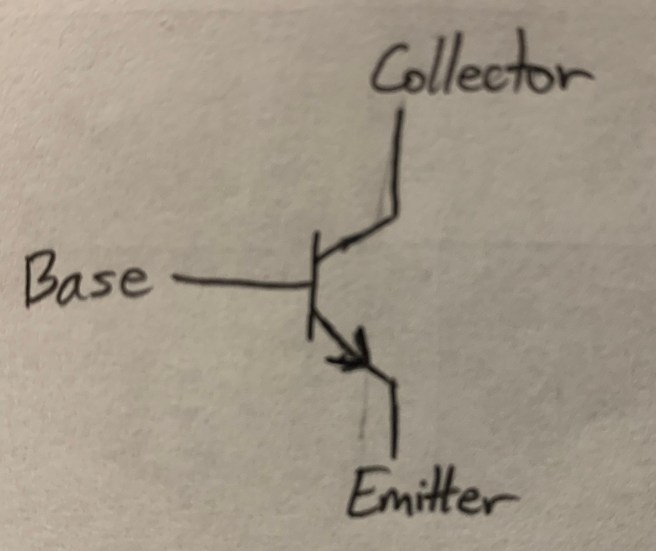
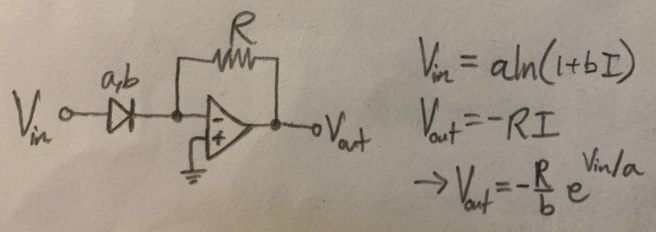
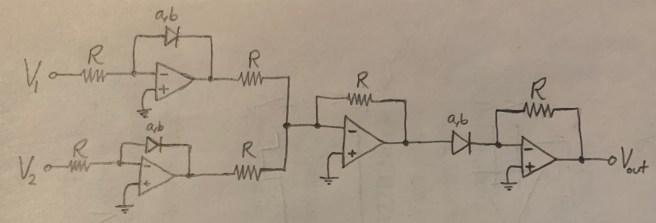
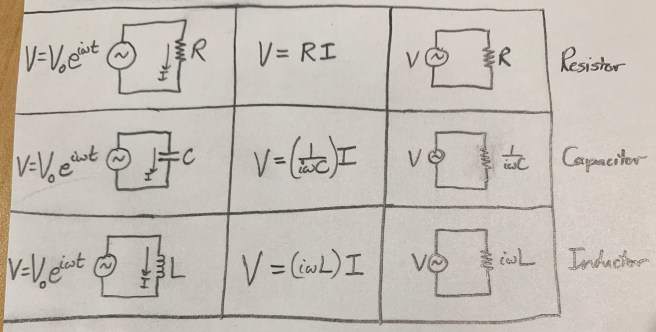
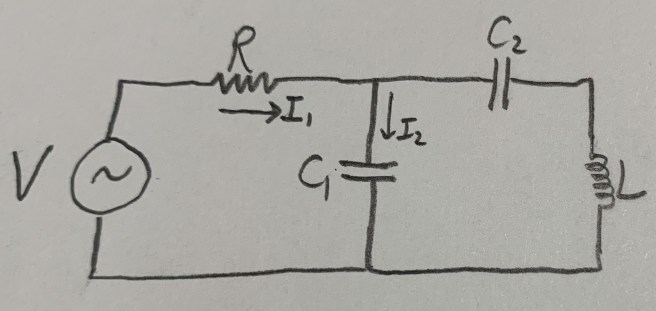
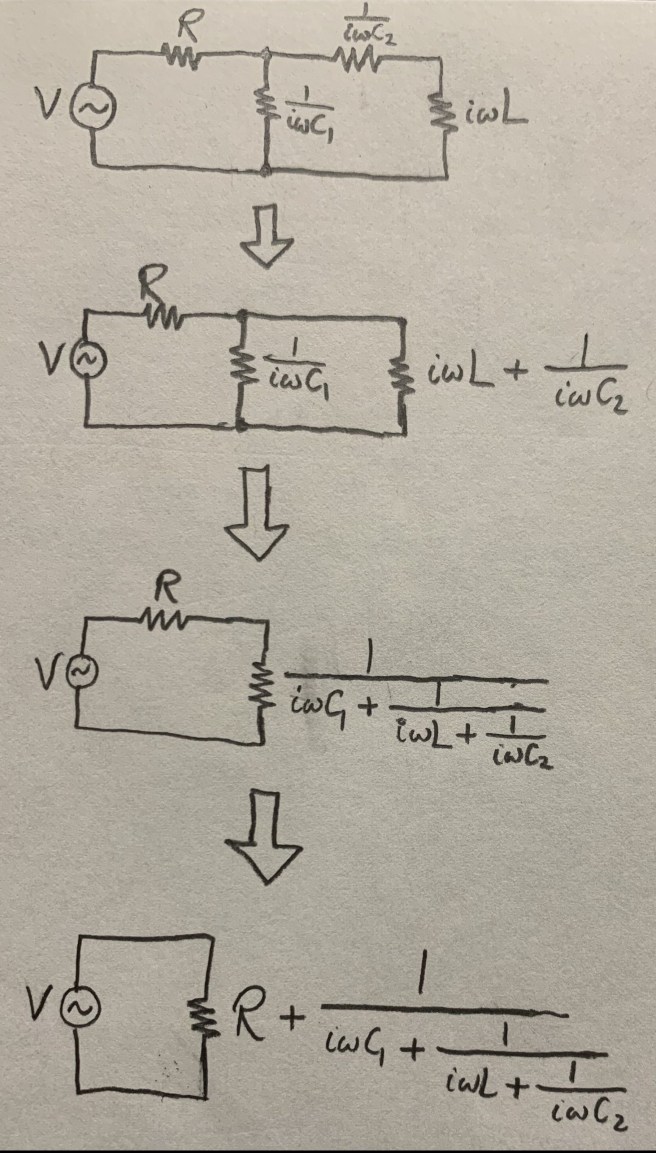
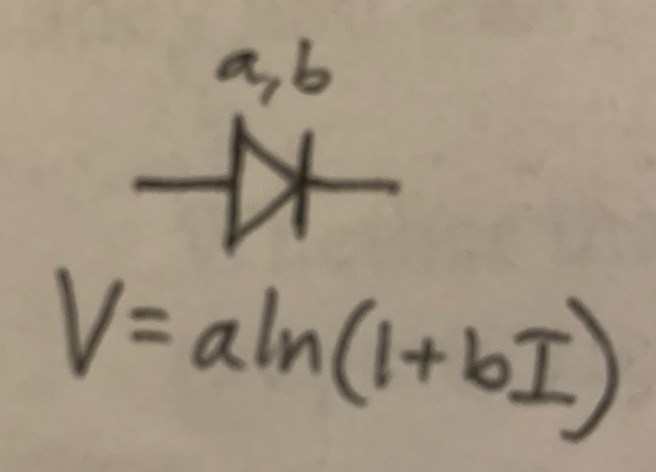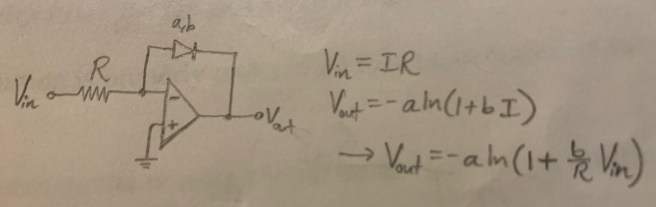Wittgenstein starts his Tractatus Philosophicus with the following two sentences.
1. The world is everything that is the case.
1.1 The world is the totality of facts, not of things.
Let’s take him up on this suggestion and see how far we get. In the process, we’ll discover some deep connections to theorems in mathematical logic, as well as some fascinating limitations on the expressive powers of propositional and first order logic.
We start out with a set of atomic propositions. For a very simple world, we might only need a finite number of these: “Particle 1 out of 3 has property 1 out of 50”, “Particle 2 of 3 has property 17 out of 50”, and so on. More realistically, the set of atomic propositions will be infinite (countable if the universe doesn’t have any continuous properties, and uncountable otherwise).
For simplicity, we’ll imagine labeling our set of atomic propositions P1, P2, P3, and so on (even though this entails that there are at most countably many, nothing important will rest on this assumption.) We combine these atomic propositions with the operators of propositional logic {(, ), ¬, ∧, ∨, →}. This allows us to build up more complicated propositions, like ((P7∧P2)→(¬P13)). This will be the language that we use to describe the world.
Now, the way that the world is is just a consistent assignment of truth values to the set of all grammatical sentences in our language. For example, one simple assignment of truth values is the one that assigns “True” to all atomic propositions. Once we’ve assigned truth values to all the atomic propositions, we get the truth values for the rest of the set of grammatical sentences for free, by the constraint that our truth assignment be consistent. (For instance, if P1 and P2 are both true, then (P1∧P2) must also be true.)
Alright, so the set of ways the world could be corresponds to the set of truth assignments over our atomic propositions. The final ingredient is the notion that we can encode our present knowledge of the world as a set of sentences. Maybe we know by observation that P5 is true, and either P2 or P3 is true but not both. Then to represent this state of knowledge, we can write the following set of sentences:
{P5, (P2∨P3), ¬(P2∧P3)}
Any set of sentences picks out a set of ways the world could be, such that each of these possible worlds is compatible with that knowledge. If you know nothing at all, then the set of sentences representing your knowledge will be the empty set {}, and the set of possible worlds compatible with your knowledge will be the set of all possible worlds (all possible truth assignments). On the other extreme, you might know the truth values of every atomic proposition, in which case your state of knowledge uniquely picks out one possible world.
In general, as you add more sentences to your knowledge-set, you cut out more and more possible worlds. But this is not always true! Ask yourself what the set of possible worlds corresponding to the set {(P1∨¬P1), (P2∨¬P2), (P3∨¬P3)} is. Since each of these sentences is a tautology, no possible worlds are eliminated! So our set of possible worlds is still the set of all worlds.
Now we get to an interesting question: clearly for any knowledge-set of sentences, you can express a set of possible worlds consistent with that knowledge set. But is it the case that for any set of possible worlds, you can find a knowledge-set that uniquely picks it out? If I hand you a set of truth assignment functions and ask you to tell me a set of propositions which are consistent with that set of worlds and ONLY that set, is that always possible? Essentially, what we’re asking is if all sets of possible worlds are describable.
We’ve arrived at the main point of this essay. Take a minute to ponder this and think about whether it’s possible, and why/why not! For clarification, each sentence can only be finitely long. But! You’re allowed to include an infinity of sentences.
(…)
(Spoiler-hiding space…)
(…)
If there were only a finite number of atomic propositions, then you could pick out any set of possible worlds with just a single sentence in conjunctive normal form. But when we start talking about an infinity of atomic propositions, it turns out that it is not always possible! There are sets of possible worlds that are literally not describable, even though our language includes the capacity to describe each of those words and we’re allowed to include an infinite set of sentences.
There’s a super simple proof of this. Let’s give a name to the cardinality of the set of sentences: call it K. (We’ve been tacitly acting as if the cardinality is countable this whole time, but that doesn’t actually matter.) What’s the cardinality of the set of all truth assignments?
Well, each truth assignment is a function from all sentences to {True, False}. And there are 2K such assignments. 2K is strictly larger than K, so there are more possible worlds than there are sentences. Now, the cardinality of the set of sets of sentences is also 2K. But the set of SETS of truth of assignments is 22^K!
What this means is that we can’t map sets of sentences onto sets of truth assignments without leaving some things out! This proof carries over to predicate logic as well. The language for both propositional and predicate logic is unable to express all sets of possible worlds corresponding to that language!
I love this result. It’s the first hint in mathematical logic that syntax and semantics can come apart.
That result is the climax of this post. What I want to do with the rest of this post is to actually give an explicit example of a set of truth assignments that are “indescribable” by any set of sentences, and to prove it. Warning: If you want to read on, things will get a bit more technical from here.
Alright, so we’ll use a shortcut to denote truth assignments. A truth assignment will be written as a string of “T”s and “F”s, where the nth character corresponds to how the truth assignment evaluates Pn. So the all-true truth assignment will just be written “TTTTTT…” and the all-false truth assignment will be written “FFFFF…”. The truth assignment corresponding to P1 being false and everything else true will be written “FTTTTT…”. And so on.
Now, here’s our un-describable set of truth assignments. {“FFFFFF…”, “TFFFFF…”, “TTFFFF…”, “TTTFFF…”, …}. Formally, define Vn to be the truth assignment that assigns “True” to every atomic proposition up to and including Pn, and “False” to all others. Now our set of truth assignments is just {Vn | n ∈ ℕ}.
Let’s prove that no set of sentences uniquely picks out this set of truth assignments. We prove by contradiction. Suppose that we could find a set of sentences that uniquely pick out these truth assignments and none other. Let’s call this set A. Construct a new set of sentences A’ by appending all atomic propositions A: A’ = A ∪ {P1, P2, P3, …}.
Is there any truth assignment that is consistent with all of A’? Well, we can answer this by using the Compactness Theorem: A’ has a truth assignment if and only if every finite subset of A’ has a truth assignment. But every finite subset of A’ involves sentences from A (which are consistent with Vn for each n by assumption), and a finite number of atomic propositions. Since each finite subset of A’ is only asserting the truth of a finite number of atomic sentences, we can always find a truth assignment Vk in our set that is consistent with it, by choosing one that switches to “False” long after the last atomic proposition that is asserted by our finite subset.
This means that each finite subset of A’ is consistent with at least one of our truth assignments, which means that A’ is consistent with at least one of our truth assignments. But A’ involves the assertion that all atomic propositions are true! The only truth assignment that is consistent with this assertion is the all-true assignment! And is that truth assignment in our set? No! And there we have it, we’ve reached our contradiction!
We cannot actually describe a set of possible worlds in which either all atomic propositions are false, or only the first is true, or only the first two are true, or only the first three are true, and so on forever. But this might prompt the question: didn’t you just describe it? How did you do that, if it’s impossible? Well, technically I didn’t describe it. I just described the first four possibilities and then said “and so on forever”, assuming that you knew what I meant. To have actually fully pinned down this set of possible worlds, I would have had to continue with this sentence forever. And importantly, since this sentence is a disjunction, I could not split this infinite sentence into an infinite set of finite sentences. This fundamental asymmetry between ∨ and ∧ is playing a big role here: while an infinite conjunction can be constructed by simply putting each clause in the conjunction as a separate sentence, an infinite disjunction cannot be. This places a fundamental limit on the ability of a language with only finite sentences to describe the world.








 . The total amount of product on the market will be given the label
. The total amount of product on the market will be given the label 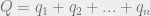 . Since the firms are all selling identical products, it makes sense to assume that the consumer demand function
. Since the firms are all selling identical products, it makes sense to assume that the consumer demand function  will just be a function of the total quantity of the product that is on the market:
will just be a function of the total quantity of the product that is on the market: 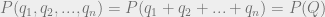 . (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)
. (This means that we’re also disregarding effects like customer loyalty to a particular company or geographic closeness to one company location over another. Essentially, the only factor in a consumer’s choice of which company to go to is the price at which that company is selling the product.)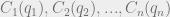 . Now we can figure out the profit of each firm for a given set of output values
. Now we can figure out the profit of each firm for a given set of output values  . This profit is just the amount of money they get by selling the product minus the cost of producing the product:
. This profit is just the amount of money they get by selling the product minus the cost of producing the product:  .
. . This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms!
. This is a set of n equations with n unknown, so solving this will fully specify the behavior of all firms! and
and 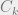 , we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.
, we can’t go too much further with solving this equation in general. To get some interesting general results, we’ll consider a very simple set of assumptions. Our assumptions will be that both consumer demand and producer costs are linear. This is the linear Cournot model, as opposed to the more general Cournot model.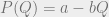 (for some a and b) and
(for some a and b) and  . As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
. As an example, we might have that P(Q) = $100 – $2 × Q, which would mean that at a price of $40, 30 units of the good will be bought total.
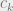 represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.)
represent the marginal cost of production for each firm, and the linearity of the cost function means that the cost of producing the next unit is always the same, regardless of how many have been produced before. (This is unrealistic, as generally it’s cheaper per unit to produce large quantities of a good than to produce small quantities.) . Rewriting, we get
. Rewriting, we get  . We can’t immediately solve this for
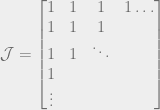
. We can’t immediately solve this for  , because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!
, because remember that Q is the sum of all the quantities produced. All n of the quantities we’re trying to solve are in each equation, so to solve the system of equations we have to do some linear algebra!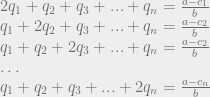






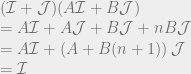


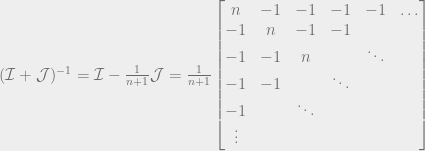
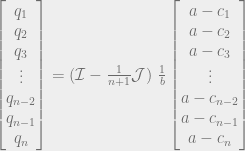
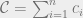
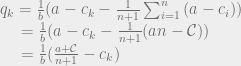
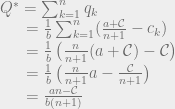
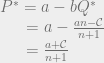



 intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity
intuitively corresponds to the highest possible price you could get for the product (the most that the highest bidder would pay). And the quantity  , the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
, the production cost, is the lowest possible price at which the product would be sold. So the monopoly price is the average of the highest price you could get for the good and the lowest price at which it could be sold.
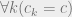

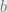 ) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!
) doesn’t show up at all in the ultimate market price, only the value that the highest bidder puts on the product!