Previously, we talked about the distinction between a logic, a language, a theory, and a model, and introduced propositional and first order logic. We toyed around with some simple first-order models, and began to bump our heads against the expressive limitations of the language of first order logic. Now it’s time to apply what we’ve learned to some REAL math! Let’s try to construct a first order theory of the natural numbers. N = {0, 1, 2, 3, …}
The first question we have to ask ourselves is what our language should be. What constants, predicates, and functions do we want to import into first order logic? There are many ways you could go here, but one historically popular approach is the following:
Constants: 0
Functions: S, +, ×
Predicates: ≥
We add just one constant, 0, three functions (a successor function to get the rest of the numbers from 0, as well as addition and multiplication), and one predicate for ordering the numbers. Let’s actually make this a little simpler, and talk about a more minimal language for talking about numbers:
Constants: 0
Functions: S
Predicates: None
This will be a good starting point, and from here we can easily define +, ×, and ≥ if necessary later on. Now, take a look at the following two axioms:
- ∀x (Sx ≠ 0)
- ∀x∀y (x ≠ y → Sx ≠ Sy)
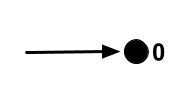
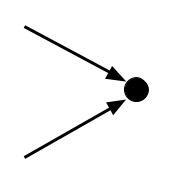
In plain English, axiom 1 says that 0 is not the successor of any number. And axiom 2 says that two different numbers can’t have the same successor.
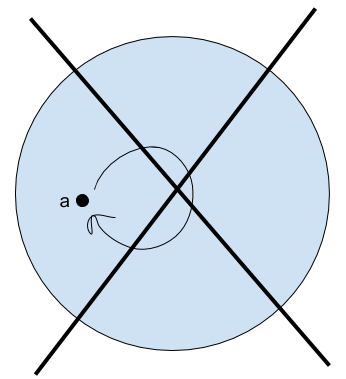
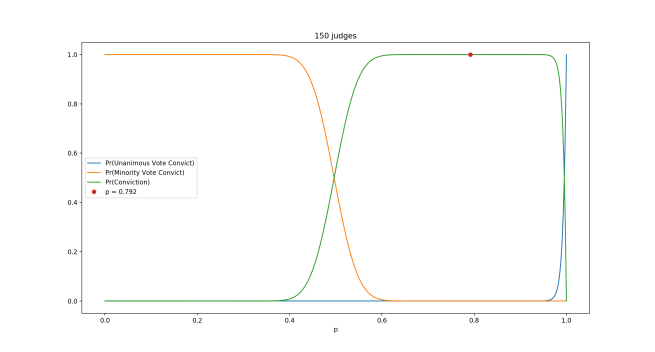
Visually, the first axiom tells us that this situation can’t happen:
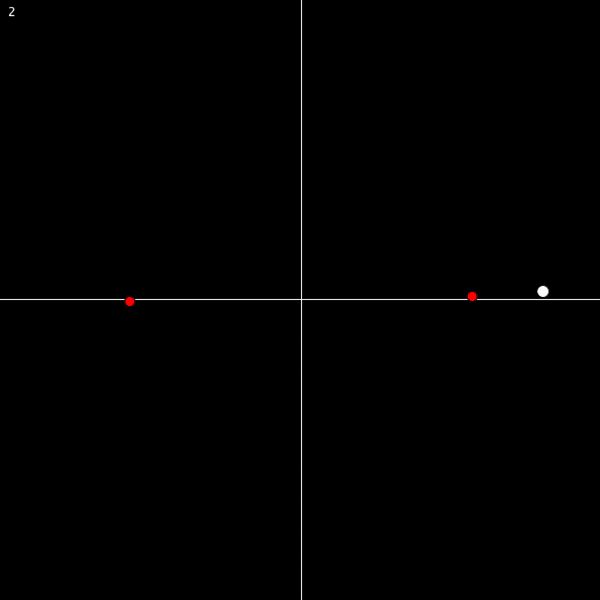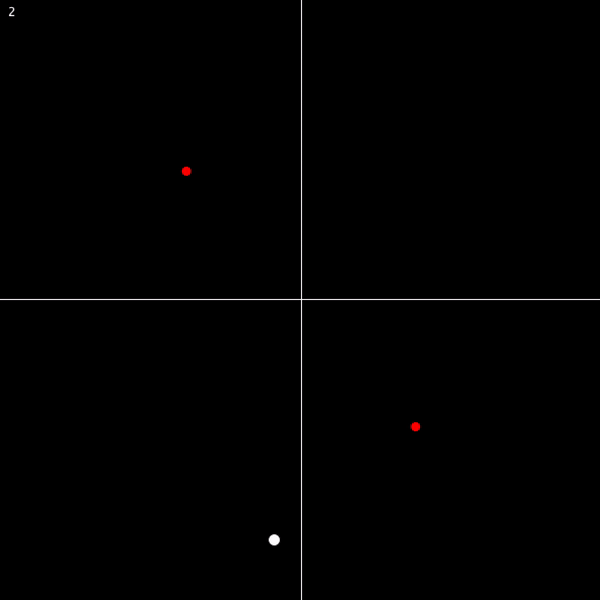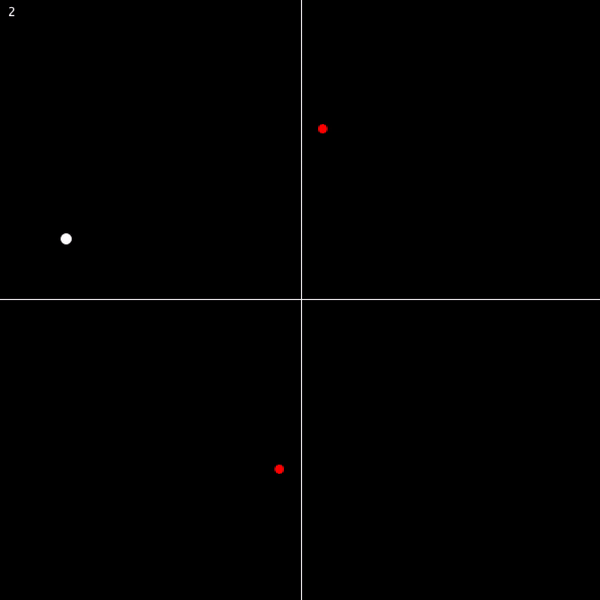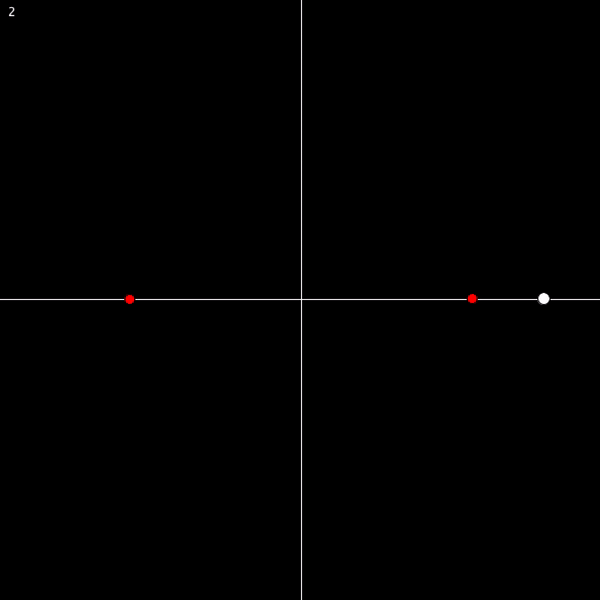
And the second axiom tells us that this situation can’t happen:
Now, we know that 0 is a number, because it’s a constant in our language.

By axiom 1, we know that S0 cannot be 0. So it’s something new.

S0 cannot go to 0, because of axiom 1. And it can’t go to itself, as that would be a violation of axiom 2. So it has to go to something new:

Now, where does SS0 get sent? Not to 0, for the same reason as before. And not to either S0 or SS0, because then we’d have a violation of axiom 2. So it must go to a new number. You can see where this is going.

These two axioms really cleverly force us to admit an infinite chain of unique new numbers. So is that it? Have we uniquely pinned down the natural numbers?
It turns out that the answer is no. Consider the following model:

This is perfectly consistent with our axioms! No number goes to 0 via the successor function, and no two different numbers have the same successor. But clearly this is not a model of the natural numbers. One quick and easy patch on this is just to add a new axiom, banning any numbers that are their own successor.
3. ∀x (Sx ≠ x)
Now, we’ve taken care of this problem, but it’s a symptom of a larger issue. Here’s a model that’s perfectly consistent with our new axioms:

In the same vein as before, we can patch this with a new axiom, call it 3’:
3’. ∀x (SSx ≠ x)
But now we have the problem of three-loops, which require their own axiom to be ruled out (3’’. ∀x (SSSx ≠ x)). And in general, this approach will end up requiring us to have an infinite axiom schema, one axiom for each loop length that we need to ban.
However, even then we’re not done! Why? Well, once we’ve banned all loops, we run into the following problem:

We can fix this by specifying that 0 is the only number that is not the successor of any number. Formally, this looks like:
∀x (∀y (Sy ≠ x) → x = 0)
Okay, so that takes care of other copies of the natural numbers. But we’re still not done! Take a look at the following model:

This model violates none of our axioms, but is clearly not the natural numbers. We’re running into a lot of problems here, and our list of axioms is getting really long and unwieldy. Is there any simpler system of axioms that will uniquely pin down the natural numbers for us?
The amazing fact is that no, this is not possible. In fact, no matter how hard you try, you will never be able to rule out models of your axioms that contain “nonstandard numbers” in first-order logic.
We’ll prove this using a beautiful line of reasoning, which I think of as one of the simplest and most profound arguments I’ve encountered. There’s several subtle steps here, so read carefully:
Step 1
We’re going to start out by proving a hugely important theorem called the Compactness Theorem.
- Suppose that a first order theory T has no model.
- Then there is no consistent assignment of truth values to all WFFs.
- So you can prove a contradiction from T. (follows from completeness)
- All proofs must be finite, so if you can prove a contradiction from T, you can do it in a finite number of steps.
- If the proof of contradiction takes a finite number of steps, then it uses only a finite number of T’s axioms.
- So there is a proof of contradiction from a finite subset of T’s axioms.
- So there’s a finite subset of T’s axioms that has no model. (follows from soundness)
- So if T has no model, then there’s a finite subset of T’s axioms that has no model.
The Compactness Theorem as it’s usually stated is the contrapositive of this: If all finite subsets of T’s axioms have a model, then T has a model. If you stop to think about this for a minute, it should seem pretty surprising to you. (It’s trivial for the case that T contains a finite number of axioms, of course, but not if T has an infinity of axioms.)
Also notice that our proof of the theorem barely relied on what we’ve said about the properties of first order logic at all! In fact, it turns out that there is a Compactness Theorem in any logic that is sound (syntactic entailment implies semantic entailment, or in other words: that which is provable is true in all models), complete (semantic entailment implies syntactic entailment, or: that which is true in all models is provable), and only allows finite proofs.
In other words, any logic in which the provable statements are exactly those statements that are true in all models, no more and no less, and in which infinite proofs are considered invalid, will have this peculiar property.
Step 2
Now, we use the Compactness Theorem to prove our desired result.
- Suppose we have a first order theory T that has the natural numbers N as a model.
- We create a new theory T’ by adding a constant symbol ω and adjoining an infinite axiom schema:
- ‘ω ≥ 0’
- ‘ω ≥ S0’
- ‘ω ≥ SS0’
- ‘ω ≥ SSS0’ (And so on…)
- N is no longer a model of T’, because T’ says that there is a number that’s larger than every natural number, which is false in N.
- But T’ still has a model, because of compactness:
- Any finite subset of the axioms of T’ has a finite number of statements that look like ‘ω > x’. But this is consistent with ω being a natural number! (because for any set of natural numbers you can find a larger natural number)
- So N is a model of any finite subset of the axioms of T’.
- So by compactness, T’ has a model. This model is nonstandard (because earlier we saw that it’s not N).
- Furthermore, any model of T’ is a model of T, because T’ is just T + some constraints.
- So since T’ has a nonstandard model, so does T.
- Done!
The conclusion is the following: Any attempt to model N with a first order theory is also going to produce perverse nonstandard models in which there are numbers larger than any natural number.
Furthermore, this implies that no first order theory of arithmetic can prove that there is no number larger than every natural number. If we could, then we would be able to rule out nonstandard models. But we just saw that we can’t! And in fact, we can realize that ω, as a number, must have a successor, which can’t be itself, and which will also have a successor, and so on forever, so that we will actually end up with an infinity of infinitely-large numbers, none of which we have any power to deny the existence of.
But wait, it gets worse! Compactness followed from just three super elementary desirable features of our logic: soundness, completeness, and finite provability. So this tells us that our inability to uniquely pin down the natural numbers is not just a problem with first order logic, it’s basically a problem with any form of logic that does what we want it to do.
Want to talk about the natural numbers in a Hilbertian logical framework, where anything that’s true is provable and anything that’s provable is true? You simply cannot. Anything you say about them has to be consistent with an interpretation of your statements in which you’re talking about a universe with an infinity of infinitely large numbers.
Löwenheim-Skolem Theorem
Just in case your mind isn’t sufficiently blown by the Compactness Theorem and its implications, here’s a little bit more weirdness.
The Löwenheim-Skolem Theorem says the following: If a first-order theory has at least one model of any infinite cardinality, then it has at least one model of EVERY infinite cardinality.
Here’s an intuition for why this is true: Take any first order theory T. Construct a new theory T’ from it by adding κ many new constant symbols to its language, for any infinite cardinality κ of your choice. Add as axioms c ≠ c’, for any two distinct new constant symbols. The consistency of the resulting theory follows from the Compactness Theorem, and since we got T’ by adding constraints to T, any model of T’ must be a model of T as well. So T has models of any infinite cardinality!
The Löwenheim-Skolem Theorem tells us that any first order theory with the natural numbers as a model also has models the size of the real numbers, as well as models the size of the power set of the reals, and the power set of the power set of the reals, and so on forever. Not only can’t we pin down the natural numbers, we can’t even pin down their cardinality!
And in fact, we see from this that no first-order statement can express the property of “being a specific infinite cardinality.” If we could do this, then we could just add this statement to a theory as an axiom and rule out all but one infinite cardinality.
Here’s one more for you: The Löwenhiem-Skolem Theorem tells us that any attempt to talk about the real numbers in first order logic will inevitably have an interpretation that refers solely to a set that contains a countable infinity of objects. This implies that in first order logic, almost all real numbers cannot be referred to!
Similarly, a first order set theory must have countable models. But keep in mind that Cantor showed how we can prove the existence of uncountably infinite sets from the existence of countably infinite sets! (Namely, just take a set that’s countably large, and power-set it.) So apparently, any first order set theory has countable models that… talk about uncountable infinities of sets? This apparent contradiction is known as Skolem’s paradox, and resolving it leads us into a whole new set of strange results for how to understand the expressive limitations of first order logic in the context of set theory.
All that and more in a later post!