notice how after only 100 steps, we’re already at a value of 5 × 1010! This type of growth only gets more preposterous for larger starting values. Let’s look at the Goodstein sequence starting with 19.
a0 = 19
a1 ≈ 7 × 1012
a2 ≈ 1.3 × 10154
a3 ≈ 1.8 × 102184
And so on.
We can’t even plot a sequence like this, as it’ll just look like two perpendicular lines:

Alright, so here’s a conjecture that hopefully you’re convinced of: Goodstein sequences are always growing. In fact, let’s conjecture something even weaker: Goodstein sequences never terminate (i.e. never go to zero).
We’re finally ready for our first big reveal! Both of these conjectures are wrong! Not only do some Goodstein sequences terminate, it turns out that EVERY Goodstein sequence eventually terminates!
This is pretty mind-blowing. What about all those graphs I showed? Well, the sequences do increase for a very very long time, but they eventually turn around. How long is eventually? The Goodstein sequence of 4 takes 3 × 2402,653,210 – 1 steps to turn around!! This number is too large for me to be able to actually show you a plot of the sequence turning around. But we do know that once the Goodstein sequence stops increasing, it actually stays fixed for 3 × 2402,653,209 steps before finally beginning its descent to zero. Heuristically, it would look something like this:
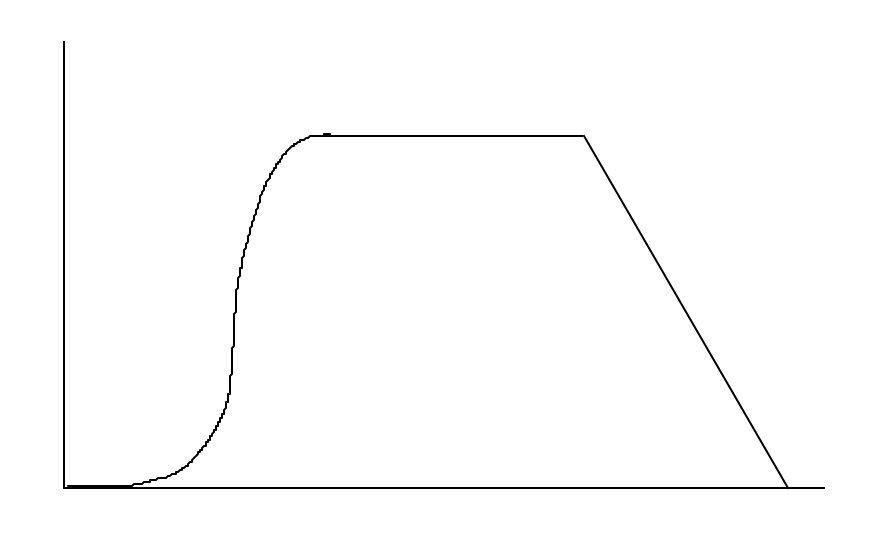
(Why does it stay constant, incidentally? The reason is that when we get to a number whose hereditary base-B notation just looks like B + n for some n < B, we increase B by 1 and decrease n by 1 each step. This doesn’t change the sequence’s value! So it stays constant until we get to n = 0. At that point, we decrease by 1 until we descend all the way to zero.)
So, how do we prove this? We do it using infinite ordinals. (Now you see why this topic caught my eye recently!) The plan is to associate with Goodstein sequence a “matching sequence” of ordinals. The way to do this is pretty simple: for a number written in hereditary base-n notation, just replace every n in that representation with ω. Now you have an infinite ordinal!
So, for example, here’s the first few numbers in the Goodstein sequence of 4, along with their translation to ordinals:
4 = 22 becomes ωω
26 = 33 – 1 = 2⋅32 + 2⋅3 + 2 becomes ω2⋅2 + ω⋅2 + 2
41 = 2⋅42 + 2⋅4 + 1 becomes ω2⋅2 + ω⋅2 + 1
60 = 2⋅52 + 2⋅5 becomes ω2⋅2 + ω⋅2
83 = 2⋅62 + 2⋅6 – 1 = 2⋅62 + 6 + 5 becomes ω2⋅2 + ω + 5
109 = 2⋅72 + 7 + 4 becomes ω2⋅2 + ω + 4
Examine this sequence of ordinals for a couple of minutes. You might notice something interesting: at each step, the ordinal is decreasing! This turns out to always hold true. Let’s see why.
Notice that there are two cases: either the ordinal is a successor ordinal (like ω2 + 4), or it’s a limit ordinal (like ω2 + ω). If it’s a successor ordinal, then the next ordinal in the sequence is just its predecessor. (So ω2 + 4 becomes ω2 + 3). This is obviously a smaller ordinal.
What if it’s a limit ordinal? Then the smallest limit ordinal in its expanded representation drops to a smaller limit ordinal and some finite number is added. So for instance, in the ordinal ω2 + ω⋅2, ω⋅2 will drop to ω and some finite number will be added on depending on which step in the sequence you’re at. So we’ll end up with ω2 + ω + n, for some finite n. This ordinal is smaller than the original one, because we’ve made an infinitely large jump downwards (from one limit ordinal to a lower limit ordinal), and only increased by a finite amount.
So in either case, we go to a smaller ordinal. And now the key realization is that every decreasing sequence of ordinals MUST terminate! (This is one of my favorite facts about ordinals, by the way. Even though we’re looking at arbitrarily large infinite ordinals, it’s still the case that there is no decreasing sequence that goes on forever. Whenever we hit a limit ordinal, we have to make an infinitely large jump downwards to get to the next element in the sequence, as the ordinal has no predecessor.)
So we’ve paired every Goodstein sequence with a decreasing sequence of ordinals. And every decreasing sequence of ordinals eventually terminates. So the Goodstein sequence must terminate as well! (One easy way to see this is to notice that every value in a Goodstein sequence is ≤ the ordinal assigned to it. Another way is to notice that the only number that could possibly be assigned to the ordinal 0 is 0 itself. So when the decreasing sequence of ordinals hits 0, as it must eventually, so must the Goodstein sequence) And that’s our proof!
That Goodstein sequences always terminate is the big flashy result for this post. But there’s much more that’s cool about them. For instance, the proof that we just used did not rely on the fact that we just increased the base by 1 at each step. In fact, even if we update the base by an arbitrarily large function at each stage, the sequences still must terminate!
Even cooler, the proof that all Goodstein sequences terminate cannot be formalized in Peano arithmetic! And in fact, no proof can be found of this theorem using PA. Laurie Kirby and Jeff Paris proved in 1982 that the statement that Goodstein sequences always terminate could be reduced to a theorem of Gentzen from which the consistency of PA could be deduced. So if PA could prove that Goodstein sequences always terminate, then it could prove its own consistency! Gödel’s second incompleteness theorem tells us that this cannot be, and thus assuming that PA really is consistent, it cannot prove that that these sequences all terminate.
This was historically the third result to be found independent of PA, and it was the first that was purely number-theoretic in character (as opposed to meta-mathematical, like the Gödel sentences). It gives us a very salient way of expressing the limitations of Peano arithmetic: simply write a program that computes the Goodstein sequence of any given input, terminating only when it reaches 0 and outputting the length of the sequence. (Code Golf Stack Exchange shows that this can be done using just 77 characters of Haskell! And here’s a nice way to do it in Python). Now, it happens to be true that this program will always terminate for any natural number input (if run on sufficiently powerful hardware). But Peano arithmetic cannot prove this!
As a final fun suprise, let’s define G(n) to be the length of the Goodstein sequence starting at n. As we’ve already seen, this sequence gets really big really quickly. But exactly how quickly does it grow? Turns out that it grows much much faster than other commonly known fast-growing computable functions. For instance, G(n) grows much faster than Ackermann’s function, and G(12) is already greater than Graham’s number!