The truly weirdest consequences of anthropic reasoning come from a cluster of thought experiments I’ll call the Adam and Eve thought experiments. These thought experiments all involve agents leveraging anthropic probabilities in their favor in bizarre ways that appear as if they have picked up superpowers. We’ll get there by means of a simple thought experiment designed to pump your intuitions in favor of our eventual destination.
In front of you is a jar. This jar contains either 10 balls or 100 balls. The balls are numbered in order from 1 to either 10 or 100. You reach in and pull out a ball, and find that it is numbered ‘7’. Which is now more likely: that the jar contains 10 balls or that it contains 100 balls? (Suppose that you were initially evenly split between the two possibilities.)
The answer should be fairly intuitive: It is now more likely that the jar contains ten balls.
If the jar contains 10 balls, you had a 1/10 chance of drawing #7. On the other hand, if the jar contains 100 balls you had a 1/100 chance of drawing #7. This corresponds to a likelihood ratio of 10:1 in favor of the jar having ten balls. Since your prior odds in the two possibilities were 1:1, your posterior odds should be 10:1. Thus the posterior probability of 10 balls is 10/11, or roughly 91%.
Now, let’s apply this same reasoning to something more personal. Imagine two different theories of human history. In the first theory, there are 200 billion people that will ever live. In the second, there are 2 trillion people that will ever live. We want to update on the anthropic evidence of our birth order in the history of humanity.
There have been roughly 100 billion people that ever lived, so our birth order is about 100 billion. The self-sampling assumption says that this is just like drawing a ball from a jar that contains either 200 billion numbered balls or 2 trillion numbered balls, and finding that the ball you drew is numbered 100 billion.
The likelihood ratio you get is 10:1, so your posterior odds are ten times more favorable for the “200 billion total humans” theory than for the “2 trillion total humans”. If you were initially evenly split between these two, then noticing your birth order should bring you to a 91% confidence in the ‘extinction sooner’ hypothesis.
This line of reasoning is called the Doomsday argument, and it leads down into quite a rabbit hole. I don’t want to explore that rabbit hole quite yet. For the moment, let’s just note that ordinary Bayesian updating on your own birth order favors theories in which there are less total humans to ever live. The strength of this update depends linearly on the number of humans being considered: comparing Theory 1 (100 people) to Theory 2 (100 trillion people) gives a likelihood ratio of one trillion in favor of Theory 1 over Theory 2. So in general, it appears that we should be extremely confident that extremely optimistic pictures of a long future for humanity are wrong. The more optimistic, the less likely.
With this in mind, let’s go on to Adam and Eve.
Suspend your disbelief for a moment and imagine that there was at some point just two humans on the face of the Earth – Adam and Eve. This fateful couple gave rise to all of human history, and we are all their descendants. Now, imagine yourself in their perspective.
From this perspective, there are two possible futures that might unfold. In one of them, the two original humans procreate and start the chain of actions leading to the rest of human history. In another, the two original humans refuse to procreate, thus preventing human history from happening. For the sake of this thought experiment, let’s imagine that Adam and Eve know that these are the only two possibilities (that is, suppose that there’s no scenario in which they procreate and have kids, but then those kids die off or somehow else prevent the occurence of history as we know it).
By the above reasoning, Adam and Eve should expect that the second of these is enormously more likely than the first. After all, if they never procreate and eventually just die off, then their birth orders are 1 and 2 out of a grand total of 2. If they do procreate, though, then their birth orders are 1 and 2 out of at least 100 billion. This is 50 billion times less likely than the alternative!
Now, the unusual bit of this comes from the fact that it seems like Adam and Eve have control over whether or not they procreate. For the sake of the thought experiment, imagine that they are both fertile, and they can take actions that will certainly result in pregnancy. Also assume that if they don’t procreate, Eve won’t get accidentally pregnant by some unusual means.
This control over their procreation, coupled with the improbability of their procreation, allows them to wield apparently magical powers. For instance, Adam is feeling hungry and needs to go out and hunt. He makes a firm commitment with Eve: “I shall wait for an hour for a healthy young deer to die in front of our cave entrance. If no such deer dies, then we will procreate and have children, leading to the rest of human history. If so, then we will not procreate, and guarantee that we don’t have kids for the rest of our lives.”
Now, there’s some low prior on a healthy young deer just dying right in front of them. Let’s say it’s something like 1 in a billion. Thus our prior odds are 1:1,000,000,000 against Adam and Eve getting their easy meal. But now when we take into account the anthropic update, it becomes 100 billion times more likely that the deer does die, because this outcome has been tied to the nonexistence of the rest of human history. The likelihood ratio here is 100,000,000,000:1. So our posterior odds will be 100:1 in favor of the deer falling dead, just as the two anthropic reasoners desire! This is a 99% chance of a free meal!
This is super weird. It sure looks like Adam is able to exercise telekinetic powers to make deer drop dead in front of him at will. Clearly something has gone horribly wrong here! But the argument appears to be totally sound, conditional on the acceptance of the principles we started off with. All that is required is that we allow ourselves to update on evidence of the form “I am the Nth human being to have been born.” (as well as the very unusual setup of the thought experiment).
This setup is so artificial that it can be easy to just dismiss it as not worth considering. But now I’ll give another thought experiment of the same form that is much less outlandish, so much so that it may actually one day occur!
Here goes…
The year is 2100 AD, and independent, autonomous countries are no more. The entire planet is governed by a single planetary government which has an incredibly tight grip on everything that happens under their reign. Anything that this World Government dictates is guaranteed to be carried out, and there is no serious chance that it will lose power. Technology has advanced to the point that colonization of other planets is easily feasible. In fact, the World Government has a carefully laid out plan for colonization of the entire galaxy. The ships have been built and are ready for deployment, the target planets have been identified, and at the beckoning of the World Government galactic colonization can begin, sure to lead to a vast sprawling Galactic Empire of humanity.
Now, the World Government is keeping these plans at a standstill for a very particular reason: they are anthropic reasoners! They recognize that by firmly committing to either carry out the colonization or not, they are able to wield enormous anthropic superpowers and do things that would otherwise be completely impossible.
For instance, a few years ago scientists detected a deadly cosmic burst from the Sun headed towards Earth. Scientists warned that given the angle of the blast, there was only a 1% chance that it would miss Earth. In addition, they assessed that if the blast hit Earth, it would surely result in the extinction of everybody on the planet.
The World Government made the following plans: They launched tens of millions of their colonizing ships and had them wait for further instructions in a region safe from the cosmic rays. Then, the World Government instructed that if the cosmic rays hit Earth, the ships commence galactic colonization. Otherwise, if the cosmic rays missed Earth, the ships should return to Earth’s surface and abandon the colonization plans.
Why these plans? Well, because by tying the outcome of the cosmic ray collision to the future history of humanity, they leverage the enormous improbability of their early birth order in the history of humanity given galactic colonization in their favor! If a Galactic Empire future contains 1 billion times more total humans than a Earth future, then the prior odds of 1:100 in favor of the cosmic rays hitting Earth get multiplied by a likelihood ratio of 1,000,000,000:1 in favor of the cosmic rays missing Earth. The result is posterior odds of 10,000,000:1, or a posterior confidence of 99.99999% that the cosmic rays will miss!
In short, by wielding tight control over decisions about the future existence of enormous numbers of humans, the World Government is able to exercise apparently magical abilities. Cosmic rays headed their way? No problem, just threaten the universe with a firm commitment to send out their ships to colonize the galaxy. The improbability of this result makes the cosmic rays “swerve”, keeping the people of Earth safe.
The reasoning employed in this story should be very disturbing to you. The challenge is to explain how to get out of its conclusion.
One possibility is to deny anthropic reasoning. But then we also have to deny all the ordinary everyday cases of anthropic reasoning that seem thoroughly reasonable (and necessary for rationality). (See here.)
We could deny that updating on our indexical evidence of our place in history actually has the effects that I’ve said it has. But this seems wrong as well. The calculation done here is the exact type of calculation we’ve done in less controversial scenarios.
We could accept the conclusions. But that seems out of the question. Probabilities are supposed to be a useful tool we apply to make sense of a complicated world. In the end, the world is not run by probabilities, but by physics. And physics doesn’t have clauses that permit cosmic rays to swerve out of the way for clever humans with plans of conquering the stars.
There’s actually one other way out. But I’m not super fond of it. This way out is to craft a new anthropic principle, specifically for the purpose of counteracting the anthropic considerations in cases like these. The name of this anthropic principle is the Self-Indication Assumption. This principle says that theories that predict more observers like you become more likely in virtue of this fact.
Self Indication Assumption: The prior probability of a theory is proportional to the number of observers like you it predicts will exist.
Suppose we have narrowed it down to two possible theories of the universe. Theory 1 predicts that there will be 1 million observers like you. Theory 2 predicts that there will be 1 billion observers like you. The self indication assumption says that before we assess the empirical evidence for these two theories, we should place priors in them that make Theory 2 one thousand times more likely than Theory 1.
It’s important to note that this principle is not about updating on evidence. It’s about setting of priors. If we update on our existence, this favors neither Theory 1 nor Theory 2. Both predict the existence of an observer like us with 100% probability, so the likelihood ratio is 1/1, and no update is performed.
Instead, we can think of the self indication assumption as saying the following: Look at all the possible observers that you could be, in all theories of the world. You should distribute your priors evenly across all these possible observers. Then for each theory you’re interested in, just compile these priors to determine its prior probability.
When I first heard of this principle, my reaction was “…WHY???” For whatever reason, it just made no sense to me as a procedure for setting priors. But it must be said that this principle beautifully solves all of the problems I’ve brought up in this post. Remember that the improbability being wielded in every case was the improbability of existing in a world where there are many other future observers like you. The self indication assumption tilts our priors in these worlds exactly in the opposite direction, perfectly canceling out the anthropic update.
So, for instance, let’s take the very first thought experiment in this post. Compare a theory of the future in which 200 billion people exist total to a theory in which 2 trillion people exist total. We said that our birth order gives us a likelihood ratio of 10:1 in favor of the first theory. But now the self indication assumption tells us that our prior odds should be 1:10, in favor of the second theory! Putting these two anthropic principles together, we get 1:1 odds. The two theories are equally likely! This seems refreshingly sane.
As far as I currently know, this is the only way out of the absurd results of the thought experiments I’ve presented in this post. The self-indication assumption seems really weird and unjustified to me, but I think a really good argument for it is just that it restores sanity to rationality in the face of anthropic craziness.
Some final notes:
Applying the self-indication assumption to the sleeping beauty problem (discussed here) makes you a thirder instead of a halfer. I previously defended the halfer position on the grounds that (1) the prior on Heads and Tails should be 50/50 and (2) Sleeping Beauty has no information to update on. The self-indication assumption leads to the denial of (1). Since there are different numbers of observers like you if the coin lands Heads versus if it lands Tails, the prior odds should not be 1:1. Instead they should be 2:1 in favor of Heads, reflecting the fact that there are two possible “you”s if the coin lands Heads, and only one if the coin lands Tails.
In addition, while I’ve presented the thought experiments that show the positives of the self-indication assumption, there are cases where the self-indication gives very bizarre answers. I won’t go into them now, but I do want to plant a flag here to indicate that the self-indication assumption is by no means uncontroversial.
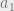


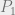
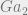


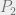
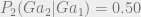
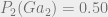
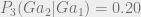
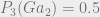
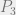
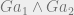
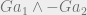
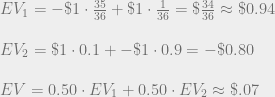

 $2 gain for saying Heads on both days + 50% chance of Tails
$2 gain for saying Heads on both days + 50% chance of Tails 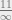 smaller than
smaller than 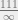 ?)
?)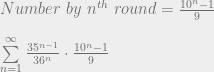
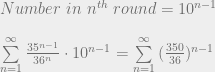
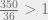 , this sum diverges. So on average there are an infinite number of people on the last round (even though the last round always contains a finite number of people). Correspondingly, the expected number of people kidnapped is infinite.
, this sum diverges. So on average there are an infinite number of people on the last round (even though the last round always contains a finite number of people). Correspondingly, the expected number of people kidnapped is infinite.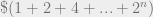 and gained
and gained 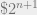 . This is a net gain of $1. In other words, no matter what the odds they are betting on, this betting system guarantees a gain of $1 with probability 100%.
. This is a net gain of $1. In other words, no matter what the odds they are betting on, this betting system guarantees a gain of $1 with probability 100%. , all that is required is that the number of people by the Nth round be less than
, all that is required is that the number of people by the Nth round be less than 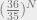 . Then the anthropic calculation should give a different answer from the non-anthropic calculation, and we can place the chance of escape in between these two. Now we have a finite expected number of captives, but a reversal in decision depending on whether you update on anthropic evidence or not. Perhaps I’ll explore this more in future posts.
. Then the anthropic calculation should give a different answer from the non-anthropic calculation, and we can place the chance of escape in between these two. Now we have a finite expected number of captives, but a reversal in decision depending on whether you update on anthropic evidence or not. Perhaps I’ll explore this more in future posts.
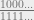 is .9). This means that no matter what probabilities we plug in there, the average fraction of people will be greater than 90%. (If the possible values of a quantity are all greater than 90%, then the average value of this quantity cannot possibly be less than 90%.)
is .9). This means that no matter what probabilities we plug in there, the average fraction of people will be greater than 90%. (If the possible values of a quantity are all greater than 90%, then the average value of this quantity cannot possibly be less than 90%.)
