(Nothing original here, just my presentation of the most interesting arguments I’ve seen on the various sides)
Newcomb’s problem: You find yourself in a room with two boxes in it. Box #1 is clear, and you can see $10,000 inside. Box #2 is opaque. A loud voice announces to you: “Box 2 has either 1 million dollars inside of it or nothing. You have a choice: Either you take just Box 2 by itself, or you take both Box 1 and Box 2.”
As you’re reaching forward to take both boxes, the voice declares: “Wait! There’s a catch.
Sometime before you entered the room, a Predictor with enormous computing power scanned you, made an incredibly detailed simulation of you, and used it to make a prediction about what decision you would make. The Predictor has done similar simulations many times in the past, and has never been wrong. If the Predictor predicted that you would take just Box 2, then it filled up the box with 1 million dollars. And if the Predictor predicted that you would take both boxes, then it left Box 2 empty. Now you may make your choice.”

The most initially intuitive answer to most people is to take both boxes. Here’s the strongest argument for why this makes sense, presented by Claus the causal thinker.
Claus: “The Predictor has already made its prediction and fixed the contents of the box. So we know for sure that my decision can’t possibly have any impact on whether Box 2 is full or empty. And in either case, I am better off taking both boxes than just one! Think about it like this: whether I one-box or two-box, I still end up taking Box 2. So let’s consider Box 2 taken – I have no choice in the matter. Now the only real question is if I’m also going to take Box 1. And Box 1 has $10,000 inside it! I can see it right there! My choice is really whether to take the free $10,000 or not, and I’d be a fool to leave it behind.”
***
Claus makes a very convincing argument. On his calculation, the expected value of two-boxing is strictly greater than the expected value of one-boxing, regardless of what probabilities he puts on the second box being empty. We’ll call this the dominance argument.
But Claus is making a fundamental error in his calculation. Let’s let a different type of decision theorist named Eve interrogate Claus.
Eve: “So, Claus, I’m curious about how you arrived at your answer. You say that your decision about whether or not to take Box 1 can’t possibly impact the contents of Box 2. I think that I agree with this. But do you agree that if you don’t take Box 1, it is more likely that Box 2 has a million dollars inside it?”
Claus: “I can’t see how that could be the case. The box’s contents are already fixed. How could my decision about something entirely causally unrelated make it any more likely that the contents are one way or the other?”
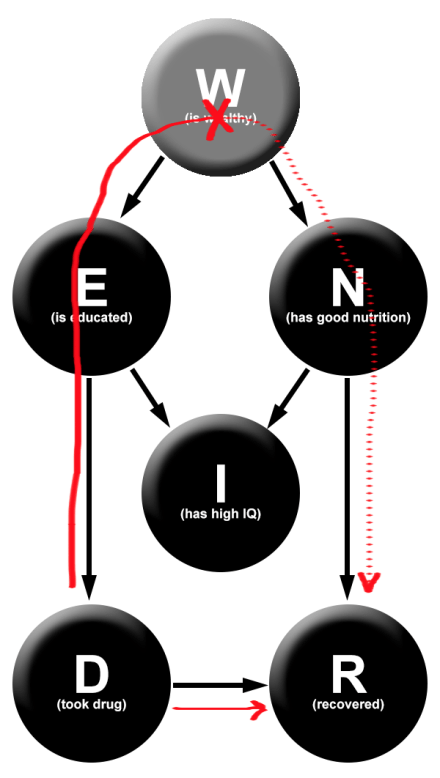
Eve: “Well, it’s not actually that unusual. There are plenty of things that are correlated without any direct causal impact between them. For example, say that a certain gene causes you to be a good juggler, but also causes a high chance of a certain disease. In this case, juggling ability and incidence of the disease will end up being correlated in the population, even though neither one is directly causing the other. And if you’re a good juggler, then you should be more worried that maybe you also have the disease!”
Claus: “Sure, but I don’t see how that case is anything like this one…”
Eve: “The two cases are actually structurally identical! Let me draw some causal diagrams…” (Claus rummages around for paper and a pencil)

Eve: “In our disease example, we have a common cause (the gene) that is directly causally linked to both the disease and to being a good juggler. So the “disease” variable and the “good juggler” variable are dependent because of the “gene” variable. In your Newcomb problem, the common cause is your past self at the moment that the Predictor scanned you. This common cause is directly linked to both your decision to one-box or two-box in the present, and to the contents of the box. Which means that in the exact same way that being a good juggler makes you more likely to have the disease, two-boxing makes you more likely to end up with an empty Box 2! The two cases are exactly analogous!”
Claus: “Hmm, that all seems correct. But even if my decision to take Box 1 isn’t independent of the contents of Box 2, this doesn’t necessarily mean that I shouldn’t still take both.”
Eve: “Right! But it does invalidate your dominance argument, which implicitly rested on the assumption that you could treat the contents of the box as if they were unaffected by your action. While your actions do not strictly speaking causally effect the contents of the box, they do change the likelihoods of the different possible contents! So there is a real sense in which your actions do statistically affect the contents of the box, even though they don’t causally affect them. Anyway, we can just calculate the actual expected values and see whether one-boxing or two-boxing comes out ahead.”
Eve writes out some expected utility calculations:
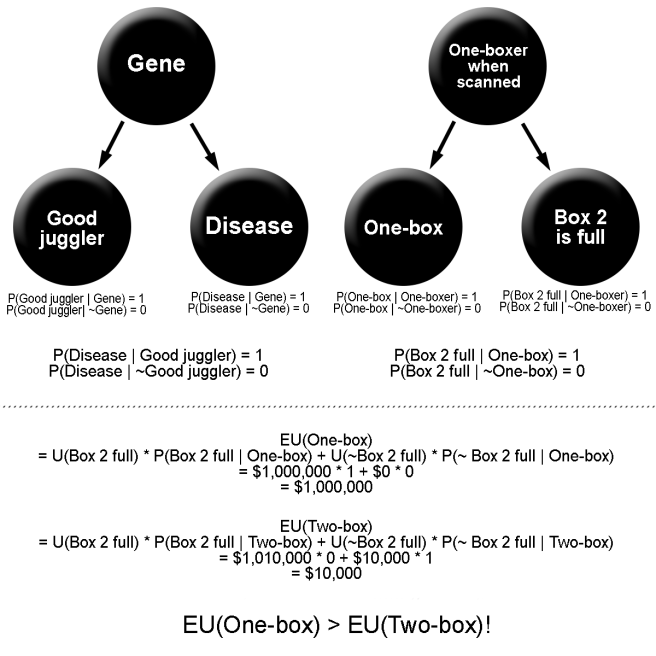
Eve: “So you see, it actually turns out to always be better to one-box than to two-box!”
Claus: “Hmm, I guess you’re right. Okay never mind, I guess that I’ll one-box. Thanks!”
***
Claus goes away for a while, and comes back a more sophisticated causal thinker.
Claus: “Hey, remember that I agreed that my decision and the contents of Box 1 are actually dependent upon each other, just not causally?”
Eve: “Yes.”
Claus: “Well, I do still agree with that. But I am also still a two-boxer. I’ll explain – would you hand me that paper?”
Claus scribbles a few equations beneath Eve’s diagrams.

Claus: “When you calculated the expected values of one-boxing and two-boxing, you implicitly used Equation (1). Let’s call this equation the “Evidential Decision Algorithm.” You summed over all the possible consequences of your actions, and multiplied the values of each consequence by the conditional probability of that consequence, given the decision.”
Eve: “Yes…”
Claus: “Well, I have a different way to calculate expected values! It’s Equation (2), and I call it the “Causal Decision Algorithm.” I also sum over all possible consequences, but I multiply the value of each consequence by its causal conditional probability, not it’s ordinary conditional probability! And when you calculate the expected value, it turns out to be larger for two-boxing!”
Eve: “Hmm, doesn’t this seem a little arbitrary? Maybe a little ad-hoc?”
Claus: “Not at all! The point of rational decision-making is to choose the decision that causes the best outcomes. What we should be interested in is only the causal links between our decisions and their possible consequences, not the spurious correlations.”
Eve: “Hmm, I can see how that makes sense…”
Claus: “Here, let’s look back at your earlier example about juggling and disease. I agree with what you said that if you observe that you’re a good juggler, you should be worried that you have the disease. But imagine that instead of just observing whether or not you’re a good juggler, you get to decide whether or not to be a good juggler. Say that you can decide to spend many hours training your juggling, and at the end of that process you know that you’ll be a good juggler. Now, according to your decision theory, deciding to train to become a good juggler puts you at a higher risk for having the disease. But that’s ridiculous! We know for sure that your decision to become a good juggler does not make you any more likely to have the disease. Since you’re deciding what actions to take, you should treat your decisions like causal interventions, in which you set the decision variable to one value or another and in the process break all other causal arrows directed at it. And that’s why you should be using the causal conditional probability, not the ordinary conditional probability!”
Eve: “Huh. What you’re saying does have some intuitive appeal. But now I’m starting to think that there is an important difference that we both missed between the juggling example and Newcomb’s problem.”
Eve draws two more diagrams on a new page.

Eve: “In the juggling case, it makes sense to describe your decision to become a good juggler or not as a causal intervention, because this decision is not part of the chain of causes leading from your genes to your juggling ability – it’s a separate cause, independent of whether or not you have the gene. But in Newcomb’s problem, your decision to one-box or two-box exists along the path of the causal arrow from your past character to your current action! The Predictor predicted every part of you, including the part of you that’s thinking about what action you’re going to take. So while modeling your decision as a causal intervention in the juggling example makes sense, doing so in Newcomb’s case is just empirically wrong! Whatever part of your brain ends up deciding to “intervene” and two-box, the Predictor predicted that this would happen! By the nature of the problem, any way in which you attempt to intervene on your decision will inevitably not actually be a causal intervention.”
***
(Tim, a new type of decision theorist, appears in a puff of smoke)
Claus and Eve: “Gasp! Who are you?”
Tim: “I’m Tim, a new type of decision theorist! And I’m here to say that you’re both wrong!”
Claus and Eve: “Gasp!”
Tim: “I’ll explain with a thought experiment. You both know the prisoner’s dilemma, right? Two prisoners each get to make a choice either to cooperate or defect. The best outcome for each one is that they defect and the other prisoner cooperates, the second best outcome is that both cooperate, the second worst is that they both defect, and the worst is that they cooperate and the other prisoner defects. Famously, two rational agents in a prisoner’s dilemma will end up both defecting, because defecting dominates cooperating as a strategy. If the other prisoner defects, you’re better off defecting, and if the other prisoner cooperates, you’re better off defecting. So you should defect.”
Claus and Eve: “Yes, that seems right…”
Tim: “Well, first of all notice that two rational agents end up behaving in a sub-optimal way. They would both be better off if they each cooperated. But apparently, being ‘rational’ in this case entails ending up worse off. This should be a little unusual to you if you think that rational decision-making is about optimizing your outcomes. But now consider this variant: now you are in a prisoner’s dilemma with an exact clone of yourself. You have identical brains, have lived identical lives, and are now making this decision in identical settings. Now what do you do?”
Claus: “Well, on my decision theory, it’s still the case that I can’t causally effect my clone with my decision. This means that when I treat my decision as an intervention, I won’t end up making the probability that my clone defects given that I defect any higher. So defecting still dominates cooperating as a strategy. I defect!”
Eve: “Well, my answer depends on the set-up of the problem. If there’s some common cause that explains why my clone and I are identical (like maybe we were both manufactured in a twin-clone-making factory), then our decisions will be dependent. If I defect, then my clone will certainly defect, and if I cooperate, then my clone will cooperate. So my algorithm will tell me that cooperation maximizes expected utility.”
Tim: “There is no common cause. It’s by an insanely unlikely coincidence that you and your clone happen to have the same brains and to have lived the same lives. Until this moment, the two of you have been completely causally cut off from each other, with no possibility of any type of causal relationship .
Eve: “Okay, then I gotta agree with Claus. With no possible common cause and no causal intermediaries, my decision can’t affect my clone’s decision, causally or statistically. So I’ll defect too.”
Tim: “You’re both wrong. Both of you end up defecting, along with your clones, and everybody is worse off. Look, both of you ended up concluding that your decision and the decision of your clone cannot be correlated, because there are no causal connections to generate that correlation. But you and your clone are completely physically identical. Every atom in your brain is in a functionally identical spot as the atoms in your clone’s brain. Are you determinists?”
Eve: “Well, in quantum mechanics -”
Tim: “Forget quantum mechanics! For the purpose of this thought experiment, you exist in a completely deterministic world, where the same initial conditions lead to the same final conditions in every case, always. You and your clone are in identical initial conditions. So your final condition – that is, your decision about whether to cooperate or defect, must be the same. In the setup as I’ve described it, it is logically impossible that you defect and your clone cooperates, or that you cooperate and your clone defects.”
Claus: “Yes, I think you’re right… but then how do we represent this extra dependence in our diagrams? We can’t draw any causal links connecting the two, so how can we express the logical connection between our actions?”
Tim: “I don’t really care how you represent it in your diagram. Maybe draw a special fancy common cause node with special fancy causal arrows that can’t be broken towards both your decision and your clone’s decision.”

Tim: “The point is: there are really only two possible worlds. In World 1, you defect and your clone defects. In World 2, you cooperate and your clone cooperates. Which world would you rather be in?”
Claus and Eve: “World 2.”
Tim: “Good! So you’ll both cooperate. Now, what if the clone is not exactly identical to you? Let’s say that your clone only ends up doing the same thing as you 99.999% of the time. Now what do you do?”
Claus: “Well, if it’s no longer logically impossible for my clone to behave differently from me, then maybe I should defect again?”
Tim: “Do you really want a decision theory that has a discontinuous jump in your behavior from a 99.999% chance to a 100% chance? I mean, I’ve told you that the chance that the clone gives a different answer than your answer is .001%! Rational agents should take into account all of their information, not only selective pieces of it. Either you ignore this information and end up worse off, or you take it into account and win!”
Eve: “Okay, yes, it seems reasonable to still expect a 99.999% chance of identical choices in this case. So we should cooperate again. But what does all of this have to do with Newcomb’s problem?”
Tim: “It relates to your answers to Newcomb’s problem in two ways. First, it shows that both of your decision algorithms are wrong! They are failing to take into account that extra logical dependency between actions and consequences that we drew with fancy arrows. And second, Newcomb’s problem is virtually identical to the prisoner’s dilemma with a clone!”
Eve and Claus: “Huh?”
Tim: “Here, let’s modify the prisoner’s dilemma in the following way: If you both cooperate, then you get one million dollars. If you cooperate and your clone defects, you get $0. If you defect and your clone cooperates, you get $1,010,000. And if you both defect, then you get $10,000. Now “cooperating” is the same as one-boxing, and “defecting” is the same as two-boxing!”
Eve: “But hold on, isn’t the logical dependency between my actions and my clone’s actions not carried over to the prisoner’s dilemma? Like, it’s not logically impossible that I one-box and the box has a million dollars in it, right?”
Tim: “It is with a perfect Predictor, yes! Remember, the Predictor works by creating a perfect simulation of you and seeing what it does. This means that your decision to one-box or to two-box is logically dependent on the Predictor’s prediction of what you do (and thus the contents of the box) in the exact same way that your decision to cooperate is logically dependent on your clone’s decision to one-box!”

Claus: “Yes, I see. So with a perfect Predictor, there are really only two worlds to consider: one in which I one-box and get a million dollars, and another in which I two-box and get just $10,000. And of course I prefer the first, so I should one-box.”
Tim: “Exactly! And if the Predictor is not perfectly accurate, and is only right 99.999% of the time…”
Eve: “Well, then there’s still only a .001% chance that I two-box and get an extra million bucks. So, I’m still much better off if I one-box than if I two-box.”
Tim: “Yep! It sounds like we’re all on the same page then. There’s a logical dependence between your action and the contents of the box that you are rationally required to take into account, and when you do take it into account, you end up seeing that one-boxing is the rational action.”
***
The decision theory that “Tim” is using is called timeless decision theory. It’s also been variously called functional decision theory, logical decision theory, and updateless decision theory.
Timeless decision theory ends up better off in Newcomb-like problems, invariably walking away with 1 million dollars instead of $10,000. It also does better than evidential decision theory (Eve’s theory) and causal decision theory (Claus’s theory) at prisoner’s-dilemmas-with-a-clone. These are fairly contrived problems, and it’d be easy for Eve or Claus to just deny that these problems have any real-world application.
But timeless decision theorists also cooperate with each other in ordinary prisoner’s dilemmas. They have a much easier time with coordination problems in general. They do better in bargaining problems. And they can’t be blackmailed in a large general class of situations. It’s harder to write these results off as strange quirks that don’t relate to real life.
A society of TDTs wouldn’t be plagued with doubts about the rationality of voting, wouldn’t find themselves stuck in as many sub-optimal Nash equilibria, and would look around and see a lot fewer civilizational inadequacies and low-hanging policy fruit than we currently have. This is what’s most interesting to me about TDT – that it gives a foundation for rational decision-making that seems like it has potential for solving real civilizational problems.